 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAKTAG: Two-phase learning method for hybrid statistical/rule-based part-of-speech disambiguation
Paper and Code
May 28, 1995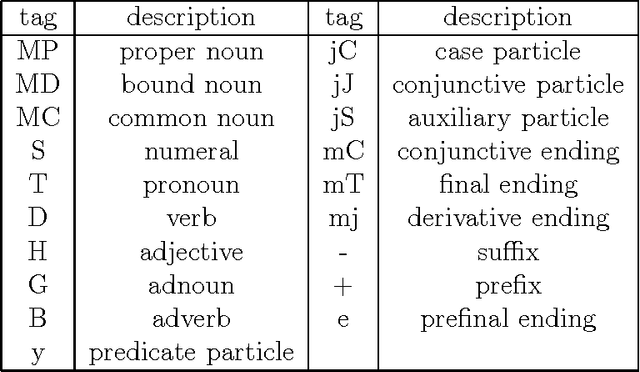



Both statistical and rule-based approaches to part-of-speech (POS) disambiguation have their own advantages and limitations. Especially for Korean, the narrow windows provided by hidden markov model (HMM) cannot cover the necessary lexical and long-distance dependencies for POS disambiguation. On the other hand, the rule-based approaches are not accurate and flexible to new tag-sets and languages. In this regard, the statistical/rule-based hybrid method that can take advantages of both approaches is called for the robust and flexible POS disambiguation. We present one of such method, that is, a two-phase learning architecture for the hybrid statistical/rule-based POS disambiguation, especially for Korean. In this method, the statistical learning of morphological tagging is error-corrected by the rule-based learning of Brill [1992] style tagger. We also design the hierarchical and flexible Korean tag-set to cope with the multiple tagging applications, each of which requires different tag-set. Our experiments show that the two-phase learning method can overcome the undesirable features of solely HMM-based or solely rule-based tagging, especially for morphologically complex Korean.