 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBring More Attention to Syntactic Symmetry for Automatic Postediting of High-Quality Machine Translations
May 17, 2023Automatic postediting (APE) is an automated process to refine a given machine translation (MT). Recent findings present that existing APE systems are not good at handling high-quality MTs even for a language pair with abundant data resources, English$\unicode{x2013}$German: the better the given MT is, the harder it is to decide what parts to edit and how to fix these errors. One possible solution to this problem is to instill deeper knowledge about the target language into the model. Thus, we propose a linguistically motivated method of regularization that is expected to enhance APE models' understanding of the target language: a loss function that encourages symmetric self-attention on the given MT. Our analysis of experimental results demonstrates that the proposed method helps improving the state-of-the-art architecture's APE quality for high-quality MTs.
Towards Semi-Supervised Learning of Automatic Post-Editing: Data-Synthesis by Infilling Mask with Erroneous Tokens
Apr 08, 2022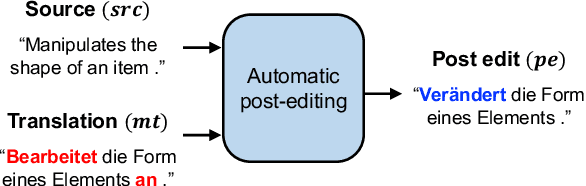
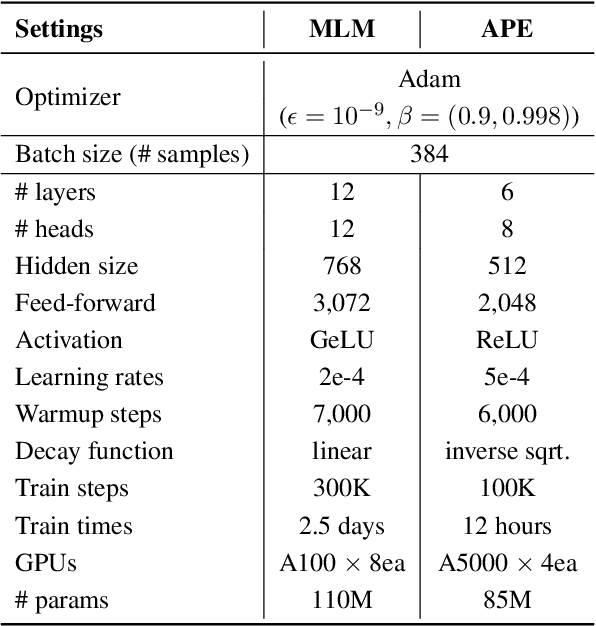
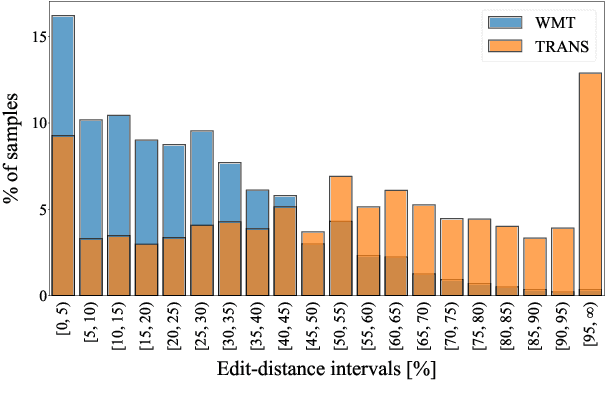
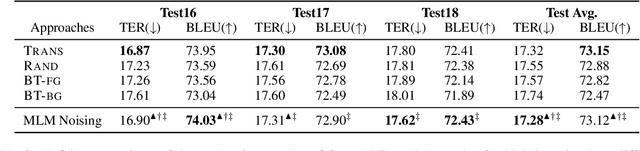
Semi-supervised learning that leverages synthetic training data has been widely adopted in the field of Automatic post-editing (APE) to overcome the lack of human-annotated training data. In that context, data-synthesis methods to create high-quality synthetic data have also received much attention. Considering that APE takes machine-translation outputs containing translation errors as input, we propose a noising-based data-synthesis method that uses a mask language model to create noisy texts through substituting masked tokens with erroneous tokens, yet following the error-quantity statistics appearing in genuine APE data. In addition, we propose corpus interleaving, which is to combine two separate synthetic data by taking only advantageous samples, to further enhance the quality of the synthetic data created with our noising method. Experimental results reveal that using the synthetic data created with our approach results in significant improvements in APE performance upon using other synthetic data created with different existing data-synthesis methods.
mcBERT: Momentum Contrastive Learning with BERT for Zero-Shot Slot Filling
Mar 24, 2022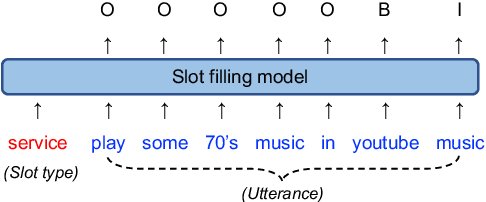
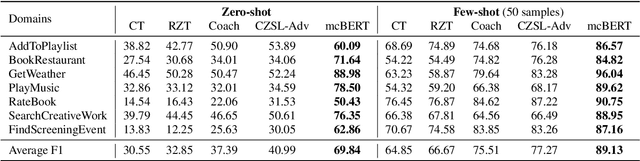
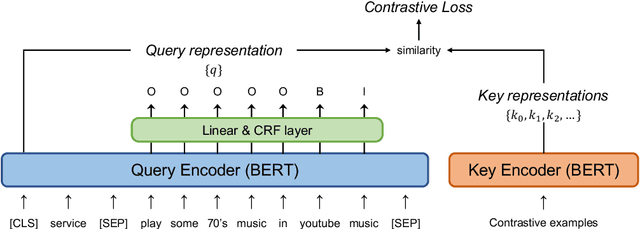
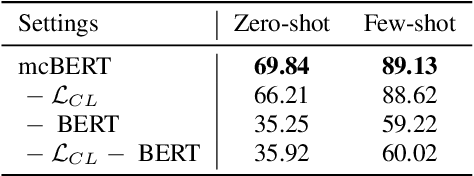
Zero-shot slot filling has received considerable attention to cope with the problem of limited available data for the target domain. One of the important factors in zero-shot learning is to make the model learn generalized and reliable representations. For this purpose, we present mcBERT, which stands for momentum contrastive learning with BERT, to develop a robust zero-shot slot filling model. mcBERT uses BERT to initialize the two encoders, the query encoder and key encoder, and is trained by applying momentum contrastive learning. Our experimental results on the SNIPS benchmark show that mcBERT substantially outperforms the previous models, recording a new state-of-the-art. Besides, we also show that each component composing mcBERT contributes to the performance improvement.
Modeling Inter-Speaker Relationship in XLNet for Contextual Spoken Language Understanding
Oct 28, 2019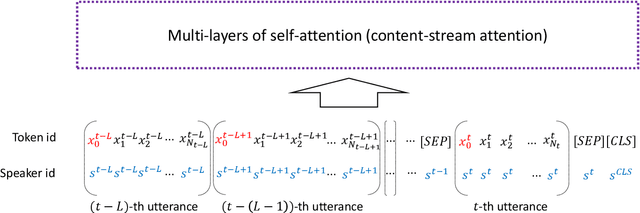
We propose two methods to capture relevant history information in a multi-turn dialogue by modeling inter-speaker relationship for spoken language understanding (SLU). Our methods are tailored for and therefore compatible with XLNet, which is a state-of-the-art pretrained model, so we verified our models built on the top of XLNet. In our experiments, all models achieved higher accuracy than state-of-the-art contextual SLU models on two benchmark datasets. Analysis on the results demonstrated that the proposed methods are effective to improve SLU accuracy of XLNet. These methods to identify important dialogue history will be useful to alleviate ambiguity in SLU of the current utterance.
Transformer-based Automatic Post-Editing with a Context-Aware Encoding Approach for Multi-Source Inputs
Aug 15, 2019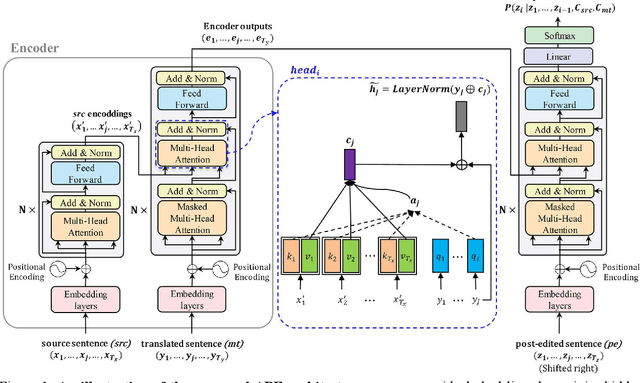
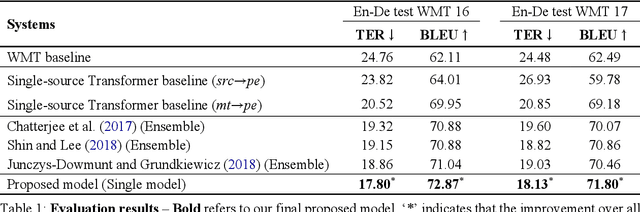
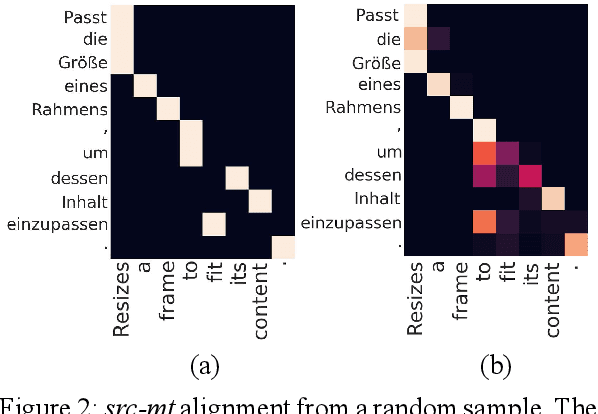
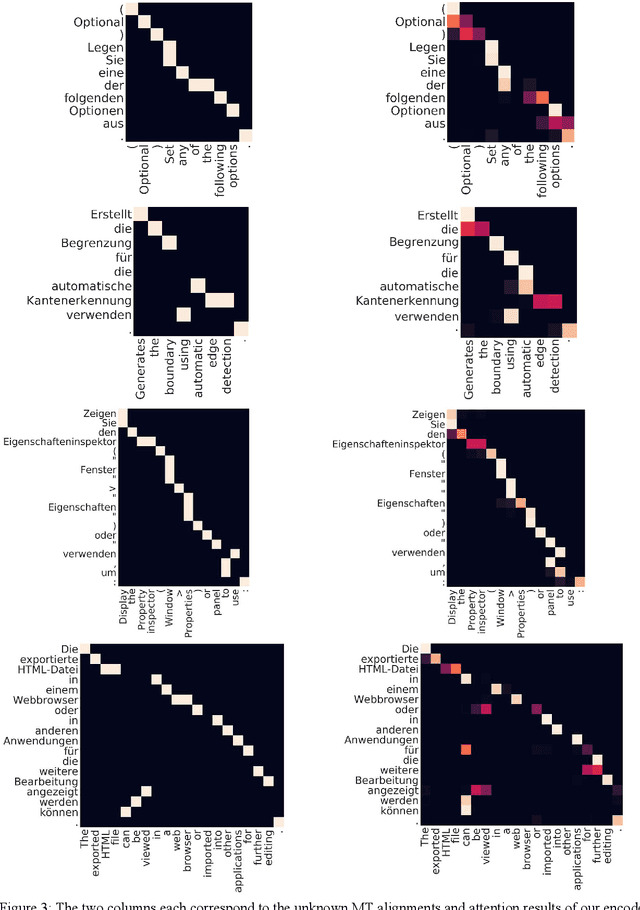
Recent approaches to the Automatic Post-Editing (APE) research have shown that better results are obtained by multi-source models, which jointly encode both source (src) and machine translation output (mt) to produce post-edited sentence (pe). Along this trend, we present a new multi-source APE model based on the Transformer. To construct effective joint representations, our model internally learns to incorporate src context into mt representation. With this approach, we achieve a significant improvement over baseline systems, as well as the state-of-the-art multi-source APE model. Moreover, to demonstrate the capability of our model to incorporate src context, we show that the word alignment of the unknown MT system is successfully captured in our encoding results.
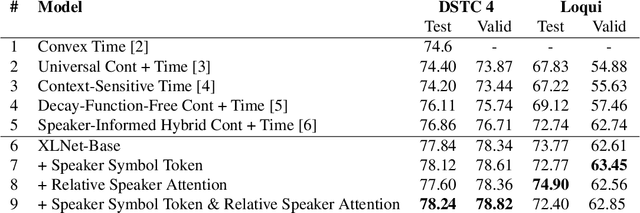
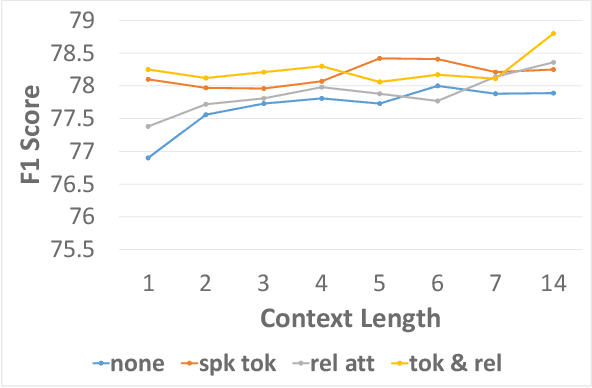
Decay-Function-Free Time-Aware Attention to Context and Speaker Indicator for Spoken Language Understanding
Mar 29, 2019
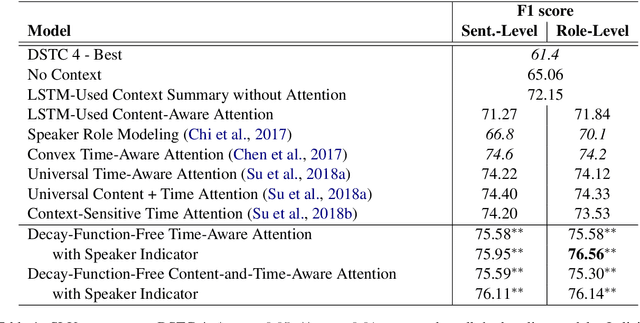
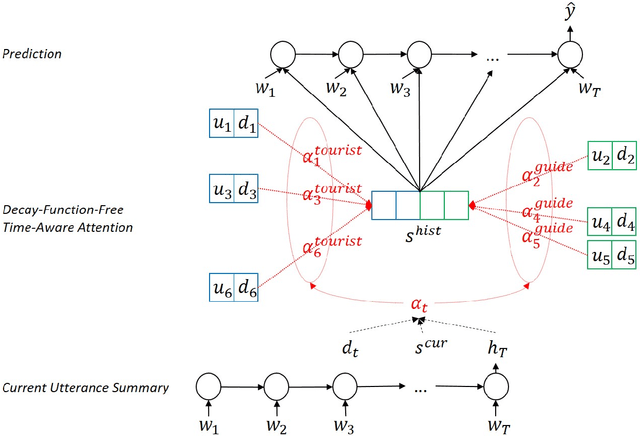
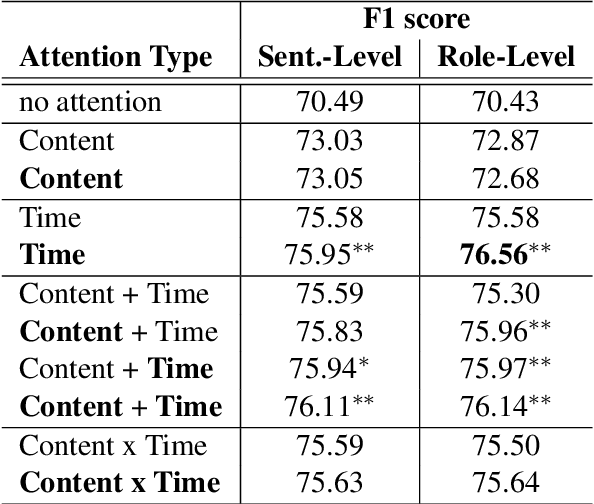
To capture salient contextual information for spoken language understanding (SLU) of a dialogue, we propose time-aware models that automatically learn the latent time-decay function of the history without a manual time-decay function. We also propose a method to identify and label the current speaker to improve the SLU accuracy. In experiments on the benchmark dataset used in Dialog State Tracking Challenge 4, the proposed models achieved significantly higher F1 scores than the state-of-the-art contextual models. Finally, we analyze the effectiveness of the introduced models in detail. The analysis demonstrates that the proposed methods were effective to improve SLU accuracy individually.
Self-Attention-Based Message-Relevant Response Generation for Neural Conversation Model
May 23, 2018
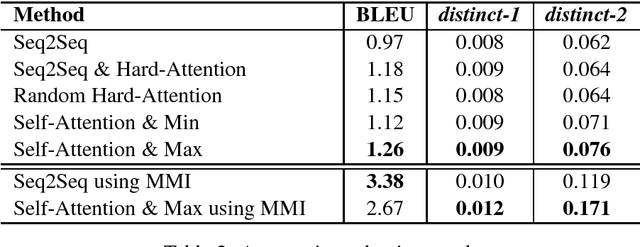
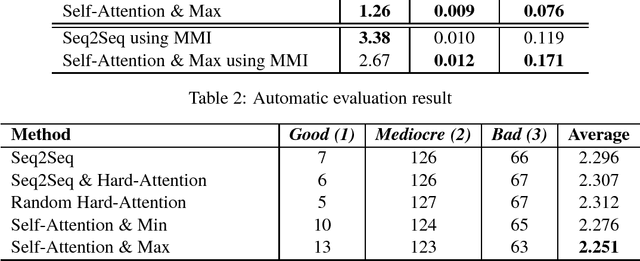
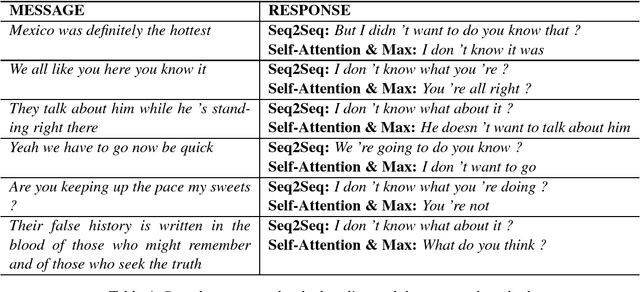
Using a sequence-to-sequence framework, many neural conversation models for chit-chat succeed in naturalness of the response. Nevertheless, the neural conversation models tend to give generic responses which are not specific to given messages, and it still remains as a challenge. To alleviate the tendency, we propose a method to promote message-relevant and diverse responses for neural conversation model by using self-attention, which is time-efficient as well as effective. Furthermore, we present an investigation of why and how effective self-attention is in deep comparison with the standard dialogue generation. The experiment results show that the proposed method improves the standard dialogue generation in various evaluation metrics.
Multiple Range-Restricted Bidirectional Gated Recurrent Units with Attention for Relation Classification
Nov 01, 2017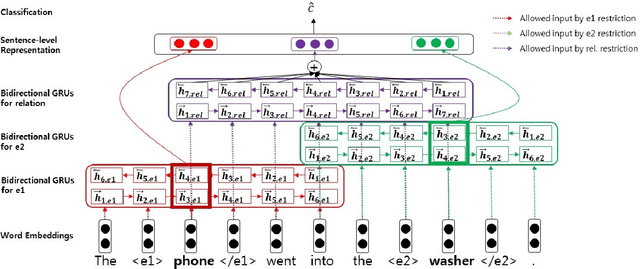
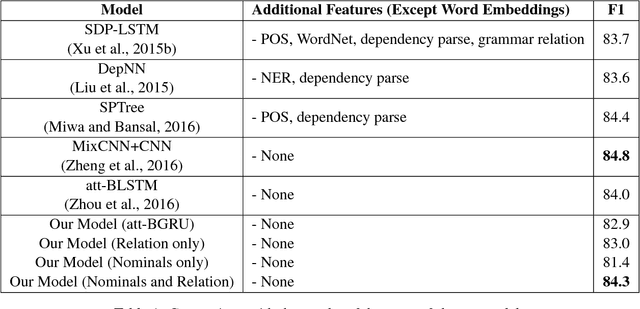
Most of neural approaches to relation classification have focused on finding short patterns that represent the semantic relation using Convolutional Neural Networks (CNNs) and those approaches have generally achieved better performances than using Recurrent Neural Networks (RNNs). In a similar intuition to the CNN models, we propose a novel RNN-based model that strongly focuses on only important parts of a sentence using multiple range-restricted bidirectional layers and attention for relation classification. Experimental results on the SemEval-2010 relation classification task show that our model is comparable to the state-of-the-art CNN-based and RNN-based models that use additional linguistic information.
Improving Term Frequency Normalization for Multi-topical Documents, and Application to Language Modeling Approaches
Feb 08, 2015
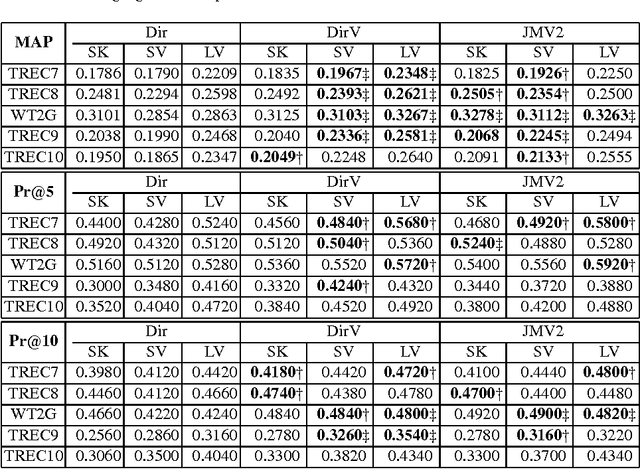
Term frequency normalization is a serious issue since lengths of documents are various. Generally, documents become long due to two different reasons - verbosity and multi-topicality. First, verbosity means that the same topic is repeatedly mentioned by terms related to the topic, so that term frequency is more increased than the well-summarized one. Second, multi-topicality indicates that a document has a broad discussion of multi-topics, rather than single topic. Although these document characteristics should be differently handled, all previous methods of term frequency normalization have ignored these differences and have used a simplified length-driven approach which decreases the term frequency by only the length of a document, causing an unreasonable penalization. To attack this problem, we propose a novel TF normalization method which is a type of partially-axiomatic approach. We first formulate two formal constraints that the retrieval model should satisfy for documents having verbose and multi-topicality characteristic, respectively. Then, we modify language modeling approaches to better satisfy these two constraints, and derive novel smoothing methods. Experimental results show that the proposed method increases significantly the precision for keyword queries, and substantially improves MAP (Mean Average Precision) for verbose queries.
* 8 pages, conference paper, published in ECIR '08
Unlimited Vocabulary Grapheme to Phoneme Conversion for Korean TTS
Jun 10, 1998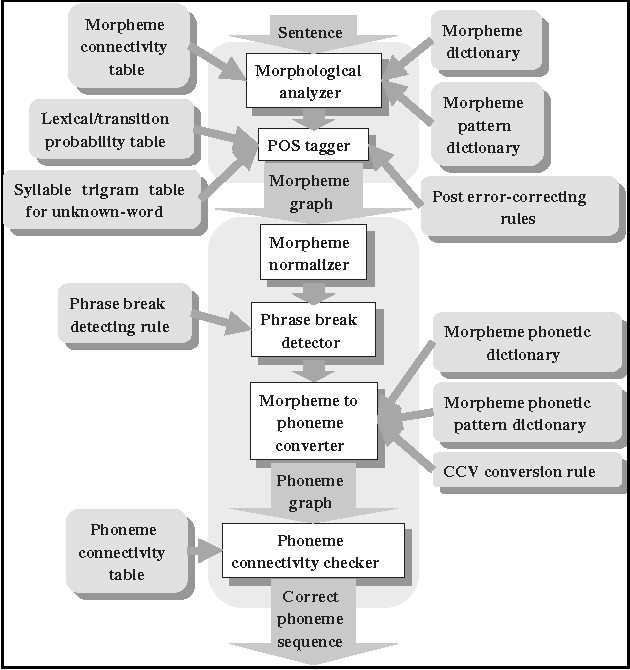

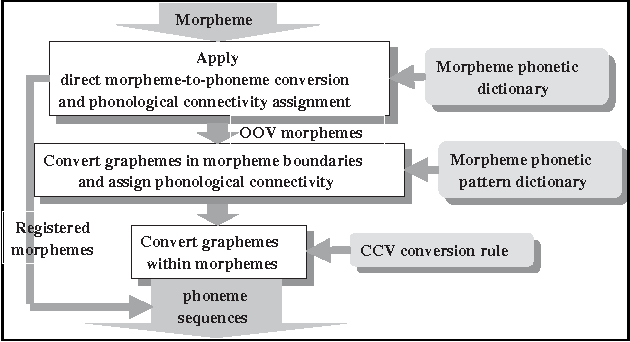

This paper describes a grapheme-to-phoneme conversion method using phoneme connectivity and CCV conversion rules. The method consists of mainly four modules including morpheme normalization, phrase-break detection, morpheme to phoneme conversion and phoneme connectivity check. The morpheme normalization is to replace non-Korean symbols into standard Korean graphemes. The phrase-break detector assigns phrase breaks using part-of-speech (POS) information. In the morpheme-to-phoneme conversion module, each morpheme in the phrase is converted into phonetic patterns by looking up the morpheme phonetic pattern dictionary which contains candidate phonological changes in boundaries of the morphemes. Graphemes within a morpheme are grouped into CCV patterns and converted into phonemes by the CCV conversion rules. The phoneme connectivity table supports grammaticality checking of the adjacent two phonetic morphemes. In the experiments with a corpus of 4,973 sentences, we achieved 99.9% of the grapheme-to-phoneme conversion performance and 97.5% of the sentence conversion performance. The full Korean TTS system is now being implemented using this conversion method.