 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Semi-Supervised Learning of Automatic Post-Editing: Data-Synthesis by Infilling Mask with Erroneous Tokens
Apr 08, 2022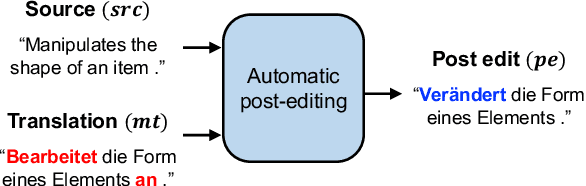
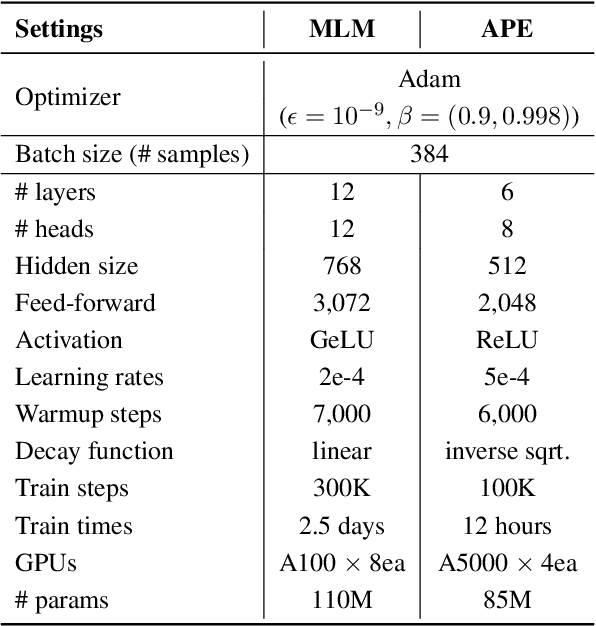
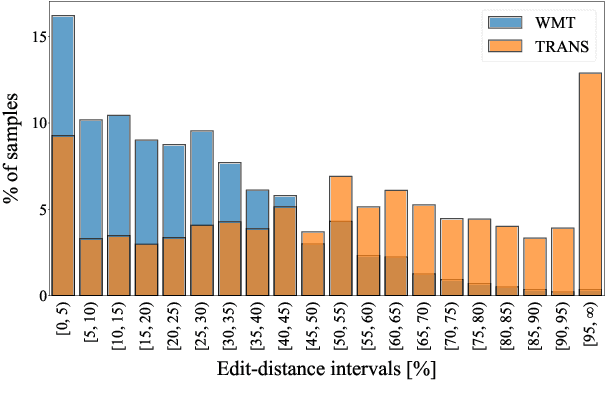
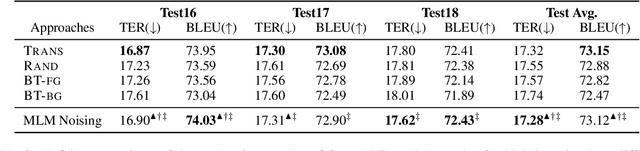
Semi-supervised learning that leverages synthetic training data has been widely adopted in the field of Automatic post-editing (APE) to overcome the lack of human-annotated training data. In that context, data-synthesis methods to create high-quality synthetic data have also received much attention. Considering that APE takes machine-translation outputs containing translation errors as input, we propose a noising-based data-synthesis method that uses a mask language model to create noisy texts through substituting masked tokens with erroneous tokens, yet following the error-quantity statistics appearing in genuine APE data. In addition, we propose corpus interleaving, which is to combine two separate synthetic data by taking only advantageous samples, to further enhance the quality of the synthetic data created with our noising method. Experimental results reveal that using the synthetic data created with our approach results in significant improvements in APE performance upon using other synthetic data created with different existing data-synthesis methods.
mcBERT: Momentum Contrastive Learning with BERT for Zero-Shot Slot Filling
Mar 24, 2022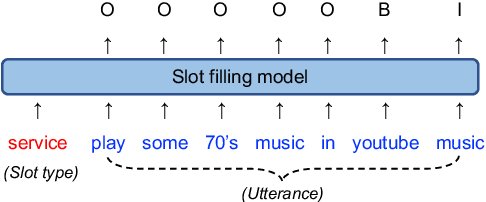
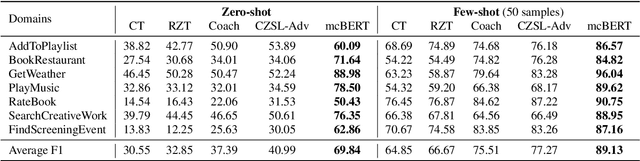
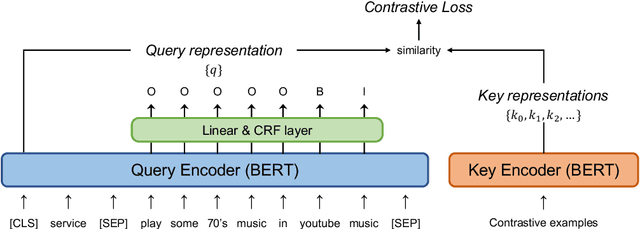
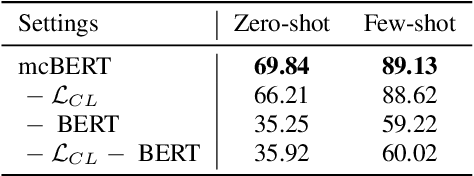
Zero-shot slot filling has received considerable attention to cope with the problem of limited available data for the target domain. One of the important factors in zero-shot learning is to make the model learn generalized and reliable representations. For this purpose, we present mcBERT, which stands for momentum contrastive learning with BERT, to develop a robust zero-shot slot filling model. mcBERT uses BERT to initialize the two encoders, the query encoder and key encoder, and is trained by applying momentum contrastive learning. Our experimental results on the SNIPS benchmark show that mcBERT substantially outperforms the previous models, recording a new state-of-the-art. Besides, we also show that each component composing mcBERT contributes to the performance improvement.
Transformer-based Automatic Post-Editing with a Context-Aware Encoding Approach for Multi-Source Inputs
Aug 15, 2019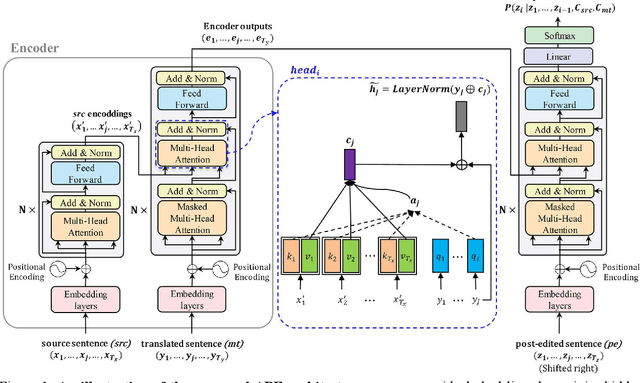
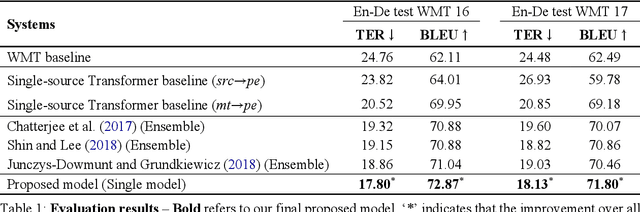
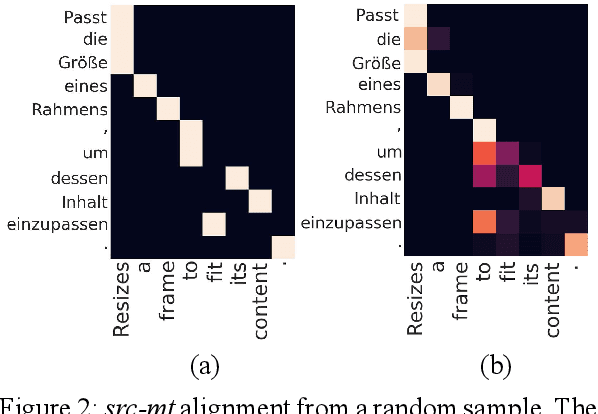
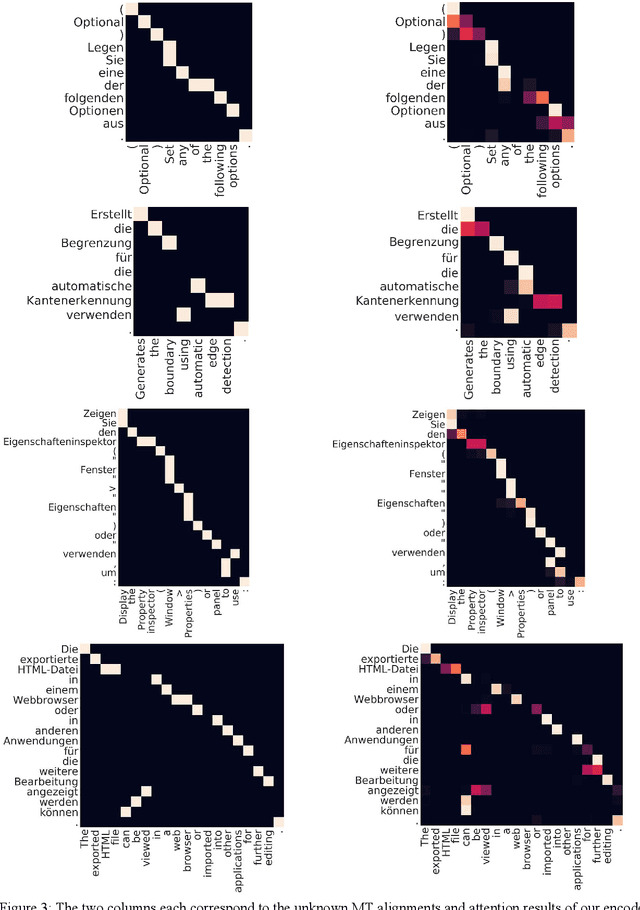
Recent approaches to the Automatic Post-Editing (APE) research have shown that better results are obtained by multi-source models, which jointly encode both source (src) and machine translation output (mt) to produce post-edited sentence (pe). Along this trend, we present a new multi-source APE model based on the Transformer. To construct effective joint representations, our model internally learns to incorporate src context into mt representation. With this approach, we achieve a significant improvement over baseline systems, as well as the state-of-the-art multi-source APE model. Moreover, to demonstrate the capability of our model to incorporate src context, we show that the word alignment of the unknown MT system is successfully captured in our encoding results.