 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising Table-Text Retrieval for Open-Domain Question Answering
Mar 26, 2024


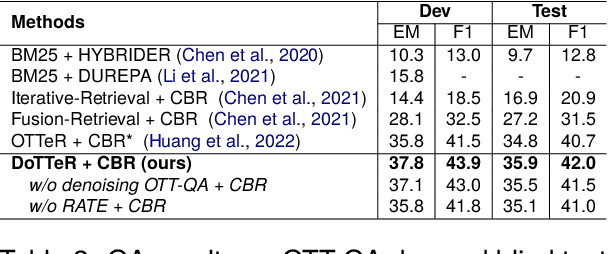
In table-text open-domain question answering, a retriever system retrieves relevant evidence from tables and text to answer questions. Previous studies in table-text open-domain question answering have two common challenges: firstly, their retrievers can be affected by false-positive labels in training datasets; secondly, they may struggle to provide appropriate evidence for questions that require reasoning across the table. To address these issues, we propose Denoised Table-Text Retriever (DoTTeR). Our approach involves utilizing a denoised training dataset with fewer false positive labels by discarding instances with lower question-relevance scores measured through a false positive detection model. Subsequently, we integrate table-level ranking information into the retriever to assist in finding evidence for questions that demand reasoning across the table. To encode this ranking information, we fine-tune a rank-aware column encoder to identify minimum and maximum values within a column. Experimental results demonstrate that DoTTeR significantly outperforms strong baselines on both retrieval recall and downstream QA tasks. Our code is available at https://github.com/deokhk/DoTTeR.
Bring More Attention to Syntactic Symmetry for Automatic Postediting of High-Quality Machine Translations
May 17, 2023Automatic postediting (APE) is an automated process to refine a given machine translation (MT). Recent findings present that existing APE systems are not good at handling high-quality MTs even for a language pair with abundant data resources, English$\unicode{x2013}$German: the better the given MT is, the harder it is to decide what parts to edit and how to fix these errors. One possible solution to this problem is to instill deeper knowledge about the target language into the model. Thus, we propose a linguistically motivated method of regularization that is expected to enhance APE models' understanding of the target language: a loss function that encourages symmetric self-attention on the given MT. Our analysis of experimental results demonstrates that the proposed method helps improving the state-of-the-art architecture's APE quality for high-quality MTs.
Towards Semi-Supervised Learning of Automatic Post-Editing: Data-Synthesis by Infilling Mask with Erroneous Tokens
Apr 08, 2022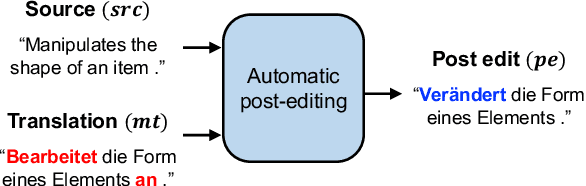
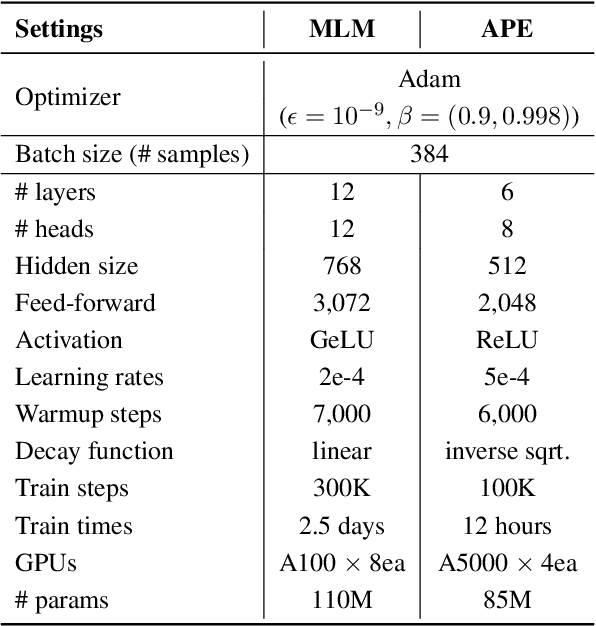
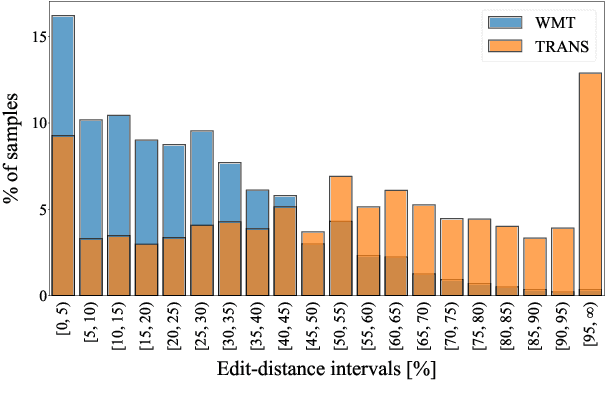
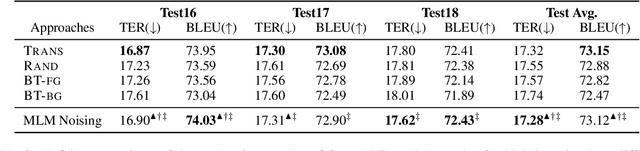
Semi-supervised learning that leverages synthetic training data has been widely adopted in the field of Automatic post-editing (APE) to overcome the lack of human-annotated training data. In that context, data-synthesis methods to create high-quality synthetic data have also received much attention. Considering that APE takes machine-translation outputs containing translation errors as input, we propose a noising-based data-synthesis method that uses a mask language model to create noisy texts through substituting masked tokens with erroneous tokens, yet following the error-quantity statistics appearing in genuine APE data. In addition, we propose corpus interleaving, which is to combine two separate synthetic data by taking only advantageous samples, to further enhance the quality of the synthetic data created with our noising method. Experimental results reveal that using the synthetic data created with our approach results in significant improvements in APE performance upon using other synthetic data created with different existing data-synthesis methods.