 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Do Multilingual Reasoning Gaps Emerge in Reasoning Language Models?
Oct 31, 2025Reasoning language models (RLMs) achieve strong performance on complex reasoning tasks, yet they still suffer from a multilingual reasoning gap, performing better in high-resource languages than in low-resource ones. While recent efforts have reduced this gap, its underlying causes remain largely unexplored. In this paper, we address this by showing that the multilingual reasoning gap largely stems from failures in language understanding-the model's inability to represent the multilingual input meaning into the dominant language (i.e., English) within its reasoning trace. This motivates us to examine whether understanding failures can be detected, as this ability could help mitigate the multilingual reasoning gap. To this end, we evaluate a range of detection methods and find that understanding failures can indeed be identified, with supervised approaches performing best. Building on this, we propose Selective Translation, a simple yet effective strategy that translates the multilingual input into English only when an understanding failure is detected. Experimental results show that Selective Translation bridges the multilingual reasoning gap, achieving near full-translation performance while using translation for only about 20% of inputs. Together, our work demonstrates that understanding failures are the primary cause of the multilingual reasoning gap and can be detected and selectively mitigated, providing key insight into its origin and a promising path toward more equitable multilingual reasoning. Our code and data are publicly available at https://github.com/deokhk/RLM_analysis.
Self-Correcting Code Generation Using Small Language Models
May 29, 2025Self-correction has demonstrated potential in code generation by allowing language models to revise and improve their outputs through successive refinement. Recent studies have explored prompting-based strategies that incorporate verification or feedback loops using proprietary models, as well as training-based methods that leverage their strong reasoning capabilities. However, whether smaller models possess the capacity to effectively guide their outputs through self-reflection remains unexplored. Our findings reveal that smaller models struggle to exhibit reflective revision behavior across both self-correction paradigms. In response, we introduce CoCoS, an approach designed to enhance the ability of small language models for multi-turn code correction. Specifically, we propose an online reinforcement learning objective that trains the model to confidently maintain correct outputs while progressively correcting incorrect outputs as turns proceed. Our approach features an accumulated reward function that aggregates rewards across the entire trajectory and a fine-grained reward better suited to multi-turn correction scenarios. This facilitates the model in enhancing initial response quality while achieving substantial improvements through self-correction. With 1B-scale models, CoCoS achieves improvements of 35.8% on the MBPP and 27.7% on HumanEval compared to the baselines.
EnSToM: Enhancing Dialogue Systems with Entropy-Scaled Steering Vectors for Topic Maintenance
May 22, 2025Small large language models (sLLMs) offer the advantage of being lightweight and efficient, which makes them suitable for resource-constrained environments. However, sLLMs often struggle to maintain topic consistency in task-oriented dialogue systems, which is critical for scenarios such as service chatbots. Specifically, it is important to ensure that the model denies off-topic or malicious inputs and adheres to its intended functionality so as to prevent potential misuse and uphold reliability. Towards this, existing activation engineering approaches have been proposed to manipulate internal activations during inference. While these methods are effective in certain scenarios, our preliminary experiments reveal their limitations in ensuring topic adherence. Therefore, to address this, we propose a novel approach termed Entropy-scaled Steering vectors for Topic Maintenance (EnSToM). EnSToM dynamically adjusts the steering intensity based on input uncertainty, which allows the model to handle off-topic distractors effectively while preserving on-topic accuracy. Our experiments demonstrate that EnSToM achieves significant performance gain with a relatively small data size compared to fine-tuning approaches. By improving topic adherence without compromising efficiency, our approach provides a robust solution for enhancing sLLM-based dialogue systems.
MiLQ: Benchmarking IR Models for Bilingual Web Search with Mixed Language Queries
May 22, 2025
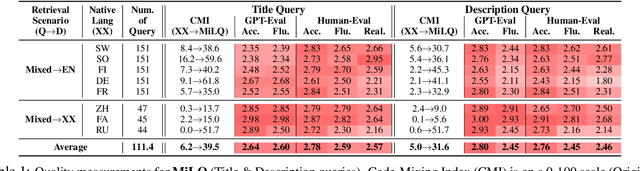

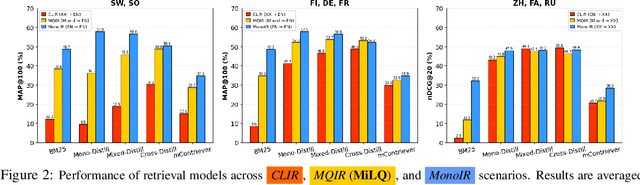
Despite bilingual speakers frequently using mixed-language queries in web searches, Information Retrieval (IR) research on them remains scarce. To address this, we introduce MiLQ,Mixed-Language Query test set, the first public benchmark of mixed-language queries, confirmed as realistic and highly preferred. Experiments show that multilingual IR models perform moderately on MiLQ and inconsistently across native, English, and mixed-language queries, also suggesting code-switched training data's potential for robust IR models handling such queries. Meanwhile, intentional English mixing in queries proves an effective strategy for bilinguals searching English documents, which our analysis attributes to enhanced token matching compared to native queries.
GuRE:Generative Query REwriter for Legal Passage Retrieval
May 19, 2025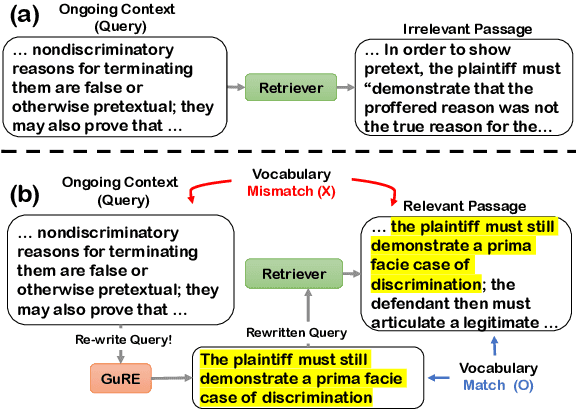
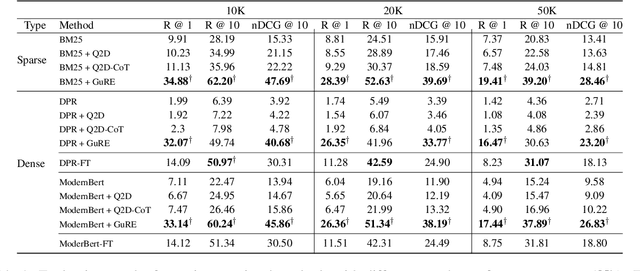
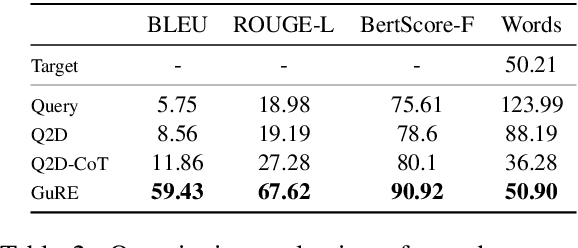

Legal Passage Retrieval (LPR) systems are crucial as they help practitioners save time when drafting legal arguments. However, it remains an underexplored avenue. One primary reason is the significant vocabulary mismatch between the query and the target passage. To address this, we propose a simple yet effective method, the Generative query REwriter (GuRE). We leverage the generative capabilities of Large Language Models (LLMs) by training the LLM for query rewriting. "Rewritten queries" help retrievers to retrieve target passages by mitigating vocabulary mismatch. Experimental results show that GuRE significantly improves performance in a retriever-agnostic manner, outperforming all baseline methods. Further analysis reveals that different training objectives lead to distinct retrieval behaviors, making GuRE more suitable than direct retriever fine-tuning for real-world applications. Codes are avaiable at github.com/daehuikim/GuRE.
Retrieval-Augmented Fine-Tuning With Preference Optimization For Visual Program Generation
Feb 23, 2025

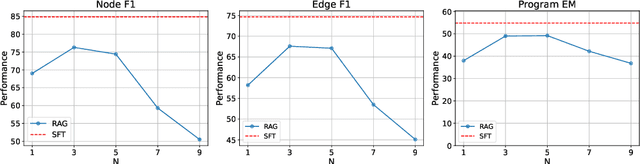

Visual programming languages (VPLs) allow users to create programs through graphical interfaces, which results in easier accessibility and their widespread usage in various domains. To further enhance this accessibility, recent research has focused on generating VPL code from user instructions using large language models (LLMs). Specifically, by employing prompting-based methods, these studies have shown promising results. Nevertheless, such approaches can be less effective for industrial VPLs such as Ladder Diagram (LD). LD is a pivotal language used in industrial automation processes and involves extensive domain-specific configurations, which are difficult to capture in a single prompt. In this work, we demonstrate that training-based methods outperform prompting-based methods for LD generation accuracy, even with smaller backbone models. Building on these findings, we propose a two-stage training strategy to further enhance VPL generation. First, we employ retrieval-augmented fine-tuning to leverage the repetitive use of subroutines commonly seen in industrial VPLs. Second, we apply direct preference optimization (DPO) to further guide the model toward accurate outputs, using systematically generated preference pairs through graph editing operations. Extensive experiments on real-world LD data demonstrate that our approach improves program-level accuracy by over 10% compared to supervised fine-tuning, which highlights its potential to advance industrial automation.
Cross-lingual Back-Parsing: Utterance Synthesis from Meaning Representation for Zero-Resource Semantic Parsing
Oct 01, 2024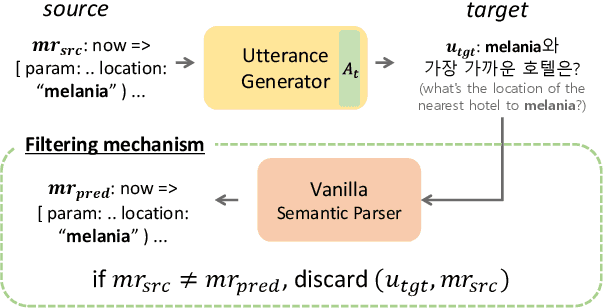

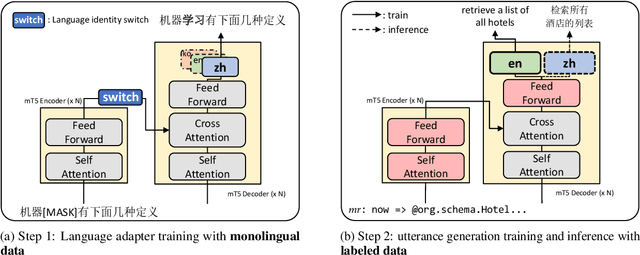
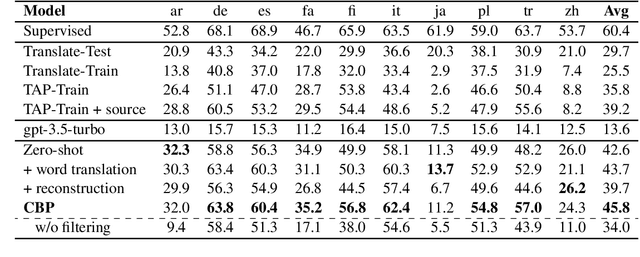
Recent efforts have aimed to utilize multilingual pretrained language models (mPLMs) to extend semantic parsing (SP) across multiple languages without requiring extensive annotations. However, achieving zero-shot cross-lingual transfer for SP remains challenging, leading to a performance gap between source and target languages. In this study, we propose Cross-Lingual Back-Parsing (CBP), a novel data augmentation methodology designed to enhance cross-lingual transfer for SP. Leveraging the representation geometry of the mPLMs, CBP synthesizes target language utterances from source meaning representations. Our methodology effectively performs cross-lingual data augmentation in challenging zero-resource settings, by utilizing only labeled data in the source language and monolingual corpora. Extensive experiments on two cross-language SP benchmarks (Mschema2QA and Xspider) demonstrate that CBP brings substantial gains in the target language. Further analysis of the synthesized utterances shows that our method successfully generates target language utterances with high slot value alignment rates while preserving semantic integrity. Our codes and data are publicly available at https://github.com/deokhk/CBP.
Ontology-Free General-Domain Knowledge Graph-to-Text Generation Dataset Synthesis using Large Language Model
Sep 11, 2024



Knowledge Graph-to-Text (G2T) generation involves verbalizing structured knowledge graphs into natural language text. Recent advancements in Pretrained Language Models (PLMs) have improved G2T performance, but their effectiveness depends on datasets with precise graph-text alignment. However, the scarcity of high-quality, general-domain G2T generation datasets restricts progress in the general-domain G2T generation research. To address this issue, we introduce Wikipedia Ontology-Free Graph-text dataset (WikiOFGraph), a new large-scale G2T dataset generated using a novel method that leverages Large Language Model (LLM) and Data-QuestEval. Our new dataset, which contains 5.85M general-domain graph-text pairs, offers high graph-text consistency without relying on external ontologies. Experimental results demonstrate that PLM fine-tuned on WikiOFGraph outperforms those trained on other datasets across various evaluation metrics. Our method proves to be a scalable and effective solution for generating high-quality G2T data, significantly advancing the field of G2T generation.
Denoising Table-Text Retrieval for Open-Domain Question Answering
Mar 26, 2024


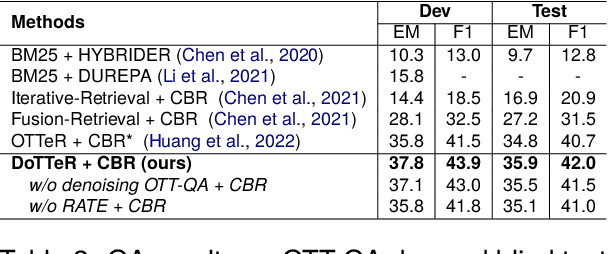
In table-text open-domain question answering, a retriever system retrieves relevant evidence from tables and text to answer questions. Previous studies in table-text open-domain question answering have two common challenges: firstly, their retrievers can be affected by false-positive labels in training datasets; secondly, they may struggle to provide appropriate evidence for questions that require reasoning across the table. To address these issues, we propose Denoised Table-Text Retriever (DoTTeR). Our approach involves utilizing a denoised training dataset with fewer false positive labels by discarding instances with lower question-relevance scores measured through a false positive detection model. Subsequently, we integrate table-level ranking information into the retriever to assist in finding evidence for questions that demand reasoning across the table. To encode this ranking information, we fine-tune a rank-aware column encoder to identify minimum and maximum values within a column. Experimental results demonstrate that DoTTeR significantly outperforms strong baselines on both retrieval recall and downstream QA tasks. Our code is available at https://github.com/deokhk/DoTTeR.