 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Do Multilingual Reasoning Gaps Emerge in Reasoning Language Models?
Oct 31, 2025Reasoning language models (RLMs) achieve strong performance on complex reasoning tasks, yet they still suffer from a multilingual reasoning gap, performing better in high-resource languages than in low-resource ones. While recent efforts have reduced this gap, its underlying causes remain largely unexplored. In this paper, we address this by showing that the multilingual reasoning gap largely stems from failures in language understanding-the model's inability to represent the multilingual input meaning into the dominant language (i.e., English) within its reasoning trace. This motivates us to examine whether understanding failures can be detected, as this ability could help mitigate the multilingual reasoning gap. To this end, we evaluate a range of detection methods and find that understanding failures can indeed be identified, with supervised approaches performing best. Building on this, we propose Selective Translation, a simple yet effective strategy that translates the multilingual input into English only when an understanding failure is detected. Experimental results show that Selective Translation bridges the multilingual reasoning gap, achieving near full-translation performance while using translation for only about 20% of inputs. Together, our work demonstrates that understanding failures are the primary cause of the multilingual reasoning gap and can be detected and selectively mitigated, providing key insight into its origin and a promising path toward more equitable multilingual reasoning. Our code and data are publicly available at https://github.com/deokhk/RLM_analysis.
MiLQ: Benchmarking IR Models for Bilingual Web Search with Mixed Language Queries
May 22, 2025
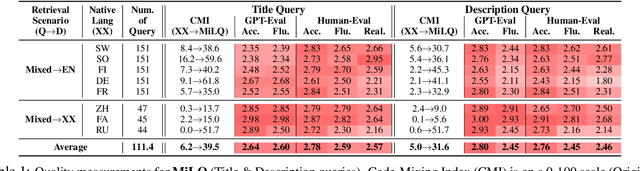

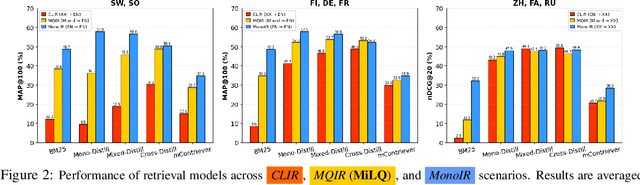
Despite bilingual speakers frequently using mixed-language queries in web searches, Information Retrieval (IR) research on them remains scarce. To address this, we introduce MiLQ,Mixed-Language Query test set, the first public benchmark of mixed-language queries, confirmed as realistic and highly preferred. Experiments show that multilingual IR models perform moderately on MiLQ and inconsistently across native, English, and mixed-language queries, also suggesting code-switched training data's potential for robust IR models handling such queries. Meanwhile, intentional English mixing in queries proves an effective strategy for bilinguals searching English documents, which our analysis attributes to enhanced token matching compared to native queries.
Cross-lingual Transfer for Automatic Question Generation by Learning Interrogative Structures in Target Languages
Oct 04, 2024



Automatic question generation (QG) serves a wide range of purposes, such as augmenting question-answering (QA) corpora, enhancing chatbot systems, and developing educational materials. Despite its importance, most existing datasets predominantly focus on English, resulting in a considerable gap in data availability for other languages. Cross-lingual transfer for QG (XLT-QG) addresses this limitation by allowing models trained on high-resource language datasets to generate questions in low-resource languages. In this paper, we propose a simple and efficient XLT-QG method that operates without the need for monolingual, parallel, or labeled data in the target language, utilizing a small language model. Our model, trained solely on English QA datasets, learns interrogative structures from a limited set of question exemplars, which are then applied to generate questions in the target language. Experimental results show that our method outperforms several XLT-QG baselines and achieves performance comparable to GPT-3.5-turbo across different languages. Additionally, the synthetic data generated by our model proves beneficial for training multilingual QA models. With significantly fewer parameters than large language models and without requiring additional training for target languages, our approach offers an effective solution for QG and QA tasks across various languages.
Cross-lingual Back-Parsing: Utterance Synthesis from Meaning Representation for Zero-Resource Semantic Parsing
Oct 01, 2024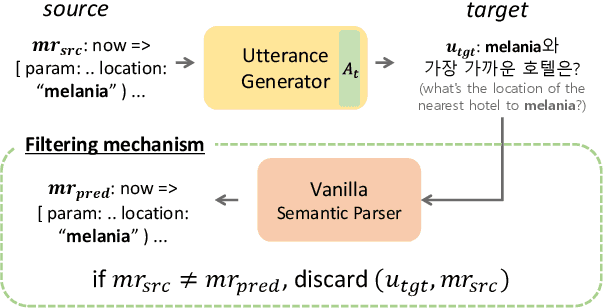

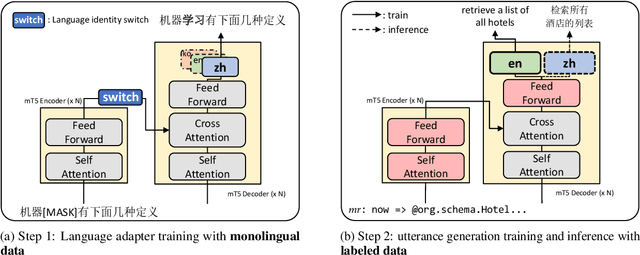
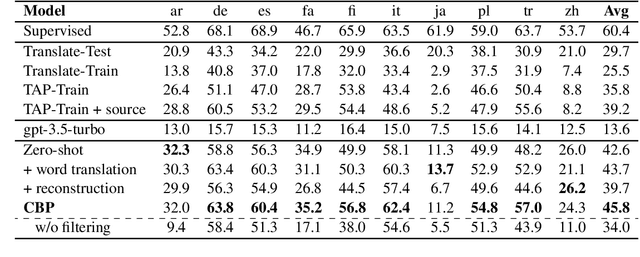
Recent efforts have aimed to utilize multilingual pretrained language models (mPLMs) to extend semantic parsing (SP) across multiple languages without requiring extensive annotations. However, achieving zero-shot cross-lingual transfer for SP remains challenging, leading to a performance gap between source and target languages. In this study, we propose Cross-Lingual Back-Parsing (CBP), a novel data augmentation methodology designed to enhance cross-lingual transfer for SP. Leveraging the representation geometry of the mPLMs, CBP synthesizes target language utterances from source meaning representations. Our methodology effectively performs cross-lingual data augmentation in challenging zero-resource settings, by utilizing only labeled data in the source language and monolingual corpora. Extensive experiments on two cross-language SP benchmarks (Mschema2QA and Xspider) demonstrate that CBP brings substantial gains in the target language. Further analysis of the synthesized utterances shows that our method successfully generates target language utterances with high slot value alignment rates while preserving semantic integrity. Our codes and data are publicly available at https://github.com/deokhk/CBP.
Explainable Multi-hop Question Generation: An End-to-End Approach without Intermediate Question Labeling
Mar 31, 2024In response to the increasing use of interactive artificial intelligence, the demand for the capacity to handle complex questions has increased. Multi-hop question generation aims to generate complex questions that requires multi-step reasoning over several documents. Previous studies have predominantly utilized end-to-end models, wherein questions are decoded based on the representation of context documents. However, these approaches lack the ability to explain the reasoning process behind the generated multi-hop questions. Additionally, the question rewriting approach, which incrementally increases the question complexity, also has limitations due to the requirement of labeling data for intermediate-stage questions. In this paper, we introduce an end-to-end question rewriting model that increases question complexity through sequential rewriting. The proposed model has the advantage of training with only the final multi-hop questions, without intermediate questions. Experimental results demonstrate the effectiveness of our model in generating complex questions, particularly 3- and 4-hop questions, which are appropriately paired with input answers. We also prove that our model logically and incrementally increases the complexity of questions, and the generated multi-hop questions are also beneficial for training question answering models.
Multi-Type Conversational Question-Answer Generation with Closed-ended and Unanswerable Questions
Oct 24, 2022Conversational question answering (CQA) facilitates an incremental and interactive understanding of a given context, but building a CQA system is difficult for many domains due to the problem of data scarcity. In this paper, we introduce a novel method to synthesize data for CQA with various question types, including open-ended, closed-ended, and unanswerable questions. We design a different generation flow for each question type and effectively combine them in a single, shared framework. Moreover, we devise a hierarchical answerability classification (hierarchical AC) module that improves quality of the synthetic data while acquiring unanswerable questions. Manual inspections show that synthetic data generated with our framework have characteristics very similar to those of human-generated conversations. Across four domains, CQA systems trained on our synthetic data indeed show good performance close to the systems trained on human-annotated data.
Conversational QA Dataset Generation with Answer Revision
Sep 23, 2022



Conversational question--answer generation is a task that automatically generates a large-scale conversational question answering dataset based on input passages. In this paper, we introduce a novel framework that extracts question-worthy phrases from a passage and then generates corresponding questions considering previous conversations. In particular, our framework revises the extracted answers after generating questions so that answers exactly match paired questions. Experimental results show that our simple answer revision approach leads to significant improvement in the quality of synthetic data. Moreover, we prove that our framework can be effectively utilized for domain adaptation of conversational question answering.