 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Semi-Supervised Learning of Automatic Post-Editing: Data-Synthesis by Infilling Mask with Erroneous Tokens
Paper and Code
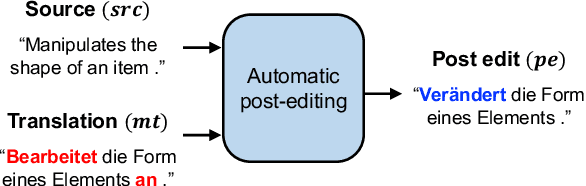
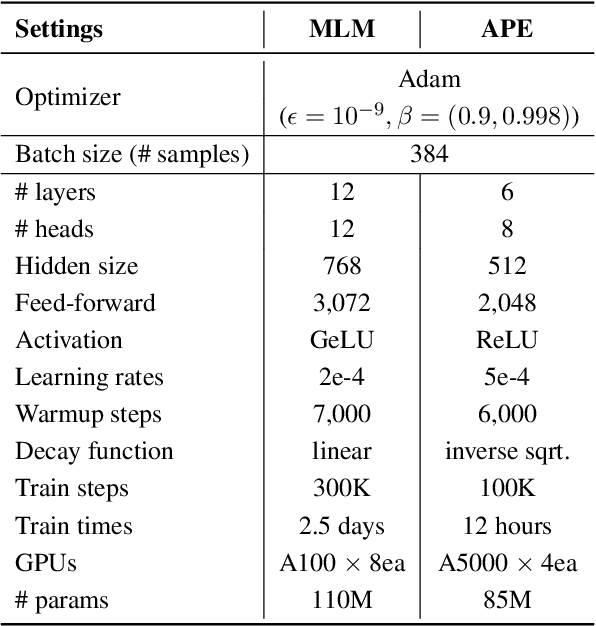
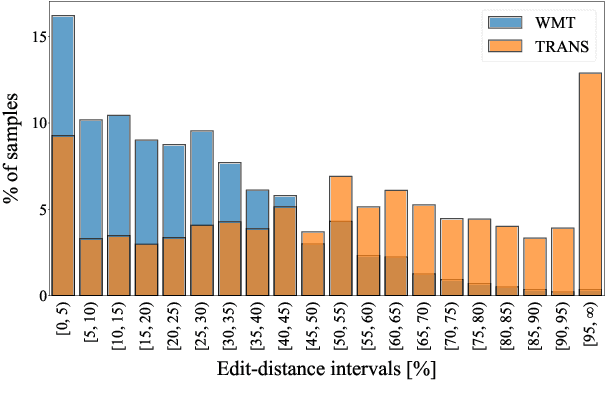
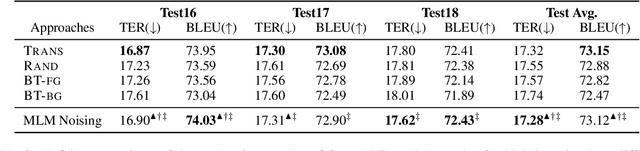
Semi-supervised learning that leverages synthetic training data has been widely adopted in the field of Automatic post-editing (APE) to overcome the lack of human-annotated training data. In that context, data-synthesis methods to create high-quality synthetic data have also received much attention. Considering that APE takes machine-translation outputs containing translation errors as input, we propose a noising-based data-synthesis method that uses a mask language model to create noisy texts through substituting masked tokens with erroneous tokens, yet following the error-quantity statistics appearing in genuine APE data. In addition, we propose corpus interleaving, which is to combine two separate synthetic data by taking only advantageous samples, to further enhance the quality of the synthetic data created with our noising method. Experimental results reveal that using the synthetic data created with our approach results in significant improvements in APE performance upon using other synthetic data created with different existing data-synthesis methods.