Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecay-Function-Free Time-Aware Attention to Context and Speaker Indicator for Spoken Language Understanding
Paper and Code

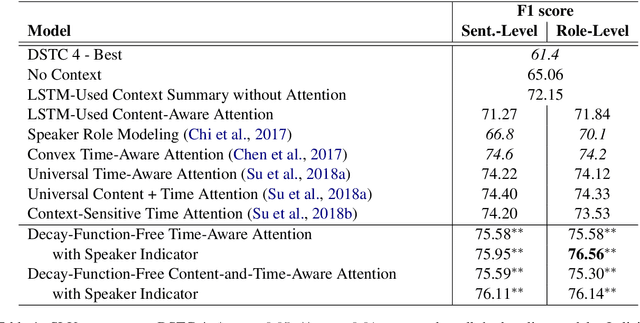
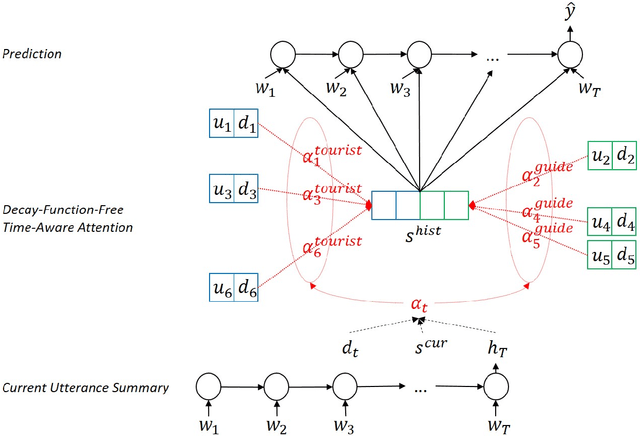
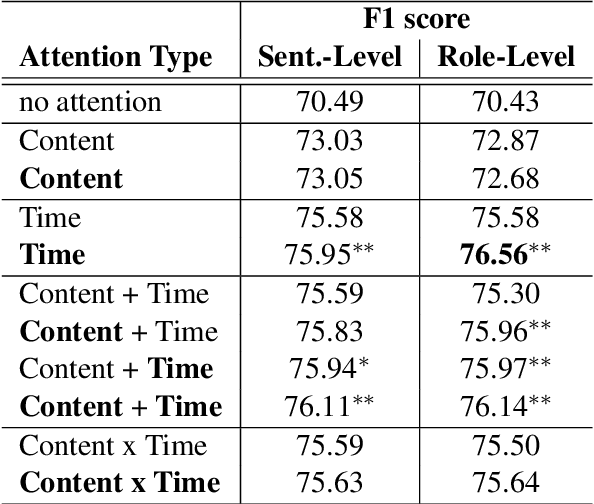
To capture salient contextual information for spoken language understanding (SLU) of a dialogue, we propose time-aware models that automatically learn the latent time-decay function of the history without a manual time-decay function. We also propose a method to identify and label the current speaker to improve the SLU accuracy. In experiments on the benchmark dataset used in Dialog State Tracking Challenge 4, the proposed models achieved significantly higher F1 scores than the state-of-the-art contextual models. Finally, we analyze the effectiveness of the introduced models in detail. The analysis demonstrates that the proposed methods were effective to improve SLU accuracy individually.
* Accepted as a long paper at NAACL 2019
View paper on