 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level post-processing for Korean character recognition using morphological analysis and linguistic evaluation
Paper and Code
Apr 24, 1996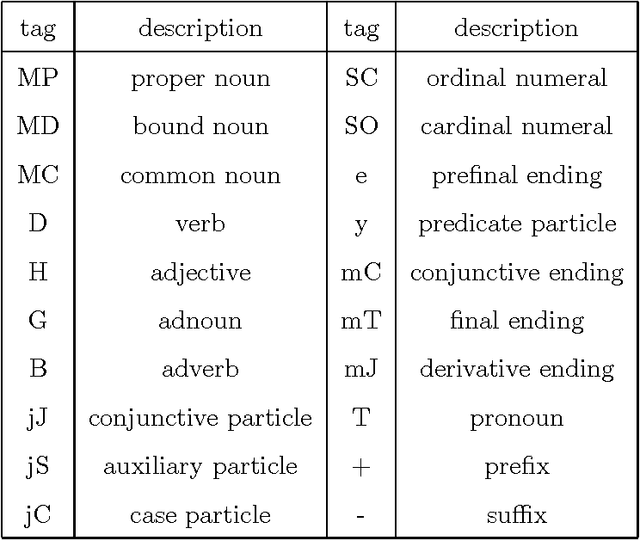
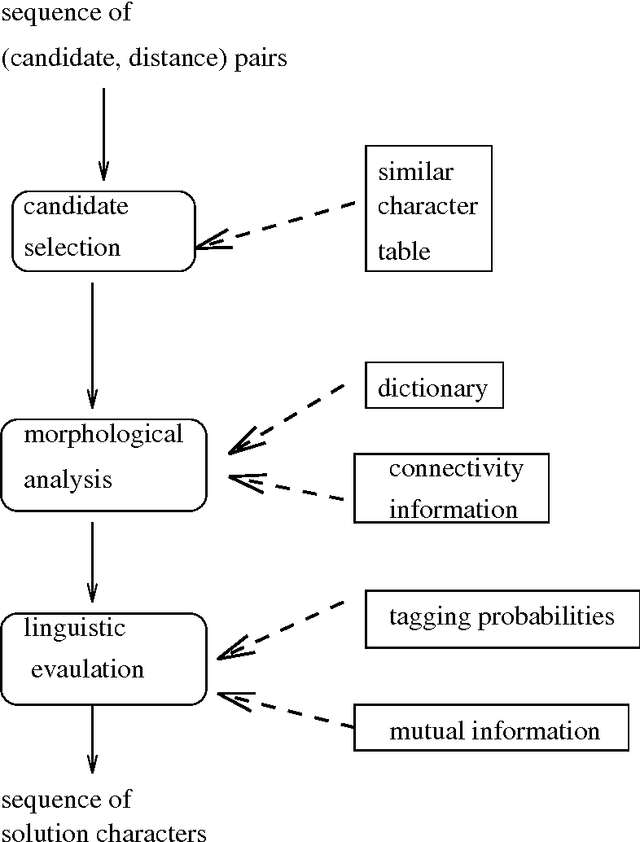
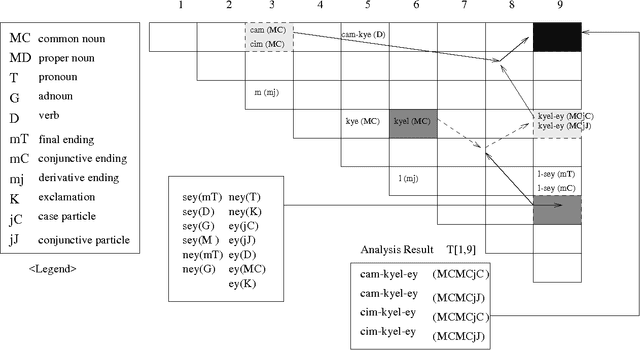
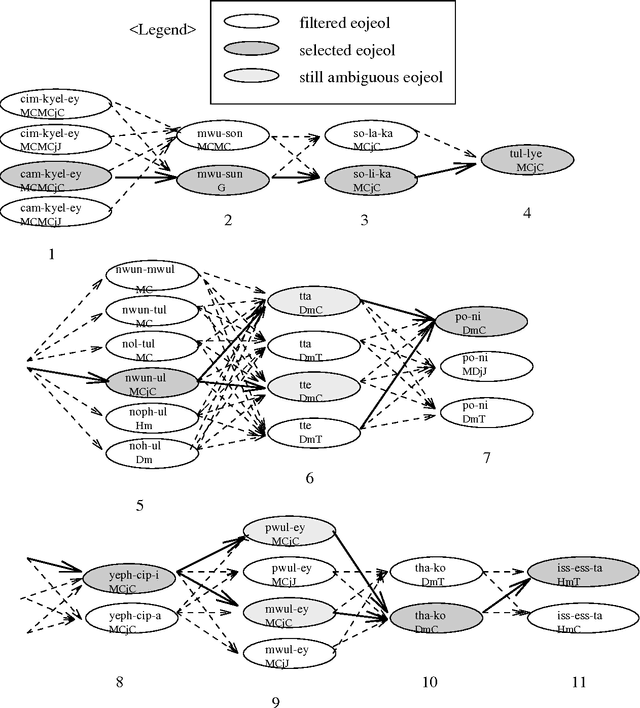
Most of the post-processing methods for character recognition rely on contextual information of character and word-fragment levels. However, due to linguistic characteristics of Korean, such low-level information alone is not sufficient for high-quality character-recognition applications, and we need much higher-level contextual information to improve the recognition results. This paper presents a domain independent post-processing technique that utilizes multi-level morphological, syntactic, and semantic information as well as character-level information. The proposed post-processing system performs three-level processing: candidate character-set selection, candidate eojeol (Korean word) generation through morphological analysis, and final single eojeol-sequence selection by linguistic evaluation. All the required linguistic information and probabilities are automatically acquired from a statistical corpus analysis. Experimental results demonstrate the effectiveness of our method, yielding error correction rate of 80.46%, and improved recognition rate of 95.53% from before-post-processing rate 71.2% for single best-solution selection.