 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstractive Summarization of Reddit Posts with Multi-level Memory Networks
Paper and Code
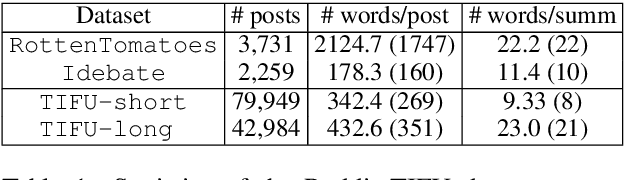


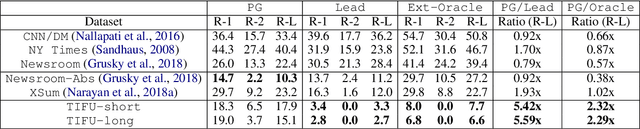
We address the problem of abstractive summarization in two directions: proposing a novel dataset and a new model. First, we collect Reddit TIFU dataset, consisting of 120K posts from the online discussion forum Reddit. We use such informal crowd-generated posts as text source, because we empirically observe that existing datasets mostly use formal documents as source text such as news articles; thus, they could suffer from some biases that key sentences usually located at the beginning of the text and favorable summary candidates are already inside the text in nearly exact forms. Such biases can not only be structural clues of which extractive methods better take advantage, but also be obstacles that hinder abstractive methods from learning their text abstraction capability. Second, we propose a novel abstractive summarization model named multi-level memory networks (MMN), equipped with multi-level memory to store the information of text from different levels of abstraction. With quantitative evaluation and user studies via Amazon Mechanical Turk, we show the Reddit TIFU dataset is highly abstractive and the MMN outperforms the state-of-the-art summarization models.