 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVIS: A Benchmark for Multimodal Source Attribution in Long-form Visual Question Answering
Nov 15, 2025Source attribution aims to enhance the reliability of AI-generated answers by including references for each statement, helping users validate the provided answers. However, existing work has primarily focused on text-only scenario and largely overlooked the role of multimodality. We introduce MAVIS, the first benchmark designed to evaluate multimodal source attribution systems that understand user intent behind visual questions, retrieve multimodal evidence, and generate long-form answers with citations. Our dataset comprises 157K visual QA instances, where each answer is annotated with fact-level citations referring to multimodal documents. We develop fine-grained automatic metrics along three dimensions of informativeness, groundedness, and fluency, and demonstrate their strong correlation with human judgments. Our key findings are threefold: (1) LVLMs with multimodal RAG generate more informative and fluent answers than unimodal RAG, but they exhibit weaker groundedness for image documents than for text documents, a gap amplified in multimodal settings. (2) Given the same multimodal documents, there is a trade-off between informativeness and groundedness across different prompting methods. (3) Our proposed method highlights mitigating contextual bias in interpreting image documents as a crucial direction for future research. The dataset and experimental code are available at https://github.com/seokwon99/MAVIS
Is a Peeled Apple Still Red? Evaluating LLMs' Ability for Conceptual Combination with Property Type
Feb 10, 2025



Conceptual combination is a cognitive process that merges basic concepts, enabling the creation of complex expressions. During this process, the properties of combination (e.g., the whiteness of a peeled apple) can be inherited from basic concepts, newly emerge, or be canceled. However, previous studies have evaluated a limited set of properties and have not examined the generative process. To address this gap, we introduce the Conceptual Combination with Property Type dataset (CCPT), which consists of 12.3K annotated triplets of noun phrases, properties, and property types. Using CCPT, we establish three types of tasks to evaluate LLMs for conceptual combination thoroughly. Our key findings are threefold: (1) Our automatic metric grading property emergence and cancellation closely corresponds with human judgments. (2) LLMs, including OpenAI's o1, struggle to generate noun phrases which possess given emergent properties. (3) Our proposed method, inspired by cognitive psychology model that explains how relationships between concepts are formed, improves performances in all generative tasks. The dataset and experimental code are available at https://github.com/seokwon99/CCPT.git.
Read-only Prompt Optimization for Vision-Language Few-shot Learning
Aug 29, 2023

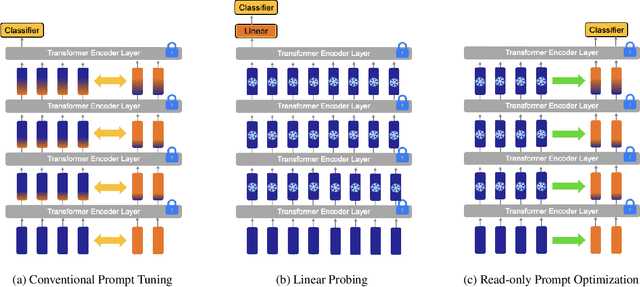

In recent years, prompt tuning has proven effective in adapting pre-trained vision-language models to downstream tasks. These methods aim to adapt the pre-trained models by introducing learnable prompts while keeping pre-trained weights frozen. However, learnable prompts can affect the internal representation within the self-attention module, which may negatively impact performance variance and generalization, especially in data-deficient settings. To address these issues, we propose a novel approach, Read-only Prompt Optimization (RPO). RPO leverages masked attention to prevent the internal representation shift in the pre-trained model. Further, to facilitate the optimization of RPO, the read-only prompts are initialized based on special tokens of the pre-trained model. Our extensive experiments demonstrate that RPO outperforms CLIP and CoCoOp in base-to-new generalization and domain generalization while displaying better robustness. Also, the proposed method achieves better generalization on extremely data-deficient settings, while improving parameter efficiency and computational overhead. Code is available at https://github.com/mlvlab/RPO.