 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeri-LN: Revisiting Layer Normalization in the Transformer Architecture
Feb 04, 2025



Designing Transformer architectures with the optimal layer normalization (LN) strategy that ensures large-scale training stability and expedite convergence has remained elusive, even in this era of large language models (LLMs). To this end, we present a comprehensive analytical foundation for understanding how different LN strategies influence training dynamics in large-scale Transformer training. Until recently, Pre-LN and Post-LN have long dominated standard practices despite their limitations in large-scale training. However, several open-source large-scale models have recently begun silently adopting a third strategy without much explanation. This strategy places layer normalization (LN) peripherally around sublayers, a design we term Peri-LN. While Peri-LN has demonstrated promising empirical performance, its precise mechanisms and benefits remain almost unexplored. Our in-depth analysis shows that Peri-LN strikes an ideal balance in variance growth -- unlike Pre-LN and Post-LN, which are prone to vanishing gradients and ``massive activations.'' To validate our theoretical insight, we conduct large-scale experiments on Transformers up to 3.2B parameters, showing that Peri-LN consistently achieves more balanced variance growth, steadier gradient flow, and convergence stability. Our results suggest that Peri-LN warrants broader consideration for large-scale Transformer architectures, providing renewed insights into the optimal placement and application of LN.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Prometheus: Inducing Fine-grained Evaluation Capability in Language Models
Oct 12, 2023Recently, using a powerful proprietary Large Language Model (LLM) (e.g., GPT-4) as an evaluator for long-form responses has become the de facto standard. However, for practitioners with large-scale evaluation tasks and custom criteria in consideration (e.g., child-readability), using proprietary LLMs as an evaluator is unreliable due to the closed-source nature, uncontrolled versioning, and prohibitive costs. In this work, we propose Prometheus, a fully open-source LLM that is on par with GPT-4's evaluation capabilities when the appropriate reference materials (reference answer, score rubric) are accompanied. We first construct the Feedback Collection, a new dataset that consists of 1K fine-grained score rubrics, 20K instructions, and 100K responses and language feedback generated by GPT-4. Using the Feedback Collection, we train Prometheus, a 13B evaluator LLM that can assess any given long-form text based on customized score rubric provided by the user. Experimental results show that Prometheus scores a Pearson correlation of 0.897 with human evaluators when evaluating with 45 customized score rubrics, which is on par with GPT-4 (0.882), and greatly outperforms ChatGPT (0.392). Furthermore, measuring correlation with GPT-4 with 1222 customized score rubrics across four benchmarks (MT Bench, Vicuna Bench, Feedback Bench, Flask Eval) shows similar trends, bolstering Prometheus's capability as an evaluator LLM. Lastly, Prometheus achieves the highest accuracy on two human preference benchmarks (HHH Alignment & MT Bench Human Judgment) compared to open-sourced reward models explicitly trained on human preference datasets, highlighting its potential as an universal reward model. We open-source our code, dataset, and model at https://github.com/kaistAI/Prometheus.
On the Effect of Pretraining Corpora on In-context Learning by a Large-scale Language Model
Apr 28, 2022
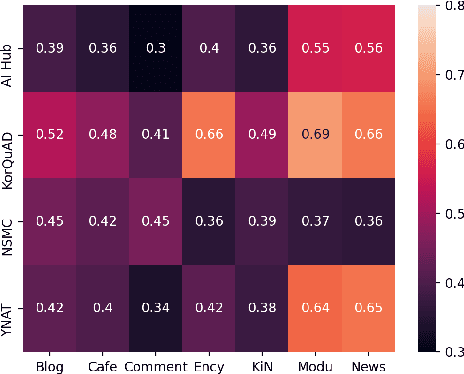
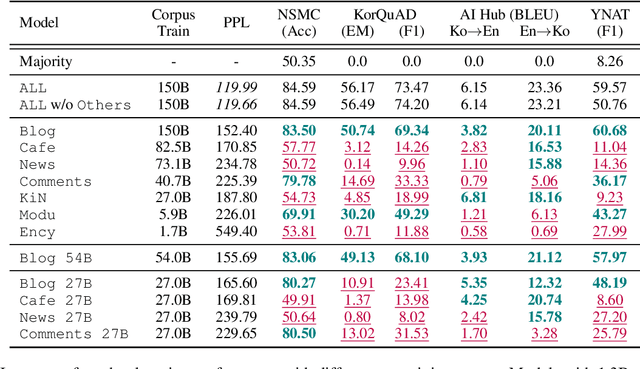
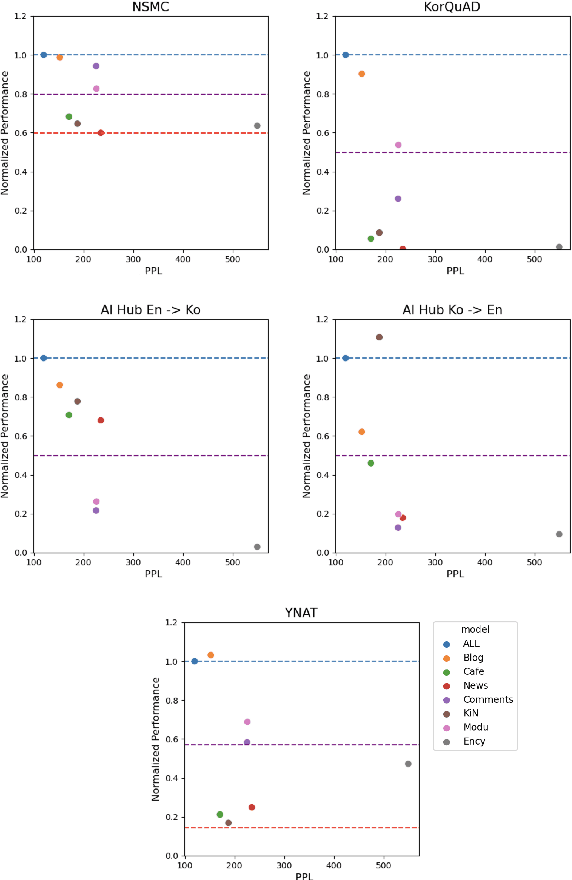
Many recent studies on large-scale language models have reported successful in-context zero- and few-shot learning ability. However, the in-depth analysis of when in-context learning occurs is still lacking. For example, it is unknown how in-context learning performance changes as the training corpus varies. Here, we investigate the effects of the source and size of the pretraining corpus on in-context learning in HyperCLOVA, a Korean-centric GPT-3 model. From our in-depth investigation, we introduce the following observations: (1) in-context learning performance heavily depends on the corpus domain source, and the size of the pretraining corpus does not necessarily determine the emergence of in-context learning, (2) in-context learning ability can emerge when a language model is trained on a combination of multiple corpora, even when each corpus does not result in in-context learning on its own, (3) pretraining with a corpus related to a downstream task does not always guarantee the competitive in-context learning performance of the downstream task, especially in the few-shot setting, and (4) the relationship between language modeling (measured in perplexity) and in-context learning does not always correlate: e.g., low perplexity does not always imply high in-context few-shot learning performance.
Two-stage Textual Knowledge Distillation to Speech Encoder for Spoken Language Understanding
Oct 25, 2020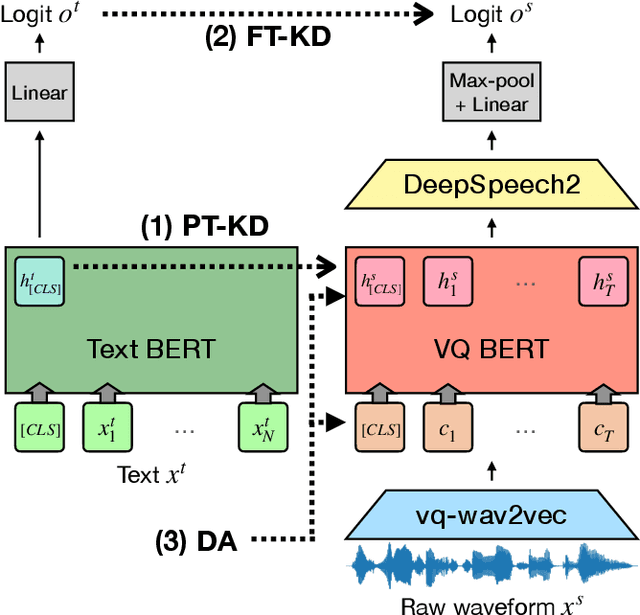
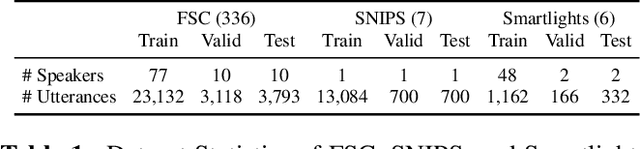
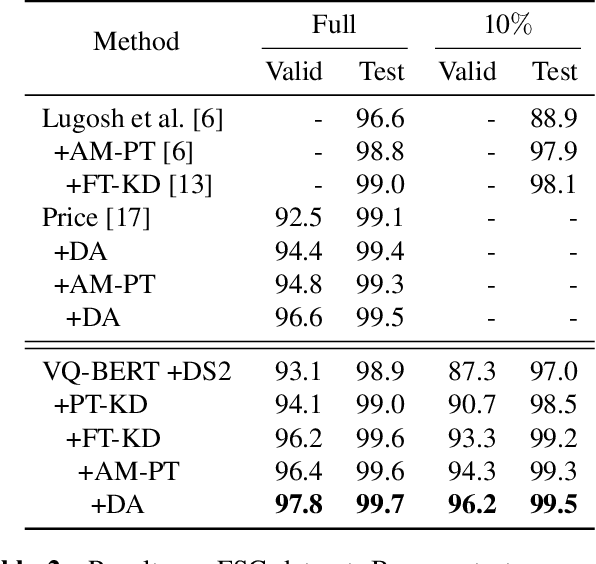
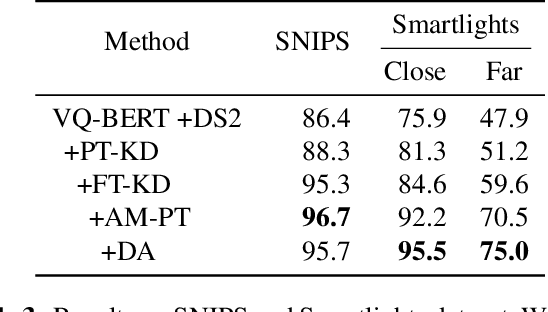
End-to-end approaches open a new way for more accurate and efficient spoken language understanding (SLU) systems by alleviating the drawbacks of traditional pipeline systems. Previous works exploit textual information for an SLU model via pre-training with automatic speech recognition or fine-tuning with knowledge distillation. To utilize textual information more effectively, this work proposes a two-stage textual knowledge distillation method that matches utterance-level representations and predicted logits of two modalities during pre-training and fine-tuning, sequentially. We use vq-wav2vec BERT as a speech encoder because it captures general and rich features. Furthermore, we improve the performance, especially in a low-resource scenario, with data augmentation methods by randomly masking spans of discrete audio tokens and contextualized hidden representations. Consequently, we push the state-of-the-art on the Fluent Speech Commands, achieving 99.7% test accuracy in the full dataset setting and 99.5% in the 10% subset setting. Throughout the ablation studies, we empirically verify that all used methods are crucial to the final performance, providing the best practice for spoken language understanding. Code to reproduce our results will be available upon publication.