 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexterous Point Policy: Learning Point-based Dexterous Hand Policies from Human Demonstrations
Jun 09, 2026Robotic foundation models pre-trained on human demonstration videos have shown promise, but a significant embodiment gap remains when the resulting policies are deployed on real robots. A common remedy is to fine-tune these models on robot-specific demonstrations. However, robot data collection can be prohibitively expensive and time-consuming, which is particularly acute in dexterous manipulation, e.g., teleoperating a multi-fingered hand for even a single atomic task can take days. To address this, we introduce Dexterous Point Policy, a framework that learns dexterous manipulation policies directly from human videos and requires no robot demonstrations. Our core insight is that a unified 3D keypoint representation can bridge human and robot embodiments when used for both observations and actions. Specifically, we extract 3D keypoints of task-relevant objects and human hands from raw videos, and train an autoregressive transformer over these keypoints. We observe that at the keypoint level, specifically the wrist and fingertips, human and robot behaviors closely align, enabling direct policy transfer. On a suite of real-robot tasks spanning pick-and-place and tool use, Dexterous Point Policy attains 75.0% success, whereas a state-of-the-art VLA baseline reaches only 1.0%. Furthermore, our method generalizes strongly to unseen scenarios, including multi-object environments and novel object categories.
ExComm: Exploration-Stage Communication for Error-Resilient Agentic Test-Time Scaling
May 21, 2026A common failure mode in long-horizon agentic test-time scaling is error propagation, where factual errors or invalid deductions introduced at intermediate steps persist in the agent's belief state and contaminate later reasoning. Existing test-time scaling methods provide limited control over this process, as they often rely on agents to detect their own mistakes, select among flawed trajectories, or refine solutions only after errors have already shaped the reasoning path. We propose ExComm, a communication protocol for exploration-stage agentic test-time scaling. ExComm is motivated by the empirical observation that the majority of intermediate errors in parallel agentic reasoning produce detectable cross-agent factual conflicts. Leveraging the iterative structure of agentic workflows, ExComm periodically audits agent belief states to detect such conflicts, resolves them through a dedicated tool-based verification loop, and returns concise, targeted feedback to the involved agents. Corrections are incorporated through soft belief updates, which append verified feedback rather than overwriting existing beliefs. Furthermore, to prevent collapsing trajectory diversity due to communication, ExComm further introduces a trajectory diversification module that redirects redundant trajectories toward orthogonal strategies. Experiments on AIME 2024, AIME 2025, and GAIA with Gemini-2.5-Flash-Lite and Qwen3.5-4B show that ExComm consistently outperforms strong test-time scaling baselines, achieving average performance gains of 5.7% and 5.0% over the best-performing baselines, respectively. Further analyses demonstrate improved error recovery, favorable scaling behavior, stronger diversity than adapted communication baselines, and the best performance-cost trade-off among the evaluated methods.
RLDX-1 Technical Report
May 05, 2026While Vision-Language-Action models (VLAs) have shown remarkable progress toward human-like generalist robotic policies through the versatile intelligence (i.e. broad scene understanding and language-conditioned generalization) inherited from pre-trained Vision-Language Models, they still struggle with complex real-world tasks requiring broader functional capabilities (e.g. motion awareness, memory-aware decision making, and physical sensing). To address this, we introduce RLDX-1, a general-purpose robotic policy for dexterous manipulation built on the Multi-Stream Action Transformer (MSAT), an architecture that unifies these capabilities by integrating heterogeneous modalities through modality-specific streams with cross-modal joint self-attention. RLDX-1 further combines this architecture with system-level design choices, including synthesizing training data for rare manipulation scenarios, learning procedures specialized for human-like manipulation, and inference optimizations for real-time deployment. Through empirical evaluation, we show that RLDX-1 consistently outperforms recent frontier VLAs (e.g. $π_{0.5}$ and GR00T N1.6) across both simulation benchmarks and real-world tasks that require broad functional capabilities beyond general versatility. In particular, RLDX-1 shows superiority in ALLEX humanoid tasks by achieving success rates of 86.8% while $π_{0.5}$ and GR00T N1.6 achieve around 40%, highlighting the ability of RLDX-1 to control a high-DoF humanoid robot under diverse functional demands. Together, these results position RLDX-1 as a promising step toward reliable VLAs for complex, contact-rich, and dynamic real-world dexterous manipulation.
ReGUIDE: Data Efficient GUI Grounding via Spatial Reasoning and Search
May 21, 2025Recent advances in Multimodal Large Language Models (MLLMs) have enabled autonomous agents to interact with computers via Graphical User Interfaces (GUIs), where accurately localizing the coordinates of interface elements (e.g., buttons) is often required for fine-grained actions. However, this remains significantly challenging, leading prior works to rely on large-scale web datasets to improve the grounding accuracy. In this work, we propose Reasoning Graphical User Interface Grounding for Data Efficiency (ReGUIDE), a novel and effective framework for web grounding that enables MLLMs to learn data efficiently through self-generated reasoning and spatial-aware criticism. More specifically, ReGUIDE learns to (i) self-generate a language reasoning process for the localization via online reinforcement learning, and (ii) criticize the prediction using spatial priors that enforce equivariance under input transformations. At inference time, ReGUIDE further boosts performance through a test-time scaling strategy, which combines spatial search with coordinate aggregation. Our experiments demonstrate that ReGUIDE significantly advances web grounding performance across multiple benchmarks, outperforming baselines with substantially fewer training data points (e.g., only 0.2% samples compared to the best open-sourced baselines).
A Domain-Agnostic Scalable AI Safety Ensuring Framework
Apr 30, 2025



Ensuring the safety of AI systems has recently emerged as a critical priority for real-world deployment, particularly in physical AI applications. Current approaches to AI safety typically address predefined domain-specific safety conditions, limiting their ability to generalize across contexts. We propose a novel AI safety framework that ensures AI systems comply with any user-defined constraint, with any desired probability, and across various domains. In this framework, we combine an AI component (e.g., neural network) with an optimization problem to produce responses that minimize objectives while satisfying user-defined constraints with probabilities exceeding user-defined thresholds. For credibility assessment of the AI component, we propose internal test data, a supplementary set of safety-labeled data, and a conservative testing methodology that provides statistical validity of using internal test data. We also present an approximation method of a loss function and how to compute its gradient for training. We mathematically prove that probabilistic constraint satisfaction is guaranteed under specific, mild conditions and prove a scaling law between safety and the number of internal test data. We demonstrate our framework's effectiveness through experiments in diverse domains: demand prediction for production decision, safe reinforcement learning within the SafetyGym simulator, and guarding AI chatbot outputs. Through these experiments, we demonstrate that our method guarantees safety for user-specified constraints, outperforms for up to several order of magnitudes existing methods in low safety threshold regions, and scales effectively with respect to the size of internal test data.
Peri-LN: Revisiting Layer Normalization in the Transformer Architecture
Feb 04, 2025



Designing Transformer architectures with the optimal layer normalization (LN) strategy that ensures large-scale training stability and expedite convergence has remained elusive, even in this era of large language models (LLMs). To this end, we present a comprehensive analytical foundation for understanding how different LN strategies influence training dynamics in large-scale Transformer training. Until recently, Pre-LN and Post-LN have long dominated standard practices despite their limitations in large-scale training. However, several open-source large-scale models have recently begun silently adopting a third strategy without much explanation. This strategy places layer normalization (LN) peripherally around sublayers, a design we term Peri-LN. While Peri-LN has demonstrated promising empirical performance, its precise mechanisms and benefits remain almost unexplored. Our in-depth analysis shows that Peri-LN strikes an ideal balance in variance growth -- unlike Pre-LN and Post-LN, which are prone to vanishing gradients and ``massive activations.'' To validate our theoretical insight, we conduct large-scale experiments on Transformers up to 3.2B parameters, showing that Peri-LN consistently achieves more balanced variance growth, steadier gradient flow, and convergence stability. Our results suggest that Peri-LN warrants broader consideration for large-scale Transformer architectures, providing renewed insights into the optimal placement and application of LN.
Background-Aware Pooling and Noise-Aware Loss for Weakly-Supervised Semantic Segmentation
Apr 02, 2021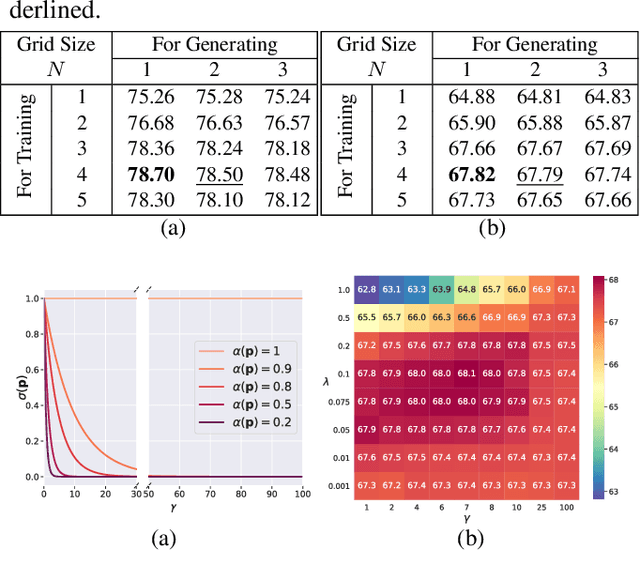

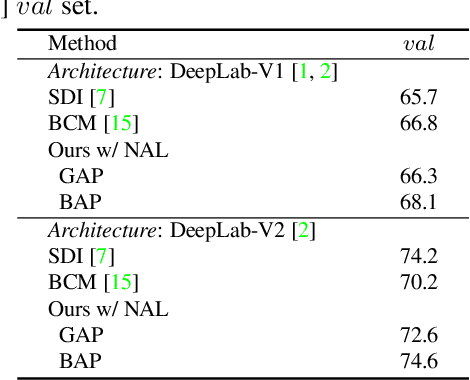
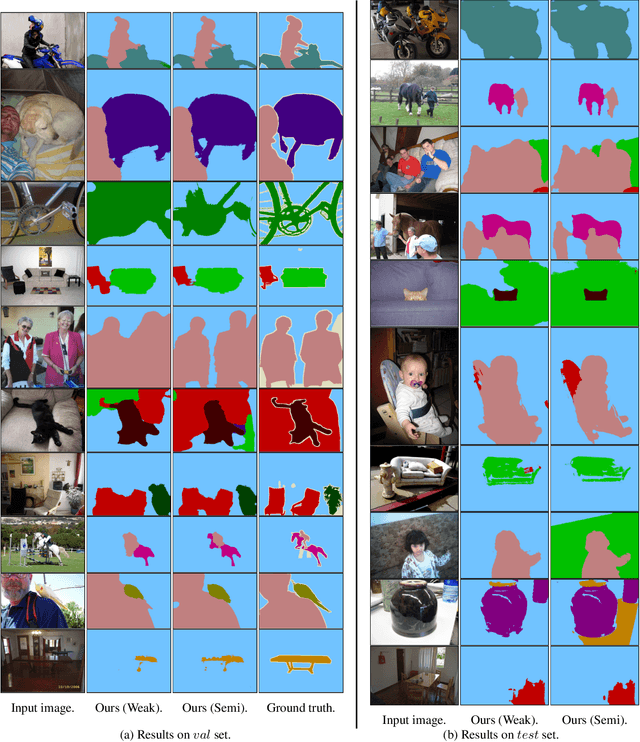
We address the problem of weakly-supervised semantic segmentation (WSSS) using bounding box annotations. Although object bounding boxes are good indicators to segment corresponding objects, they do not specify object boundaries, making it hard to train convolutional neural networks (CNNs) for semantic segmentation. We find that background regions are perceptually consistent in part within an image, and this can be leveraged to discriminate foreground and background regions inside object bounding boxes. To implement this idea, we propose a novel pooling method, dubbed background-aware pooling (BAP), that focuses more on aggregating foreground features inside the bounding boxes using attention maps. This allows to extract high-quality pseudo segmentation labels to train CNNs for semantic segmentation, but the labels still contain noise especially at object boundaries. To address this problem, we also introduce a noise-aware loss (NAL) that makes the networks less susceptible to incorrect labels. Experimental results demonstrate that learning with our pseudo labels already outperforms state-of-the-art weakly- and semi-supervised methods on the PASCAL VOC 2012 dataset, and the NAL further boosts the performance.
Deformable Kernel Networks for Joint Image Filtering
Oct 17, 2019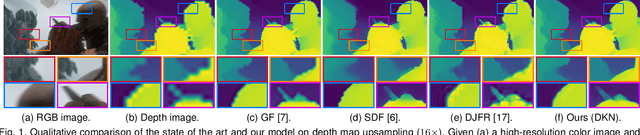
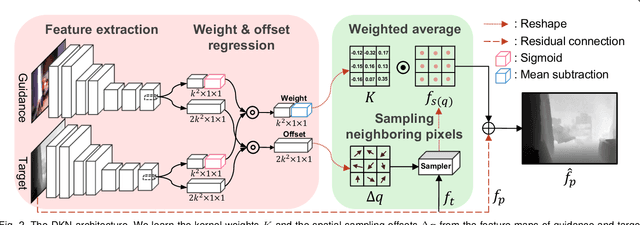

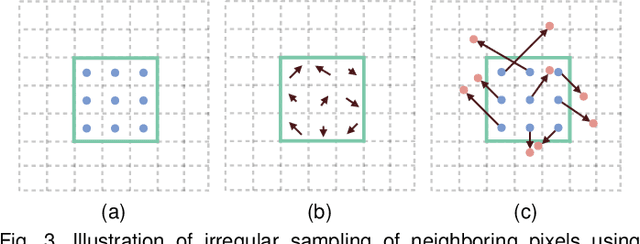
Joint image filters are used to transfer structural details from a guidance picture used as a prior to a target image, in tasks such as enhancing spatial resolution and suppressing noise. Previous methods based on convolutional neural networks (CNNs) combine nonlinear activations of spatially-invariant kernels to estimate structural details and regress the filtering result. In this paper, we instead learn explicitly sparse and spatially-variant kernels. We propose a CNN architecture and its efficient implementation, called the deformable kernel network (DKN), that outputs sets of neighbors and the corresponding weights adaptively for each pixel. The filtering result is then computed as a weighted average. We also propose a fast version of DKN that runs about seventeen times faster for an image of size 640 x 480. We demonstrate the effectiveness and flexibility of our models on the tasks of depth map upsampling, saliency map upsampling, cross-modality image restoration, texture removal, and semantic segmentation. In particular, we show that the weighted averaging process with sparsely sampled 3 x 3 kernels outperforms the state of the art by a significant margin in all cases.
Deformable kernel networks for guided depth map upsampling
Mar 27, 2019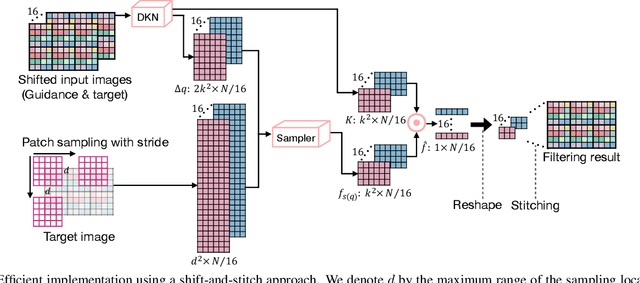

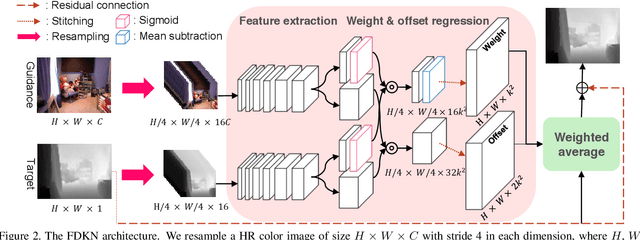
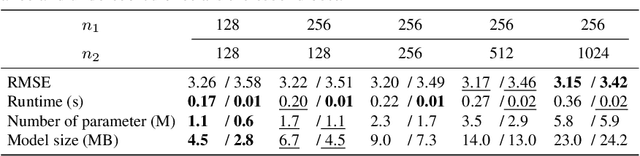
We address the problem of upsampling a low-resolution (LR) depth map using a registered high-resolution (HR) color image of the same scene. Previous methods based on convolutional neural networks (CNNs) combine nonlinear activations of spatially-invariant kernels to estimate structural details from LR depth and HR color images, and regress upsampling results directly from the networks. In this paper, we revisit the weighted averaging process that has been widely used to transfer structural details from hand-crafted visual features to LR depth maps. We instead learn explicitly sparse and spatially-variant kernels for this task. To this end, we propose a CNN architecture and its efficient implementation, called the deformable kernel network (DKN), that outputs sparse sets of neighbors and the corresponding weights adaptively for each pixel. We also propose a fast version of DKN (FDKN) that runs about 17 times faster (0.01 seconds for a HR image of size 640 x 480). Experimental results on standard benchmarks demonstrate the effectiveness of our approach. In particular, we show that the weighted averaging process with 3 x 3 kernels (i.e., aggregating 9 samples sparsely chosen) outperforms the state of the art by a significant margin.