 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexAvatars : Hybrid Texel-3D Representations for Stable Rigging of Photorealistic Gaussian Head Avatars
Dec 24, 2025
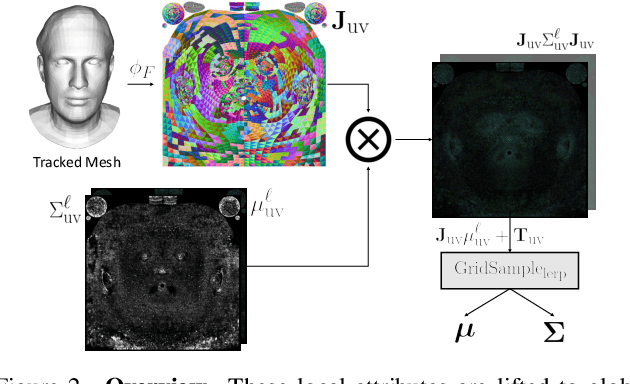


Constructing drivable and photorealistic 3D head avatars has become a central task in AR/XR, enabling immersive and expressive user experiences. With the emergence of high-fidelity and efficient representations such as 3D Gaussians, recent works have pushed toward ultra-detailed head avatars. Existing approaches typically fall into two categories: rule-based analytic rigging or neural network-based deformation fields. While effective in constrained settings, both approaches often fail to generalize to unseen expressions and poses, particularly in extreme reenactment scenarios. Other methods constrain Gaussians to the global texel space of 3DMMs to reduce rendering complexity. However, these texel-based avatars tend to underutilize the underlying mesh structure. They apply minimal analytic deformation and rely heavily on neural regressors and heuristic regularization in UV space, which weakens geometric consistency and limits extrapolation to complex, out-of-distribution deformations. To address these limitations, we introduce TexAvatars, a hybrid avatar representation that combines the explicit geometric grounding of analytic rigging with the spatial continuity of texel space. Our approach predicts local geometric attributes in UV space via CNNs, but drives 3D deformation through mesh-aware Jacobians, enabling smooth and semantically meaningful transitions across triangle boundaries. This hybrid design separates semantic modeling from geometric control, resulting in improved generalization, interpretability, and stability. Furthermore, TexAvatars captures fine-grained expression effects, including muscle-induced wrinkles, glabellar lines, and realistic mouth cavity geometry, with high fidelity. Our method achieves state-of-the-art performance under extreme pose and expression variations, demonstrating strong generalization in challenging head reenactment settings.
Fair Generation without Unfair Distortions: Debiasing Text-to-Image Generation with Entanglement-Free Attention
Jun 16, 2025



Recent advancements in diffusion-based text-to-image (T2I) models have enabled the generation of high-quality and photorealistic images from text descriptions. However, they often exhibit societal biases related to gender, race, and socioeconomic status, thereby reinforcing harmful stereotypes and shaping public perception in unintended ways. While existing bias mitigation methods demonstrate effectiveness, they often encounter attribute entanglement, where adjustments to attributes relevant to the bias (i.e., target attributes) unintentionally alter attributes unassociated with the bias (i.e., non-target attributes), causing undesirable distribution shifts. To address this challenge, we introduce Entanglement-Free Attention (EFA), a method that accurately incorporates target attributes (e.g., White, Black, Asian, and Indian) while preserving non-target attributes (e.g., background details) during bias mitigation. At inference time, EFA randomly samples a target attribute with equal probability and adjusts the cross-attention in selected layers to incorporate the sampled attribute, achieving a fair distribution of target attributes. Extensive experiments demonstrate that EFA outperforms existing methods in mitigating bias while preserving non-target attributes, thereby maintaining the output distribution and generation capability of the original model.
Improving Interpretability and Accuracy in Neuro-Symbolic Rule Extraction Using Class-Specific Sparse Filters
Jan 28, 2025


There has been significant focus on creating neuro-symbolic models for interpretable image classification using Convolutional Neural Networks (CNNs). These methods aim to replace the CNN with a neuro-symbolic model consisting of the CNN, which is used as a feature extractor, and an interpretable rule-set extracted from the CNN itself. While these approaches provide interpretability through the extracted rule-set, they often compromise accuracy compared to the original CNN model. In this paper, we identify the root cause of this accuracy loss as the post-training binarization of filter activations to extract the rule-set. To address this, we propose a novel sparsity loss function that enables class-specific filter binarization during CNN training, thus minimizing information loss when extracting the rule-set. We evaluate several training strategies with our novel sparsity loss, analyzing their effectiveness and providing guidance on their appropriate use. Notably, we set a new benchmark, achieving a 9% improvement in accuracy and a 53% reduction in rule-set size on average, compared to the previous SOTA, while coming within 3% of the original CNN's accuracy. This highlights the significant potential of interpretable neuro-symbolic models as viable alternatives to black-box CNNs.
Interventional Speech Noise Injection for ASR Generalizable Spoken Language Understanding
Oct 21, 2024Recently, pre-trained language models (PLMs) have been increasingly adopted in spoken language understanding (SLU). However, automatic speech recognition (ASR) systems frequently produce inaccurate transcriptions, leading to noisy inputs for SLU models, which can significantly degrade their performance. To address this, our objective is to train SLU models to withstand ASR errors by exposing them to noises commonly observed in ASR systems, referred to as ASR-plausible noises. Speech noise injection (SNI) methods have pursued this objective by introducing ASR-plausible noises, but we argue that these methods are inherently biased towards specific ASR systems, or ASR-specific noises. In this work, we propose a novel and less biased augmentation method of introducing the noises that are plausible to any ASR system, by cutting off the non-causal effect of noises. Experimental results and analyses demonstrate the effectiveness of our proposed methods in enhancing the robustness and generalizability of SLU models against unseen ASR systems by introducing more diverse and plausible ASR noises in advance.
SurFhead: Affine Rig Blending for Geometrically Accurate 2D Gaussian Surfel Head Avatars
Oct 15, 2024


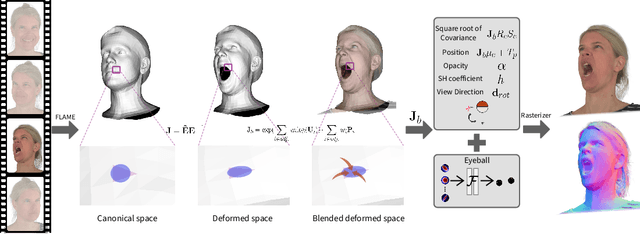
Recent advancements in head avatar rendering using Gaussian primitives have achieved significantly high-fidelity results. Although precise head geometry is crucial for applications like mesh reconstruction and relighting, current methods struggle to capture intricate geometric details and render unseen poses due to their reliance on similarity transformations, which cannot handle stretch and shear transforms essential for detailed deformations of geometry. To address this, we propose SurFhead, a novel method that reconstructs riggable head geometry from RGB videos using 2D Gaussian surfels, which offer well-defined geometric properties, such as precise depth from fixed ray intersections and normals derived from their surface orientation, making them advantageous over 3D counterparts. SurFhead ensures high-fidelity rendering of both normals and images, even in extreme poses, by leveraging classical mesh-based deformation transfer and affine transformation interpolation. SurFhead introduces precise geometric deformation and blends surfels through polar decomposition of transformations, including those affecting normals. Our key contribution lies in bridging classical graphics techniques, such as mesh-based deformation, with modern Gaussian primitives, achieving state-of-the-art geometry reconstruction and rendering quality. Unlike previous avatar rendering approaches, SurFhead enables efficient reconstruction driven by Gaussian primitives while preserving high-fidelity geometry.
STUN: Structured-Then-Unstructured Pruning for Scalable MoE Pruning
Sep 10, 2024



Mixture-of-experts (MoEs) have been adopted for reducing inference costs by sparsely activating experts in Large language models (LLMs). Despite this reduction, the massive number of experts in MoEs still makes them expensive to serve. In this paper, we study how to address this, by pruning MoEs. Among pruning methodologies, unstructured pruning has been known to achieve the highest performance for a given pruning ratio, compared to structured pruning, since the latter imposes constraints on the sparsification structure. This is intuitive, as the solution space of unstructured pruning subsumes that of structured pruning. However, our counterintuitive finding reveals that expert pruning, a form of structured pruning, can actually precede unstructured pruning to outperform unstructured-only pruning. As existing expert pruning, requiring $O(\frac{k^n}{\sqrt{n}})$ forward passes for $n$ experts, cannot scale for recent MoEs, we propose a scalable alternative with $O(1)$ complexity, yet outperforming the more expensive methods. The key idea is leveraging a latent structure between experts, based on behavior similarity, such that the greedy decision of whether to prune closely captures the joint pruning effect. Ours is highly effective -- for Snowflake Arctic, a 480B-sized MoE with 128 experts, our method needs only one H100 and two hours to achieve nearly no loss in performance with 40% sparsity, even in generative tasks such as GSM8K, where state-of-the-art unstructured pruning fails to. The code will be made publicly available.
Effective Rank Analysis and Regularization for Enhanced 3D Gaussian Splatting
Jun 18, 2024



3D reconstruction from multi-view images is one of the fundamental challenges in computer vision and graphics. Recently, 3D Gaussian Splatting (3DGS) has emerged as a promising technique capable of real-time rendering with high-quality 3D reconstruction. This method utilizes 3D Gaussian representation and tile-based splatting techniques, bypassing the expensive neural field querying. Despite its potential, 3DGS encounters challenges, including needle-like artifacts, suboptimal geometries, and inaccurate normals, due to the Gaussians converging into anisotropic Gaussians with one dominant variance. We propose using effective rank analysis to examine the shape statistics of 3D Gaussian primitives, and identify the Gaussians indeed converge into needle-like shapes with the effective rank 1. To address this, we introduce effective rank as a regularization, which constrains the structure of the Gaussians. Our new regularization method enhances normal and geometry reconstruction while reducing needle-like artifacts. The approach can be integrated as an add-on module to other 3DGS variants, improving their quality without compromising visual fidelity.
SelfSwapper: Self-Supervised Face Swapping via Shape Agnostic Masked AutoEncoder
Feb 12, 2024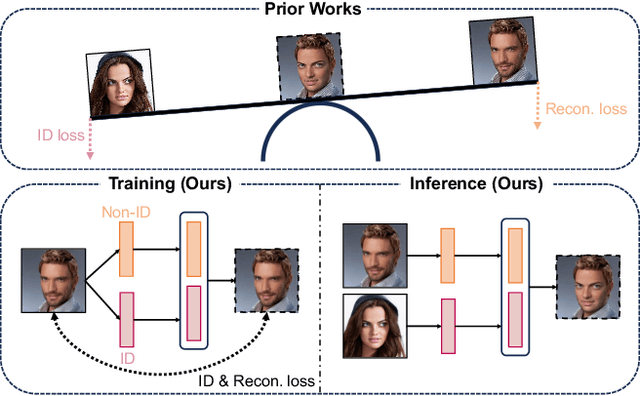
Face swapping has gained significant attention for its varied applications. The majority of previous face swapping approaches have relied on the seesaw game training scheme, which often leads to the instability of the model training and results in undesired samples with blended identities due to the target identity leakage problem. This paper introduces the Shape Agnostic Masked AutoEncoder (SAMAE) training scheme, a novel self-supervised approach designed to enhance face swapping model training. Our training scheme addresses the limitations of traditional training methods by circumventing the conventional seesaw game and introducing clear ground truth through its self-reconstruction training regime. It effectively mitigates identity leakage by masking facial regions of the input images and utilizing learned disentangled identity and non-identity features. Additionally, we tackle the shape misalignment problem with new techniques including perforation confusion and random mesh scaling, and establishes a new state-of-the-art, surpassing other baseline methods, preserving both identity and non-identity attributes, without sacrificing on either aspect.
Expression Domain Translation Network for Cross-domain Head Reenactment
Nov 06, 2023

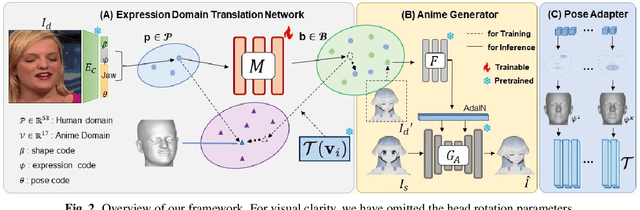

Despite the remarkable advancements in head reenactment, the existing methods face challenges in cross-domain head reenactment, which aims to transfer human motions to domains outside the human, including cartoon characters. It is still difficult to extract motion from out-of-domain images due to the distinct appearances, such as large eyes. Recently, previous work introduced a large-scale anime dataset called AnimeCeleb and a cross-domain head reenactment model, including an optimization-based mapping function to translate the human domain's expressions to the anime domain. However, we found that the mapping function, which relies on a subset of expressions, imposes limitations on the mapping of various expressions. To solve this challenge, we introduce a novel expression domain translation network that transforms human expressions into anime expressions. Specifically, to maintain the geometric consistency of expressions between the input and output of the expression domain translation network, we employ a 3D geometric-aware loss function that reduces the distances between the vertices in the 3D mesh of the human and anime. By doing so, it forces high-fidelity and one-to-one mapping with respect to two cross-expression domains. Our method outperforms existing methods in both qualitative and quantitative analysis, marking a significant advancement in the field of cross-domain head reenactment.
PixelHuman: Animatable Neural Radiance Fields from Few Images
Jul 18, 2023

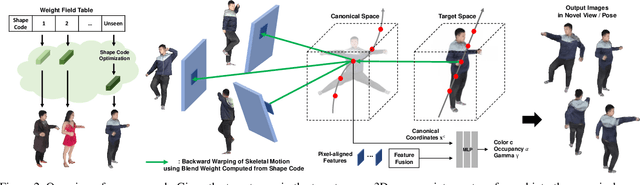

In this paper, we propose PixelHuman, a novel human rendering model that generates animatable human scenes from a few images of a person with unseen identity, views, and poses. Previous work have demonstrated reasonable performance in novel view and pose synthesis, but they rely on a large number of images to train and are trained per scene from videos, which requires significant amount of time to produce animatable scenes from unseen human images. Our method differs from existing methods in that it can generalize to any input image for animatable human synthesis. Given a random pose sequence, our method synthesizes each target scene using a neural radiance field that is conditioned on a canonical representation and pose-aware pixel-aligned features, both of which can be obtained through deformation fields learned in a data-driven manner. Our experiments show that our method achieves state-of-the-art performance in multiview and novel pose synthesis from few-shot images.