 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpression Domain Translation Network for Cross-domain Head Reenactment
Paper and Code


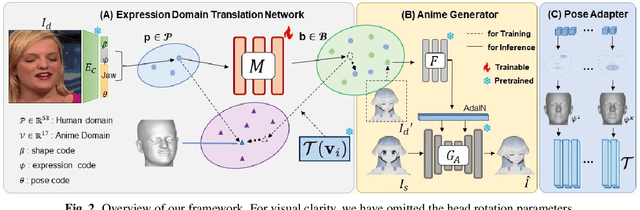

Despite the remarkable advancements in head reenactment, the existing methods face challenges in cross-domain head reenactment, which aims to transfer human motions to domains outside the human, including cartoon characters. It is still difficult to extract motion from out-of-domain images due to the distinct appearances, such as large eyes. Recently, previous work introduced a large-scale anime dataset called AnimeCeleb and a cross-domain head reenactment model, including an optimization-based mapping function to translate the human domain's expressions to the anime domain. However, we found that the mapping function, which relies on a subset of expressions, imposes limitations on the mapping of various expressions. To solve this challenge, we introduce a novel expression domain translation network that transforms human expressions into anime expressions. Specifically, to maintain the geometric consistency of expressions between the input and output of the expression domain translation network, we employ a 3D geometric-aware loss function that reduces the distances between the vertices in the 3D mesh of the human and anime. By doing so, it forces high-fidelity and one-to-one mapping with respect to two cross-expression domains. Our method outperforms existing methods in both qualitative and quantitative analysis, marking a significant advancement in the field of cross-domain head reenactment.