 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic Rule Extraction from Attention-Guided Sparse Representations in Vision Transformers
May 10, 2025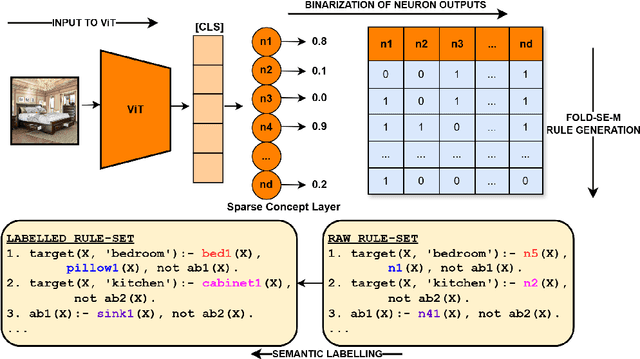
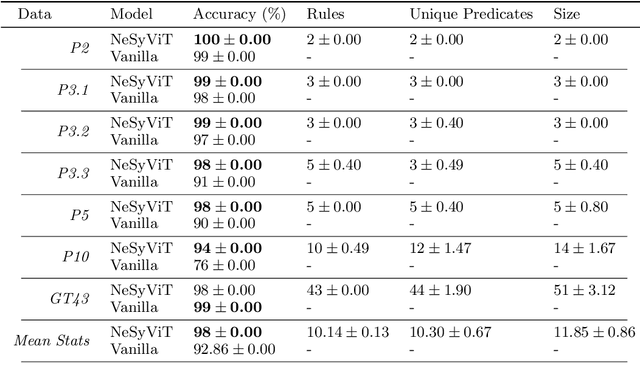
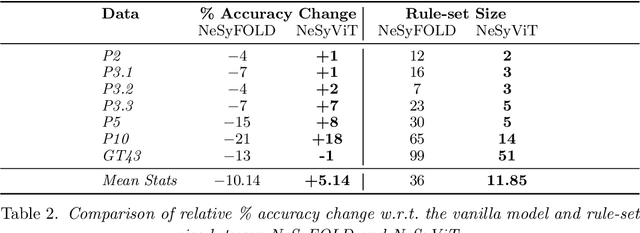

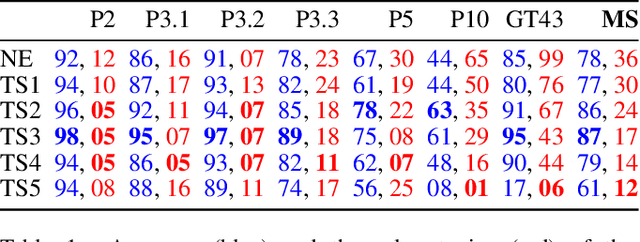
Recent neuro-symbolic approaches have successfully extracted symbolic rule-sets from CNN-based models to enhance interpretability. However, applying similar techniques to Vision Transformers (ViTs) remains challenging due to their lack of modular concept detectors and reliance on global self-attention mechanisms. We propose a framework for symbolic rule extraction from ViTs by introducing a sparse concept layer inspired by Sparse Autoencoders (SAEs). This linear layer operates on attention-weighted patch representations and learns a disentangled, binarized representation in which individual neurons activate for high-level visual concepts. To encourage interpretability, we apply a combination of L1 sparsity, entropy minimization, and supervised contrastive loss. These binarized concept activations are used as input to the FOLD-SE-M algorithm, which generates a rule-set in the form of logic programs. Our method achieves a 5.14% better classification accuracy than the standard ViT while enabling symbolic reasoning. Crucially, the extracted rule-set is not merely post-hoc but acts as a logic-based decision layer that operates directly on the sparse concept representations. The resulting programs are concise and semantically meaningful. This work is the first to extract executable logic programs from ViTs using sparse symbolic representations. It bridges the gap between transformer-based vision models and symbolic logic programming, providing a step forward in interpretable and verifiable neuro-symbolic AI.
Improving Interpretability and Accuracy in Neuro-Symbolic Rule Extraction Using Class-Specific Sparse Filters
Jan 28, 2025


There has been significant focus on creating neuro-symbolic models for interpretable image classification using Convolutional Neural Networks (CNNs). These methods aim to replace the CNN with a neuro-symbolic model consisting of the CNN, which is used as a feature extractor, and an interpretable rule-set extracted from the CNN itself. While these approaches provide interpretability through the extracted rule-set, they often compromise accuracy compared to the original CNN model. In this paper, we identify the root cause of this accuracy loss as the post-training binarization of filter activations to extract the rule-set. To address this, we propose a novel sparsity loss function that enables class-specific filter binarization during CNN training, thus minimizing information loss when extracting the rule-set. We evaluate several training strategies with our novel sparsity loss, analyzing their effectiveness and providing guidance on their appropriate use. Notably, we set a new benchmark, achieving a 9% improvement in accuracy and a 53% reduction in rule-set size on average, compared to the previous SOTA, while coming within 3% of the original CNN's accuracy. This highlights the significant potential of interpretable neuro-symbolic models as viable alternatives to black-box CNNs.
A Neurosymbolic Framework for Bias Correction in CNNs
May 24, 2024


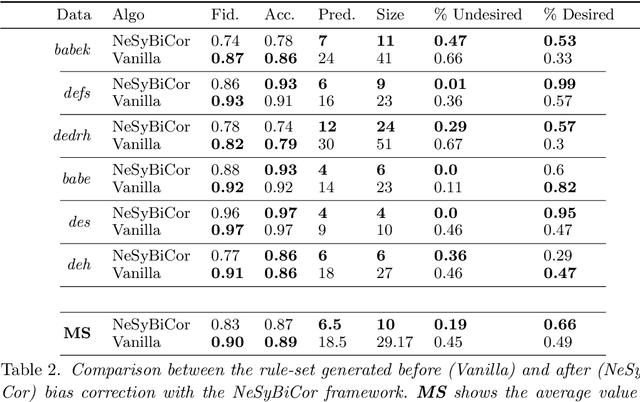
Recent efforts in interpreting Convolutional Neural Networks (CNNs) focus on translating the activation of CNN filters into stratified Answer Set Programming (ASP) rule-sets. The CNN filters are known to capture high-level image concepts, thus the predicates in the rule-set are mapped to the concept that their corresponding filter represents. Hence, the rule-set effectively exemplifies the decision-making process of the CNN in terms of the concepts that it learns for any image classification task. These rule-sets help expose and understand the biases in CNNs, although correcting the biases effectively remains a challenge. We introduce a neurosymbolic framework called NeSyBiCor for bias correction in a trained CNN. Given symbolic concepts that the CNN is biased towards, expressed as ASP constraints, we convert the undesirable and desirable concepts to their corresponding vector representations. Then, the CNN is retrained using our novel semantic similarity loss that pushes the filters away from the representations of concepts that are undesirable while pushing them closer to the concepts that are desirable. The final ASP rule-set obtained after retraining, satisfies the constraints to a high degree, thus showing the revision in the knowledge of the CNN for the image classification task. We demonstrate that our NeSyBiCor framework successfully corrects the biases of CNNs trained with subsets of classes from the Places dataset while sacrificing minimal accuracy and improving interpretability, by greatly decreasing the size of the final bias-corrected rule-set w.r.t. the initial rule-set.
Using Logic Programming and Kernel-Grouping for Improving Interpretability of Convolutional Neural Networks
Oct 19, 2023Within the realm of deep learning, the interpretability of Convolutional Neural Networks (CNNs), particularly in the context of image classification tasks, remains a formidable challenge. To this end we present a neurosymbolic framework, NeSyFOLD-G that generates a symbolic rule-set using the last layer kernels of the CNN to make its underlying knowledge interpretable. What makes NeSyFOLD-G different from other similar frameworks is that we first find groups of similar kernels in the CNN (kernel-grouping) using the cosine-similarity between the feature maps generated by various kernels. Once such kernel groups are found, we binarize each kernel group's output in the CNN and use it to generate a binarization table which serves as input data to FOLD-SE-M which is a Rule Based Machine Learning (RBML) algorithm. FOLD-SE-M then generates a rule-set that can be used to make predictions. We present a novel kernel grouping algorithm and show that grouping similar kernels leads to a significant reduction in the size of the rule-set generated by FOLD-SE-M, consequently, improving the interpretability. This rule-set symbolically encapsulates the connectionist knowledge of the trained CNN. The rule-set can be viewed as a normal logic program wherein each predicate's truth value depends on a kernel group in the CNN. Each predicate in the rule-set is mapped to a concept using a few semantic segmentation masks of the images used for training, to make it human-understandable. The last layers of the CNN can then be replaced by this rule-set to obtain the NeSy-G model which can then be used for the image classification task. The goal directed ASP system s(CASP) can be used to obtain the justification of any prediction made using the NeSy-G model. We also propose a novel algorithm for labeling each predicate in the rule-set with the semantic concept(s) that its corresponding kernel group represents.
Automated Interactive Domain-Specific Conversational Agents that Understand Human Dialogs
Mar 17, 2023Achieving human-like communication with machines remains a classic, challenging topic in the field of Knowledge Representation and Reasoning and Natural Language Processing. These Large Language Models (LLMs) rely on pattern-matching rather than a true understanding of the semantic meaning of a sentence. As a result, they may generate incorrect responses. To generate an assuredly correct response, one has to "understand" the semantics of a sentence. To achieve this "understanding", logic-based (commonsense) reasoning methods such as Answer Set Programming (ASP) are arguably needed. In this paper, we describe the AutoConcierge system that leverages LLMs and ASP to develop a conversational agent that can truly "understand" human dialogs in restricted domains. AutoConcierge is focused on a specific domain-advising users about restaurants in their local area based on their preferences. AutoConcierge will interactively understand a user's utterances, identify the missing information in them, and request the user via a natural language sentence to provide it. Once AutoConcierge has determined that all the information has been received, it computes a restaurant recommendation based on the user-preferences it has acquired from the human user. AutoConcierge is based on our STAR framework developed earlier, which uses GPT-3 to convert human dialogs into predicates that capture the deep structure of the dialog's sentence. These predicates are then input into the goal-directed s(CASP) ASP system for performing commonsense reasoning. To the best of our knowledge, AutoConcierge is the first automated conversational agent that can realistically converse like a human and provide help to humans based on truly understanding human utterances.
Reliable Natural Language Understanding with Large Language Models and Answer Set Programming
Feb 09, 2023Humans understand language by extracting information (meaning) from sentences, combining it with existing commonsense knowledge, and then performing reasoning to draw conclusions. While large language models (LLMs) such as GPT-3 and ChatGPT are able to leverage patterns in the text to solve a variety of NLP tasks, they fall short in problems that require reasoning. They also cannot reliably explain the answers generated for a given question. In order to emulate humans better, we propose STAR, a framework that combines LLMs with Answer Set Programming (ASP). We show how LLMs can be used to effectively extract knowledge -- represented as predicates -- from language. Goal-directed ASP is then employed to reliably reason over this knowledge. We apply the STAR framework to three different NLU tasks requiring reasoning: qualitative reasoning, mathematical reasoning, and goal-directed conversation. Our experiments reveal that STAR is able to bridge the gap of reasoning in NLU tasks, leading to significant performance improvements, especially for smaller LLMs, i.e., LLMs with a smaller number of parameters. NLU applications developed using the STAR framework are also explainable: along with the predicates generated, a justification in the form of a proof tree can be produced for a given output.
MACOptions: Multi-Agent Learning with Centralized Controller and Options Framework
Feb 07, 2023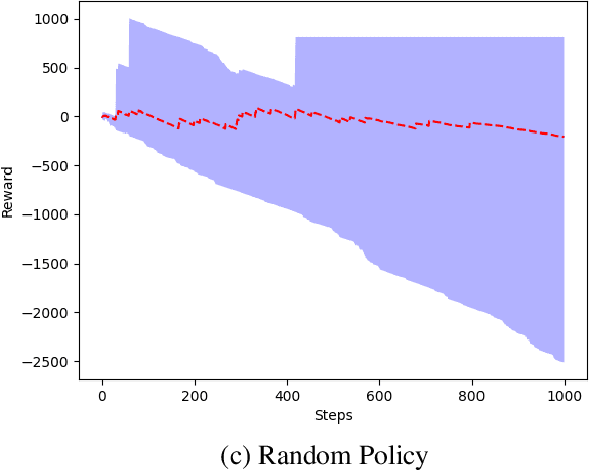
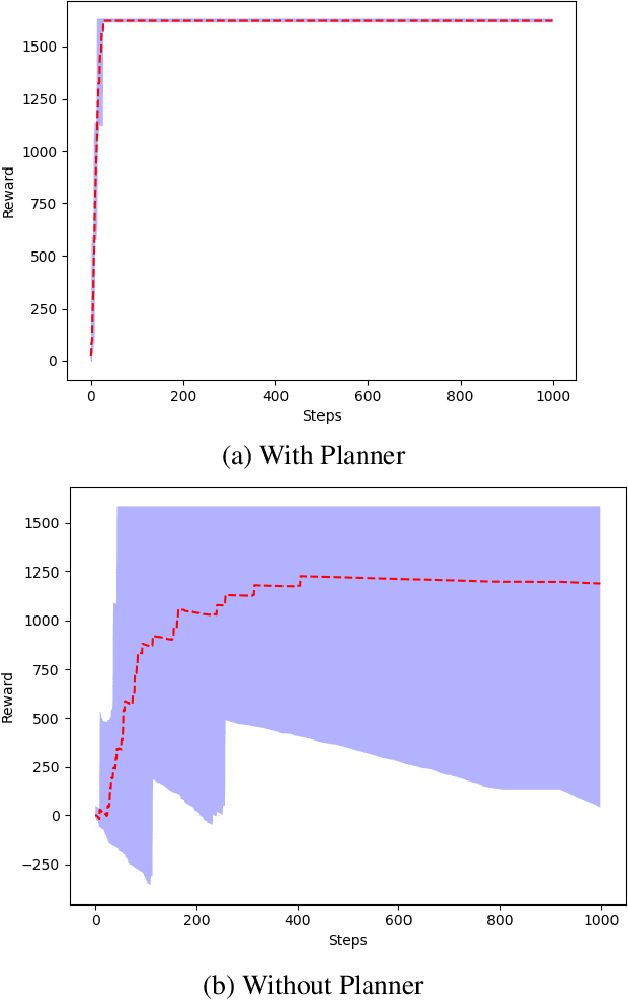
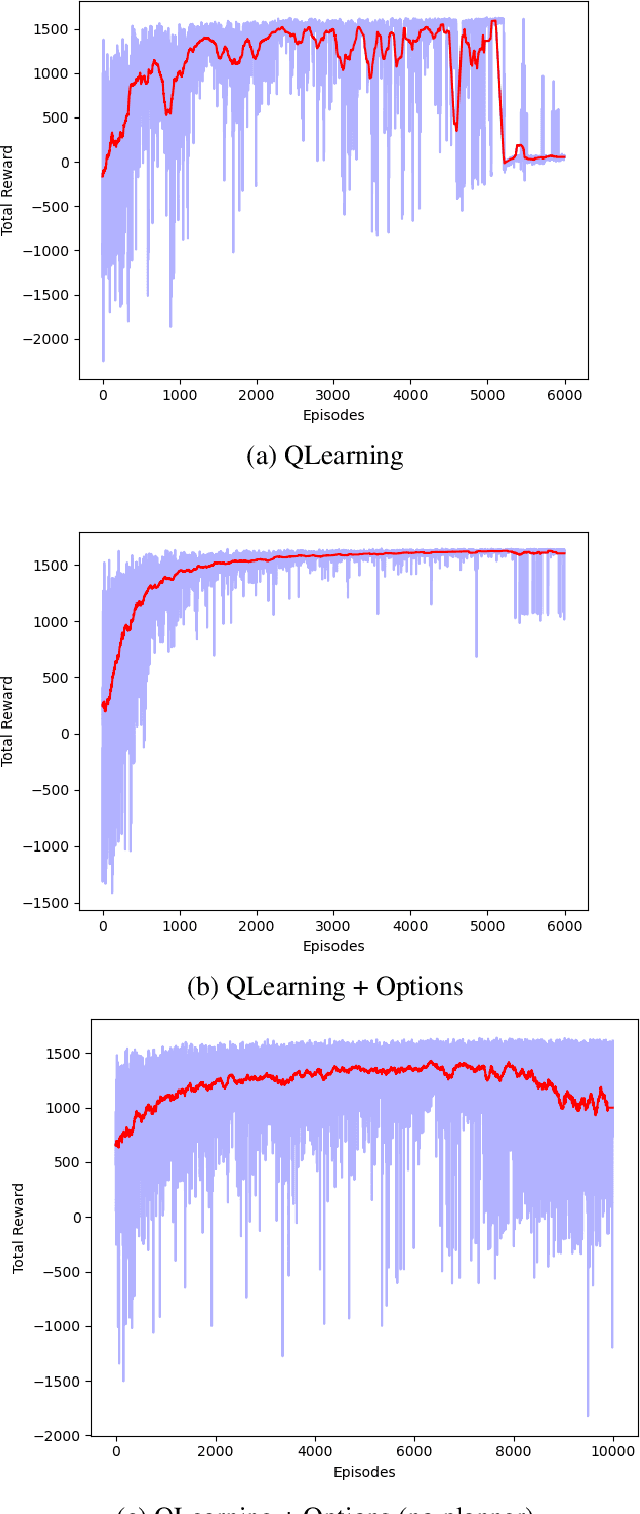
These days automation is being applied everywhere. In every environment, planning for the actions to be taken by the agents is an important aspect. In this paper, we plan to implement planning for multi-agents with a centralized controller. We compare three approaches: random policy, Q-learning, and Q-learning with Options Framework. We also show the effectiveness of planners by showing performance comparison between Q-Learning with Planner and without Planner.
NeSyFOLD: A System for Generating Logic-based Explanations from Convolutional Neural Networks
Jan 30, 2023



We present a novel neurosymbolic system called NeSyFOLD that classifies images while providing a logic-based explanation of the classification. NeSyFOLD's training process is as follows: (i) We first pre-train a CNN on the input image dataset and extract activations of the last layer filters as binary values; (ii) Next, we use the FOLD-SE-M rule-based machine learning algorithm to generate a logic program that can classify an image -- represented as a vector of binary activations corresponding to each filter -- while producing a logical explanation. The rules generated by the FOLD-SE-M algorithm have filter numbers as predicates. We use a novel algorithm that we have devised for automatically mapping the CNN filters to semantic concepts in the images. This mapping is used to replace predicate names (filter numbers) in the rule-set with corresponding semantic concept labels. The resulting rule-set is highly interpretable, and can be intuitively understood by humans. We compare our NeSyFOLD system with the ERIC system that uses a decision-tree like algorithm to obtain the rules. Our system has the following advantages over ERIC: (i) NeSyFOLD generates smaller rule-sets without compromising on the accuracy and fidelity; (ii) NeSyFOLD generates the mapping of filter numbers to semantic labels automatically.