 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsertAnywhere: Bridging 4D Scene Geometry and Diffusion Models for Realistic Video Object Insertion
Dec 19, 2025Recent advances in diffusion-based video generation have opened new possibilities for controllable video editing, yet realistic video object insertion (VOI) remains challenging due to limited 4D scene understanding and inadequate handling of occlusion and lighting effects. We present InsertAnywhere, a new VOI framework that achieves geometrically consistent object placement and appearance-faithful video synthesis. Our method begins with a 4D aware mask generation module that reconstructs the scene geometry and propagates user specified object placement across frames while maintaining temporal coherence and occlusion consistency. Building upon this spatial foundation, we extend a diffusion based video generation model to jointly synthesize the inserted object and its surrounding local variations such as illumination and shading. To enable supervised training, we introduce ROSE++, an illumination aware synthetic dataset constructed by transforming the ROSE object removal dataset into triplets of object removed video, object present video, and a VLM generated reference image. Through extensive experiments, we demonstrate that our framework produces geometrically plausible and visually coherent object insertions across diverse real world scenarios, significantly outperforming existing research and commercial models.
Infinite-Homography as Robust Conditioning for Camera-Controlled Video Generation
Dec 18, 2025



Recent progress in video diffusion models has spurred growing interest in camera-controlled novel-view video generation for dynamic scenes, aiming to provide creators with cinematic camera control capabilities in post-production. A key challenge in camera-controlled video generation is ensuring fidelity to the specified camera pose, while maintaining view consistency and reasoning about occluded geometry from limited observations. To address this, existing methods either train trajectory-conditioned video generation model on trajectory-video pair dataset, or estimate depth from the input video to reproject it along a target trajectory and generate the unprojected regions. Nevertheless, existing methods struggle to generate camera-pose-faithful, high-quality videos for two main reasons: (1) reprojection-based approaches are highly susceptible to errors caused by inaccurate depth estimation; and (2) the limited diversity of camera trajectories in existing datasets restricts learned models. To address these limitations, we present InfCam, a depth-free, camera-controlled video-to-video generation framework with high pose fidelity. The framework integrates two key components: (1) infinite homography warping, which encodes 3D camera rotations directly within the 2D latent space of a video diffusion model. Conditioning on this noise-free rotational information, the residual parallax term is predicted through end-to-end training to achieve high camera-pose fidelity; and (2) a data augmentation pipeline that transforms existing synthetic multiview datasets into sequences with diverse trajectories and focal lengths. Experimental results demonstrate that InfCam outperforms baseline methods in camera-pose accuracy and visual fidelity, generalizing well from synthetic to real-world data. Link to our project page:https://emjay73.github.io/InfCam/
EgoX: Egocentric Video Generation from a Single Exocentric Video
Dec 09, 2025Egocentric perception enables humans to experience and understand the world directly from their own point of view. Translating exocentric (third-person) videos into egocentric (first-person) videos opens up new possibilities for immersive understanding but remains highly challenging due to extreme camera pose variations and minimal view overlap. This task requires faithfully preserving visible content while synthesizing unseen regions in a geometrically consistent manner. To achieve this, we present EgoX, a novel framework for generating egocentric videos from a single exocentric input. EgoX leverages the pretrained spatio temporal knowledge of large-scale video diffusion models through lightweight LoRA adaptation and introduces a unified conditioning strategy that combines exocentric and egocentric priors via width and channel wise concatenation. Additionally, a geometry-guided self-attention mechanism selectively attends to spatially relevant regions, ensuring geometric coherence and high visual fidelity. Our approach achieves coherent and realistic egocentric video generation while demonstrating strong scalability and robustness across unseen and in-the-wild videos.
Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling
Nov 27, 2024



Diffusion models have emerged as a powerful tool for generating high-quality images, videos, and 3D content. While sampling guidance techniques like CFG improve quality, they reduce diversity and motion. Autoguidance mitigates these issues but demands extra weak model training, limiting its practicality for large-scale models. In this work, we introduce Spatiotemporal Skip Guidance (STG), a simple training-free sampling guidance method for enhancing transformer-based video diffusion models. STG employs an implicit weak model via self-perturbation, avoiding the need for external models or additional training. By selectively skipping spatiotemporal layers, STG produces an aligned, degraded version of the original model to boost sample quality without compromising diversity or dynamic degree. Our contributions include: (1) introducing STG as an efficient, high-performing guidance technique for video diffusion models, (2) eliminating the need for auxiliary models by simulating a weak model through layer skipping, and (3) ensuring quality-enhanced guidance without compromising sample diversity or dynamics unlike CFG. For additional results, visit https://junhahyung.github.io/STGuidance.
SurFhead: Affine Rig Blending for Geometrically Accurate 2D Gaussian Surfel Head Avatars
Oct 15, 2024


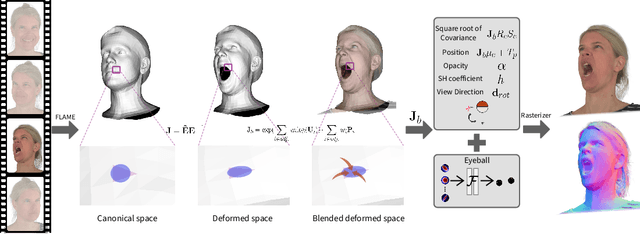
Recent advancements in head avatar rendering using Gaussian primitives have achieved significantly high-fidelity results. Although precise head geometry is crucial for applications like mesh reconstruction and relighting, current methods struggle to capture intricate geometric details and render unseen poses due to their reliance on similarity transformations, which cannot handle stretch and shear transforms essential for detailed deformations of geometry. To address this, we propose SurFhead, a novel method that reconstructs riggable head geometry from RGB videos using 2D Gaussian surfels, which offer well-defined geometric properties, such as precise depth from fixed ray intersections and normals derived from their surface orientation, making them advantageous over 3D counterparts. SurFhead ensures high-fidelity rendering of both normals and images, even in extreme poses, by leveraging classical mesh-based deformation transfer and affine transformation interpolation. SurFhead introduces precise geometric deformation and blends surfels through polar decomposition of transformations, including those affecting normals. Our key contribution lies in bridging classical graphics techniques, such as mesh-based deformation, with modern Gaussian primitives, achieving state-of-the-art geometry reconstruction and rendering quality. Unlike previous avatar rendering approaches, SurFhead enables efficient reconstruction driven by Gaussian primitives while preserving high-fidelity geometry.
Effective Rank Analysis and Regularization for Enhanced 3D Gaussian Splatting
Jun 18, 2024



3D reconstruction from multi-view images is one of the fundamental challenges in computer vision and graphics. Recently, 3D Gaussian Splatting (3DGS) has emerged as a promising technique capable of real-time rendering with high-quality 3D reconstruction. This method utilizes 3D Gaussian representation and tile-based splatting techniques, bypassing the expensive neural field querying. Despite its potential, 3DGS encounters challenges, including needle-like artifacts, suboptimal geometries, and inaccurate normals, due to the Gaussians converging into anisotropic Gaussians with one dominant variance. We propose using effective rank analysis to examine the shape statistics of 3D Gaussian primitives, and identify the Gaussians indeed converge into needle-like shapes with the effective rank 1. To address this, we introduce effective rank as a regularization, which constrains the structure of the Gaussians. Our new regularization method enhances normal and geometry reconstruction while reducing needle-like artifacts. The approach can be integrated as an add-on module to other 3DGS variants, improving their quality without compromising visual fidelity.
SelfSwapper: Self-Supervised Face Swapping via Shape Agnostic Masked AutoEncoder
Feb 12, 2024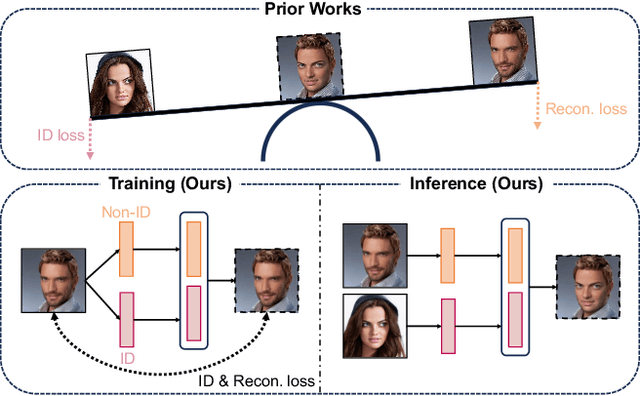
Face swapping has gained significant attention for its varied applications. The majority of previous face swapping approaches have relied on the seesaw game training scheme, which often leads to the instability of the model training and results in undesired samples with blended identities due to the target identity leakage problem. This paper introduces the Shape Agnostic Masked AutoEncoder (SAMAE) training scheme, a novel self-supervised approach designed to enhance face swapping model training. Our training scheme addresses the limitations of traditional training methods by circumventing the conventional seesaw game and introducing clear ground truth through its self-reconstruction training regime. It effectively mitigates identity leakage by masking facial regions of the input images and utilizing learned disentangled identity and non-identity features. Additionally, we tackle the shape misalignment problem with new techniques including perforation confusion and random mesh scaling, and establishes a new state-of-the-art, surpassing other baseline methods, preserving both identity and non-identity attributes, without sacrificing on either aspect.
MagiCapture: High-Resolution Multi-Concept Portrait Customization
Sep 13, 2023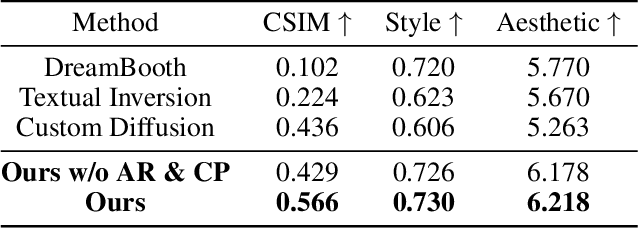
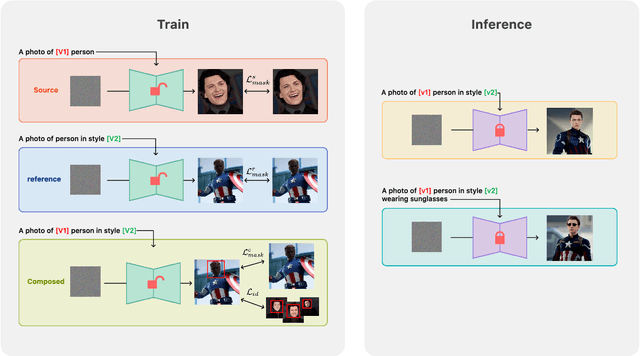
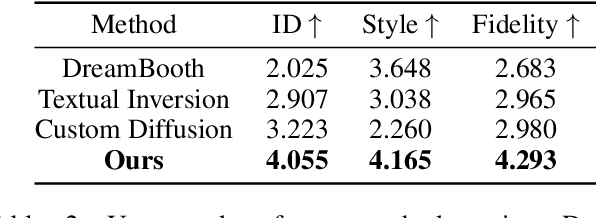

Large-scale text-to-image models including Stable Diffusion are capable of generating high-fidelity photorealistic portrait images. There is an active research area dedicated to personalizing these models, aiming to synthesize specific subjects or styles using provided sets of reference images. However, despite the plausible results from these personalization methods, they tend to produce images that often fall short of realism and are not yet on a commercially viable level. This is particularly noticeable in portrait image generation, where any unnatural artifact in human faces is easily discernible due to our inherent human bias. To address this, we introduce MagiCapture, a personalization method for integrating subject and style concepts to generate high-resolution portrait images using just a few subject and style references. For instance, given a handful of random selfies, our fine-tuned model can generate high-quality portrait images in specific styles, such as passport or profile photos. The main challenge with this task is the absence of ground truth for the composed concepts, leading to a reduction in the quality of the final output and an identity shift of the source subject. To address these issues, we present a novel Attention Refocusing loss coupled with auxiliary priors, both of which facilitate robust learning within this weakly supervised learning setting. Our pipeline also includes additional post-processing steps to ensure the creation of highly realistic outputs. MagiCapture outperforms other baselines in both quantitative and qualitative evaluations and can also be generalized to other non-human objects.
Text2Control3D: Controllable 3D Avatar Generation in Neural Radiance Fields using Geometry-Guided Text-to-Image Diffusion Model
Sep 07, 2023Recent advances in diffusion models such as ControlNet have enabled geometrically controllable, high-fidelity text-to-image generation. However, none of them addresses the question of adding such controllability to text-to-3D generation. In response, we propose Text2Control3D, a controllable text-to-3D avatar generation method whose facial expression is controllable given a monocular video casually captured with hand-held camera. Our main strategy is to construct the 3D avatar in Neural Radiance Fields (NeRF) optimized with a set of controlled viewpoint-aware images that we generate from ControlNet, whose condition input is the depth map extracted from the input video. When generating the viewpoint-aware images, we utilize cross-reference attention to inject well-controlled, referential facial expression and appearance via cross attention. We also conduct low-pass filtering of Gaussian latent of the diffusion model in order to ameliorate the viewpoint-agnostic texture problem we observed from our empirical analysis, where the viewpoint-aware images contain identical textures on identical pixel positions that are incomprehensible in 3D. Finally, to train NeRF with the images that are viewpoint-aware yet are not strictly consistent in geometry, our approach considers per-image geometric variation as a view of deformation from a shared 3D canonical space. Consequently, we construct the 3D avatar in a canonical space of deformable NeRF by learning a set of per-image deformation via deformation field table. We demonstrate the empirical results and discuss the effectiveness of our method.
FaceCLIPNeRF: Text-driven 3D Face Manipulation using Deformable Neural Radiance Fields
Aug 07, 2023



As recent advances in Neural Radiance Fields (NeRF) have enabled high-fidelity 3D face reconstruction and novel view synthesis, its manipulation also became an essential task in 3D vision. However, existing manipulation methods require extensive human labor, such as a user-provided semantic mask and manual attribute search unsuitable for non-expert users. Instead, our approach is designed to require a single text to manipulate a face reconstructed with NeRF. To do so, we first train a scene manipulator, a latent code-conditional deformable NeRF, over a dynamic scene to control a face deformation using the latent code. However, representing a scene deformation with a single latent code is unfavorable for compositing local deformations observed in different instances. As so, our proposed Position-conditional Anchor Compositor (PAC) learns to represent a manipulated scene with spatially varying latent codes. Their renderings with the scene manipulator are then optimized to yield high cosine similarity to a target text in CLIP embedding space for text-driven manipulation. To the best of our knowledge, our approach is the first to address the text-driven manipulation of a face reconstructed with NeRF. Extensive results, comparisons, and ablation studies demonstrate the effectiveness of our approach.