 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCSB: Layer-Cyclic Selective Backpropagation for Memory-Efficient On-Device LLM Fine-Tuning
Feb 13, 2026Memory-efficient backpropagation (MeBP) has enabled first-order fine-tuning of large language models (LLMs) on mobile devices with less than 1GB memory. However, MeBP requires backward computation through all transformer layers at every step, where weight decompression alone accounts for 32--42% of backward time. We propose Layer-Cyclic Selective Backpropagation (LCSB), which computes gradients for only a subset of layers per step. Our key insight is that residual connections guarantee gradient flow through identity paths, while AdamW momentum provides implicit updates for non-selected layers. We interpret LCSB as Block Coordinate Descent on the LoRA parameter space, providing theoretical justification for convergence. LCSB achieves up to 1.40$\times$ speedup with less than 2\% quality degradation across five models and three tasks. Surprisingly, in 4-bit quantized settings, LCSB exhibits superior stability: a 3B model that completely diverges under full backpropagation converges smoothly with LCSB, suggesting an implicit regularization effect from selective gradient computation.
Memory-Efficient Structured Backpropagation for On-Device LLM Fine-Tuning
Feb 13, 2026On-device fine-tuning enables privacy-preserving personalization of large language models, but mobile devices impose severe memory constraints, typically 6--12GB shared across all workloads. Existing approaches force a trade-off between exact gradients with high memory (MeBP) and low memory with noisy estimates (MeZO). We propose Memory-efficient Structured Backpropagation (MeSP), which bridges this gap by manually deriving backward passes that exploit LoRA's low-rank structure. Our key insight is that the intermediate projection $h = xA$ can be recomputed during backward at minimal cost since rank $r \ll d_{in}$, eliminating the need to store it. MeSP achieves 49\% average memory reduction compared to MeBP on Qwen2.5 models (0.5B--3B) while computing mathematically identical gradients. Our analysis also reveals that MeZO's gradient estimates show near-zero correlation with true gradients (cosine similarity $\approx$0.001), explaining its slow convergence. MeSP reduces peak memory from 361MB to 136MB for Qwen2.5-0.5B, enabling fine-tuning scenarios previously infeasible on memory-constrained devices.
Riemannian Optimization for LoRA on the Stiefel Manifold
Aug 25, 2025While powerful, large language models (LLMs) present significant fine-tuning challenges due to their size. Parameter-efficient fine-tuning (PEFT) methods like LoRA provide solutions, yet suffer from critical optimizer inefficiencies; notably basis redundancy in LoRA's $B$ matrix when using AdamW, which fundamentally limits performance. We address this by optimizing the $B$ matrix on the Stiefel manifold, imposing explicit orthogonality constraints that achieve near-perfect orthogonality and full effective rank. This geometric approach dramatically enhances parameter efficiency and representational capacity. Our Stiefel optimizer consistently outperforms AdamW across benchmarks with both LoRA and DoRA, demonstrating that geometric constraints are the key to unlocking LoRA's full potential for effective LLM fine-tuning.
Towards Zero-Shot Functional Compositionality of Language Models
Mar 06, 2023Large Pre-trained Language Models (PLM) have become the most desirable starting point in the field of NLP, as they have become remarkably good at solving many individual tasks. Despite such success, in this paper, we argue that current paradigms of working with PLMs are neglecting a critical aspect of modeling human intelligence: functional compositionality. Functional compositionality - the ability to compose learned tasks - has been a long-standing challenge in the field of AI (and many other fields) as it is considered one of the hallmarks of human intelligence. An illustrative example of such is cross-lingual summarization, where a bilingual person (English-French) could directly summarize an English document into French sentences without having to translate the English document or summary into French explicitly. We discuss why this matter is an important open problem that requires further attention from the field. Then, we show that current PLMs (e.g., GPT-2 and T5) don't have functional compositionality yet and it is far from human-level generalizability. Finally, we suggest several research directions that could push the field towards zero-shot functional compositionality of language models.
Evaluating the Knowledge Dependency of Questions
Nov 21, 2022The automatic generation of Multiple Choice Questions (MCQ) has the potential to reduce the time educators spend on student assessment significantly. However, existing evaluation metrics for MCQ generation, such as BLEU, ROUGE, and METEOR, focus on the n-gram based similarity of the generated MCQ to the gold sample in the dataset and disregard their educational value. They fail to evaluate the MCQ's ability to assess the student's knowledge of the corresponding target fact. To tackle this issue, we propose a novel automatic evaluation metric, coined Knowledge Dependent Answerability (KDA), which measures the MCQ's answerability given knowledge of the target fact. Specifically, we first show how to measure KDA based on student responses from a human survey. Then, we propose two automatic evaluation metrics, KDA_disc and KDA_cont, that approximate KDA by leveraging pre-trained language models to imitate students' problem-solving behavior. Through our human studies, we show that KDA_disc and KDA_soft have strong correlations with both (1) KDA and (2) usability in an actual classroom setting, labeled by experts. Furthermore, when combined with n-gram based similarity metrics, KDA_disc and KDA_cont are shown to have a strong predictive power for various expert-labeled MCQ quality measures.
Automated Evaluation for Student Argumentative Writing: A Survey
May 09, 2022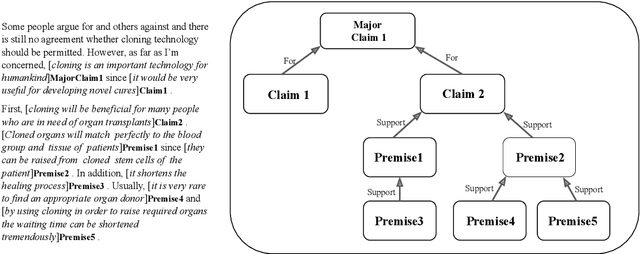
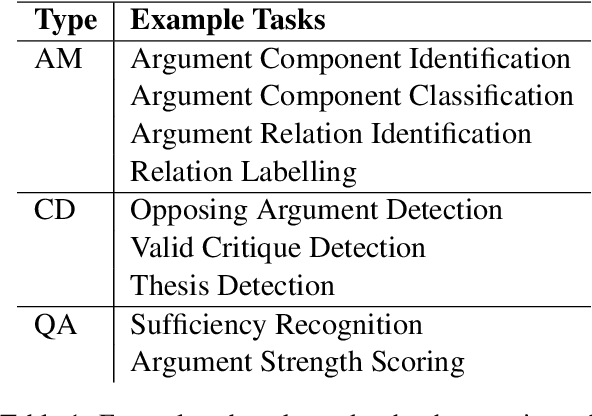
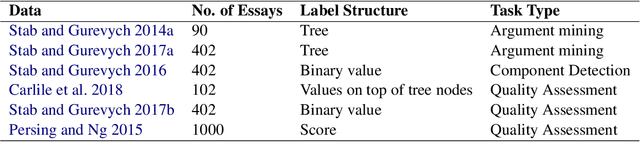
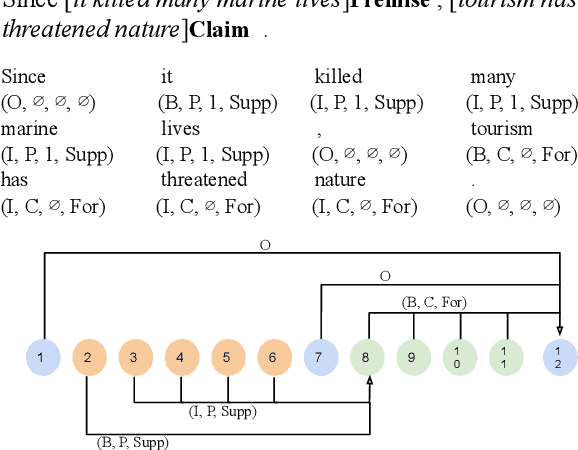
This paper surveys and organizes research works in an under-studied area, which we call automated evaluation for student argumentative writing. Unlike traditional automated writing evaluation that focuses on holistic essay scoring, this field is more specific: it focuses on evaluating argumentative essays and offers specific feedback, including argumentation structures, argument strength trait score, etc. The focused and detailed evaluation is useful for helping students acquire important argumentation skill. In this paper we organize existing works around tasks, data and methods. We further experiment with BERT on representative datasets, aiming to provide up-to-date baselines for this field.
GRAM: Fast Fine-tuning of Pre-trained Language Models for Content-based Collaborative Filtering
Apr 08, 2022
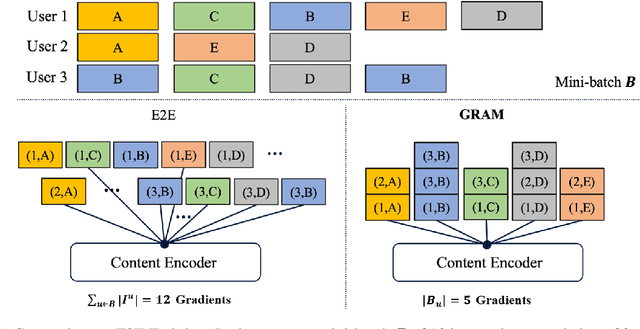
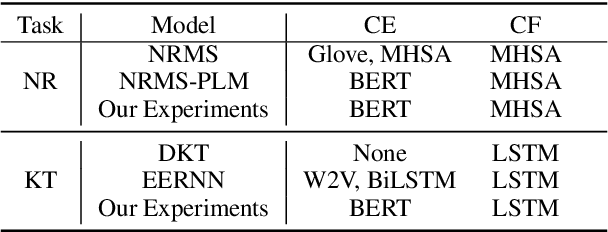
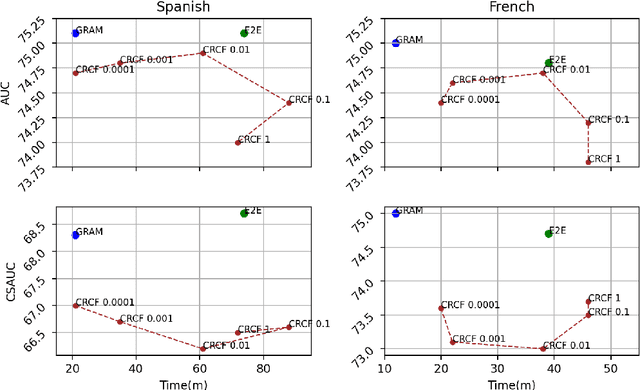
Content-based collaborative filtering (CCF) provides personalized item recommendations based on both users' interaction history and items' content information. Recently, pre-trained language models (PLM) have been used to extract high-quality item encodings for CCF. However, it is resource-intensive to finetune PLM in an end-to-end (E2E) manner in CCF due to its multi-modal nature: optimization involves redundant content encoding for interactions from users. For this, we propose GRAM (GRadient Accumulation for Multi-modality): (1) Single-step GRAM which aggregates gradients for each item while maintaining theoretical equivalence with E2E, and (2) Multi-step GRAM which further accumulates gradients across multiple training steps, with less than 40\% GPU memory footprint of E2E. We empirically confirm that GRAM achieves a remarkable boost in training efficiency based on five datasets from two task domains of Knowledge Tracing and News Recommendation, where single-step and multi-step GRAM achieve 4x and 45x training speedup on average, respectively.
Dialogue Summaries as Dialogue States (DS2), Template-Guided Summarization for Few-shot Dialogue State Tracking
Mar 03, 2022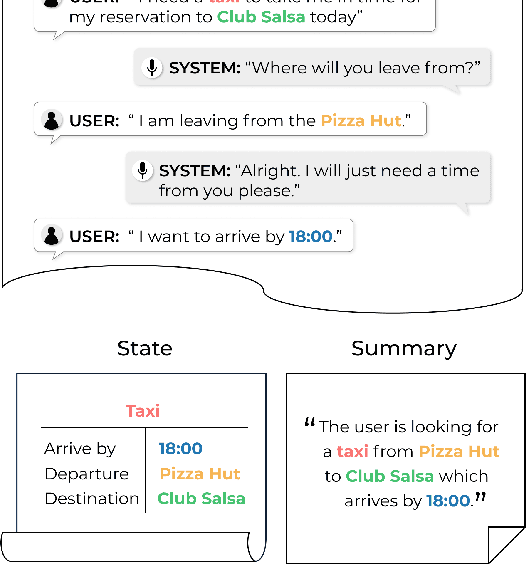
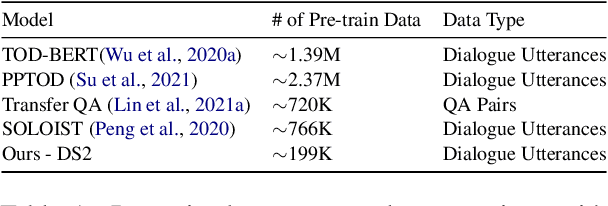
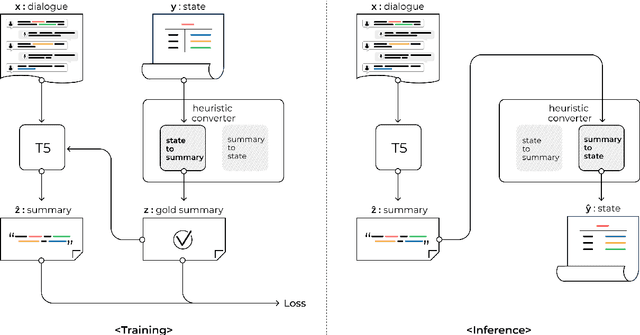
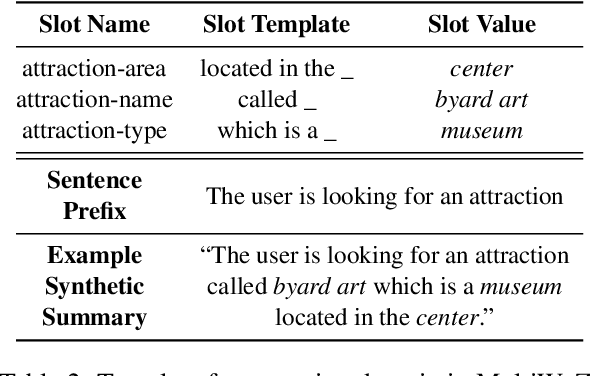
Annotating task-oriented dialogues is notorious for the expensive and difficult data collection process. Few-shot dialogue state tracking (DST) is a realistic solution to this problem. In this paper, we hypothesize that dialogue summaries are essentially unstructured dialogue states; hence, we propose to reformulate dialogue state tracking as a dialogue summarization problem. To elaborate, we train a text-to-text language model with synthetic template-based dialogue summaries, generated by a set of rules from the dialogue states. Then, the dialogue states can be recovered by inversely applying the summary generation rules. We empirically show that our method DS2 outperforms previous works on few-shot DST in MultiWoZ 2.0 and 2.1, in both cross-domain and multi-domain settings. Our method also exhibits vast speedup during both training and inference as it can generate all states at once. Finally, based on our analysis, we discover that the naturalness of the summary templates plays a key role for successful training.
Pedagogical Word Recommendation: A novel task and dataset on personalized vocabulary acquisition for L2 learners
Dec 28, 2021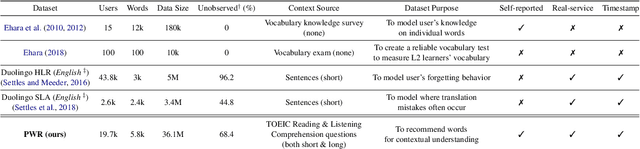
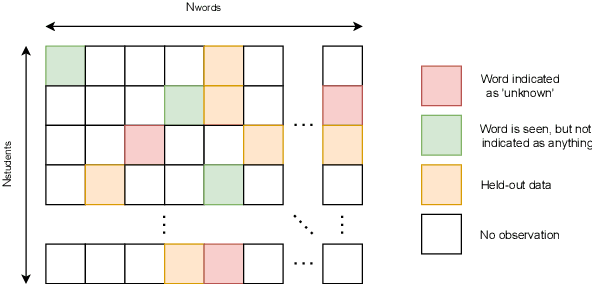
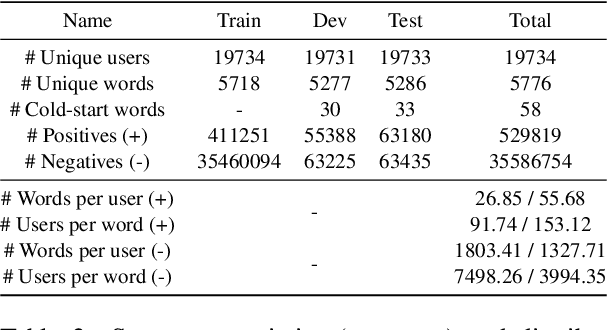
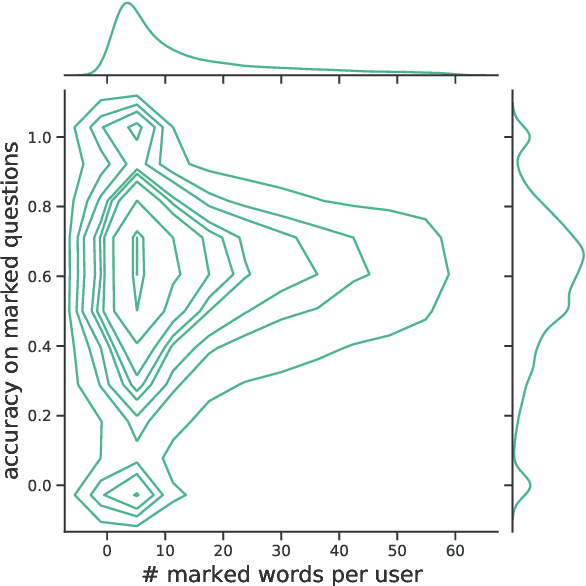
When learning a second language (L2), one of the most important but tedious components that often demoralizes students with its ineffectiveness and inefficiency is vocabulary acquisition, or more simply put, memorizing words. In light of such, a personalized and educational vocabulary recommendation system that traces a learner's vocabulary knowledge state would have an immense learning impact as it could resolve both issues. Therefore, in this paper, we propose and release data for a novel task called Pedagogical Word Recommendation (PWR). The main goal of PWR is to predict whether a given learner knows a given word based on other words the learner has already seen. To elaborate, we collect this data via an Intelligent Tutoring System (ITS) that is serviced to ~1M L2 learners who study for the standardized English exam, TOEIC. As a feature of this ITS, students can directly indicate words they do not know from the questions they solved to create wordbooks. Finally, we report the evaluation results of a Neural Collaborative Filtering approach along with an exploratory data analysis and discuss the impact and efficacy of this dataset as a baseline for future studies on this task.
Consistency and Monotonicity Regularization for Neural Knowledge Tracing
May 03, 2021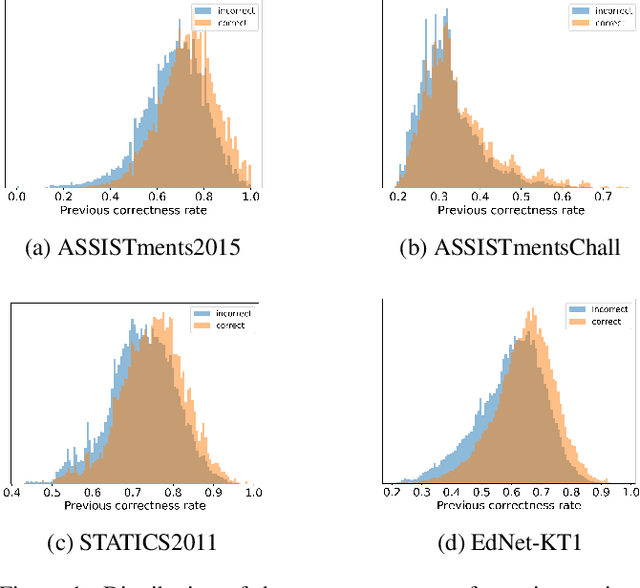
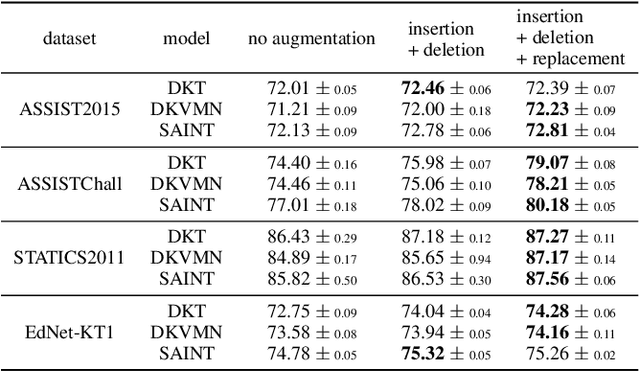

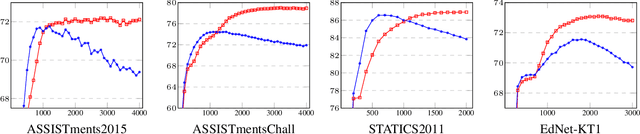
Knowledge Tracing (KT), tracking a human's knowledge acquisition, is a central component in online learning and AI in Education. In this paper, we present a simple, yet effective strategy to improve the generalization ability of KT models: we propose three types of novel data augmentation, coined replacement, insertion, and deletion, along with corresponding regularization losses that impose certain consistency or monotonicity biases on the model's predictions for the original and augmented sequence. Extensive experiments on various KT benchmarks show that our regularization scheme consistently improves the model performances, under 3 widely-used neural networks and 4 public benchmarks, e.g., it yields 6.3% improvement in AUC under the DKT model and the ASSISTmentsChall dataset.