 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverthinking Loops in Agents: A Structural Risk via MCP Tools
Feb 16, 2026Tool-using LLM agents increasingly coordinate real workloads by selecting and chaining third-party tools based on text-visible metadata such as tool names, descriptions, and return messages. We show that this convenience creates a supply-chain attack surface: a malicious MCP tool server can be co-registered alongside normal tools and induce overthinking loops, where individually trivial or plausible tool calls compose into cyclic trajectories that inflate end-to-end tokens and latency without any single step looking abnormal. We formalize this as a structural overthinking attack, distinguishable from token-level verbosity, and implement 14 malicious tools across three servers that trigger repetition, forced refinement, and distraction. Across heterogeneous registries and multiple tool-capable models, the attack causes severe resource amplification (up to $142.4\times$ tokens) and can degrade task outcomes. Finally, we find that decoding-time concision controls do not reliably prevent loop induction, suggesting defenses should reason about tool-call structure rather than tokens alone.
FEAT: A Preference Feedback Dataset through a Cost-Effective Auto-Generation and Labeling Framework for English AI Tutoring
Jun 24, 2025



In English education tutoring, teacher feedback is essential for guiding students. Recently, AI-based tutoring systems have emerged to assist teachers; however, these systems require high-quality and large-scale teacher feedback data, which is both time-consuming and costly to generate manually. In this study, we propose FEAT, a cost-effective framework for generating teacher feedback, and have constructed three complementary datasets: (1) DIRECT-Manual (DM), where both humans and large language models (LLMs) collaboratively generate high-quality teacher feedback, albeit at a higher cost; (2) DIRECT-Generated (DG), an LLM-only generated, cost-effective dataset with lower quality;, and (3) DIRECT-Augmented (DA), primarily based on DG with a small portion of DM added to enhance quality while maintaining cost-efficiency. Experimental results showed that incorporating a small portion of DM (5-10%) into DG leads to superior performance compared to using 100% DM alone.
What Really Matters in Many-Shot Attacks? An Empirical Study of Long-Context Vulnerabilities in LLMs
May 26, 2025



We investigate long-context vulnerabilities in Large Language Models (LLMs) through Many-Shot Jailbreaking (MSJ). Our experiments utilize context length of up to 128K tokens. Through comprehensive analysis with various many-shot attack settings with different instruction styles, shot density, topic, and format, we reveal that context length is the primary factor determining attack effectiveness. Critically, we find that successful attacks do not require carefully crafted harmful content. Even repetitive shots or random dummy text can circumvent model safety measures, suggesting fundamental limitations in long-context processing capabilities of LLMs. The safety behavior of well-aligned models becomes increasingly inconsistent with longer contexts. These findings highlight significant safety gaps in context expansion capabilities of LLMs, emphasizing the need for new safety mechanisms.
LLM-C3MOD: A Human-LLM Collaborative System for Cross-Cultural Hate Speech Moderation
Mar 10, 2025Content moderation is a global challenge, yet major tech platforms prioritize high-resource languages, leaving low-resource languages with scarce native moderators. Since effective moderation depends on understanding contextual cues, this imbalance increases the risk of improper moderation due to non-native moderators' limited cultural understanding. Through a user study, we identify that non-native moderators struggle with interpreting culturally-specific knowledge, sentiment, and internet culture in the hate speech moderation. To assist them, we present LLM-C3MOD, a human-LLM collaborative pipeline with three steps: (1) RAG-enhanced cultural context annotations; (2) initial LLM-based moderation; and (3) targeted human moderation for cases lacking LLM consensus. Evaluated on a Korean hate speech dataset with Indonesian and German participants, our system achieves 78% accuracy (surpassing GPT-4o's 71% baseline), while reducing human workload by 83.6%. Notably, human moderators excel at nuanced contents where LLMs struggle. Our findings suggest that non-native moderators, when properly supported by LLMs, can effectively contribute to cross-cultural hate speech moderation.
HEISIR: Hierarchical Expansion of Inverted Semantic Indexing for Training-free Retrieval of Conversational Data using LLMs
Mar 06, 2025



The growth of conversational AI services has increased demand for effective information retrieval from dialogue data. However, existing methods often face challenges in capturing semantic intent or require extensive labeling and fine-tuning. This paper introduces HEISIR (Hierarchical Expansion of Inverted Semantic Indexing for Retrieval), a novel framework that enhances semantic understanding in conversational data retrieval through optimized data ingestion, eliminating the need for resource-intensive labeling or model adaptation. HEISIR implements a two-step process: (1) Hierarchical Triplets Formulation and (2) Adjunct Augmentation, creating semantic indices consisting of Subject-Verb-Object-Adjunct (SVOA) quadruplets. This structured representation effectively captures the underlying semantic information from dialogue content. HEISIR achieves high retrieval performance while maintaining low latency during the actual retrieval process. Our experimental results demonstrate that HEISIR outperforms fine-tuned models across various embedding types and language models. Beyond improving retrieval capabilities, HEISIR also offers opportunities for intent and topic analysis in conversational data, providing a versatile solution for dialogue systems.
Harmonizing Attention: Training-free Texture-aware Geometry Transfer
Aug 19, 2024



Extracting geometry features from photographic images independently of surface texture and transferring them onto different materials remains a complex challenge. In this study, we introduce Harmonizing Attention, a novel training-free approach that leverages diffusion models for texture-aware geometry transfer. Our method employs a simple yet effective modification of self-attention layers, allowing the model to query information from multiple reference images within these layers. This mechanism is seamlessly integrated into the inversion process as Texture-aligning Attention and into the generation process as Geometry-aligning Attention. This dual-attention approach ensures the effective capture and transfer of material-independent geometry features while maintaining material-specific textural continuity, all without the need for model fine-tuning.
Automated Evaluation for Student Argumentative Writing: A Survey
May 09, 2022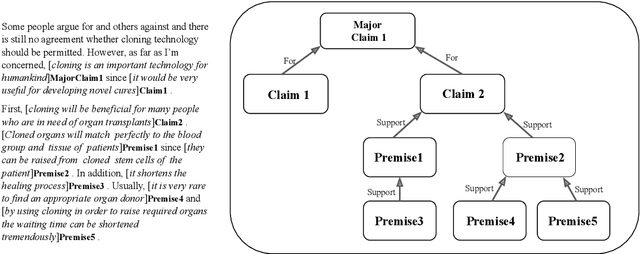
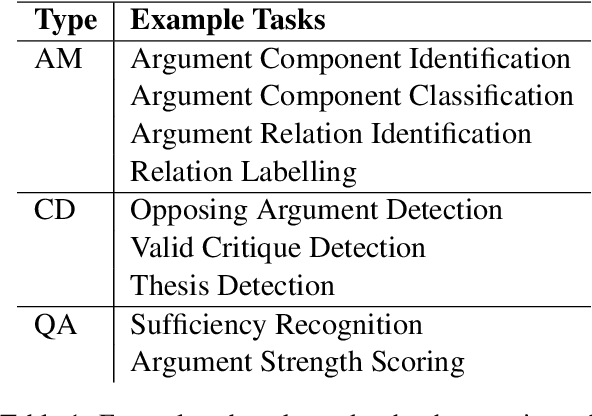
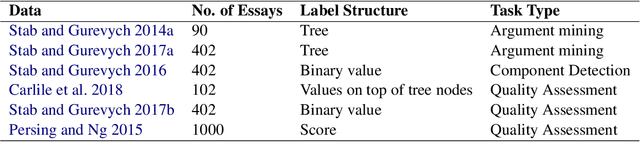
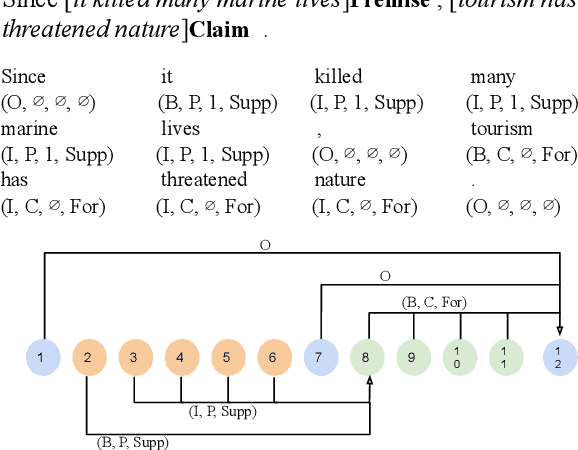
This paper surveys and organizes research works in an under-studied area, which we call automated evaluation for student argumentative writing. Unlike traditional automated writing evaluation that focuses on holistic essay scoring, this field is more specific: it focuses on evaluating argumentative essays and offers specific feedback, including argumentation structures, argument strength trait score, etc. The focused and detailed evaluation is useful for helping students acquire important argumentation skill. In this paper we organize existing works around tasks, data and methods. We further experiment with BERT on representative datasets, aiming to provide up-to-date baselines for this field.