 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Really Matters in Many-Shot Attacks? An Empirical Study of Long-Context Vulnerabilities in LLMs
May 26, 2025



We investigate long-context vulnerabilities in Large Language Models (LLMs) through Many-Shot Jailbreaking (MSJ). Our experiments utilize context length of up to 128K tokens. Through comprehensive analysis with various many-shot attack settings with different instruction styles, shot density, topic, and format, we reveal that context length is the primary factor determining attack effectiveness. Critically, we find that successful attacks do not require carefully crafted harmful content. Even repetitive shots or random dummy text can circumvent model safety measures, suggesting fundamental limitations in long-context processing capabilities of LLMs. The safety behavior of well-aligned models becomes increasingly inconsistent with longer contexts. These findings highlight significant safety gaps in context expansion capabilities of LLMs, emphasizing the need for new safety mechanisms.
LLM-guided Plan and Retrieval: A Strategic Alignment for Interpretable User Satisfaction Estimation in Dialogue
Mar 06, 2025
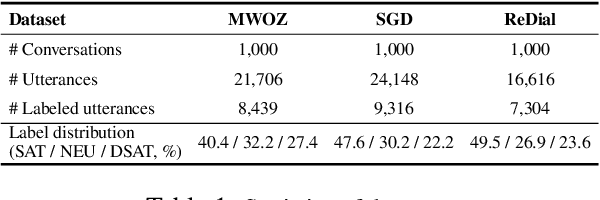
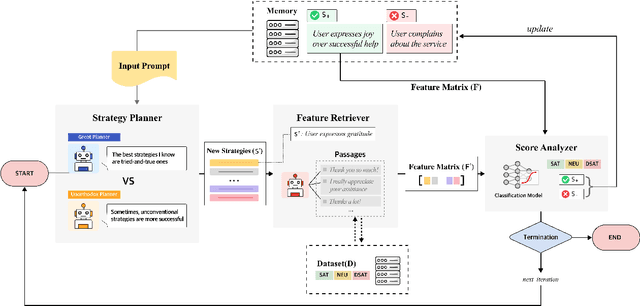

Understanding user satisfaction with conversational systems, known as User Satisfaction Estimation (USE), is essential for assessing dialogue quality and enhancing user experiences. However, existing methods for USE face challenges due to limited understanding of underlying reasons for user dissatisfaction and the high costs of annotating user intentions. To address these challenges, we propose PRAISE (Plan and Retrieval Alignment for Interpretable Satisfaction Estimation), an interpretable framework for effective user satisfaction prediction. PRAISE operates through three key modules. The Strategy Planner develops strategies, which are natural language criteria for classifying user satisfaction. The Feature Retriever then incorporates knowledge on user satisfaction from Large Language Models (LLMs) and retrieves relevance features from utterances. Finally, the Score Analyzer evaluates strategy predictions and classifies user satisfaction. Experimental results demonstrate that PRAISE achieves state-of-the-art performance on three benchmarks for the USE task. Beyond its superior performance, PRAISE offers additional benefits. It enhances interpretability by providing instance-level explanations through effective alignment of utterances with strategies. Moreover, PRAISE operates more efficiently than existing approaches by eliminating the need for LLMs during the inference phase.
HEISIR: Hierarchical Expansion of Inverted Semantic Indexing for Training-free Retrieval of Conversational Data using LLMs
Mar 06, 2025



The growth of conversational AI services has increased demand for effective information retrieval from dialogue data. However, existing methods often face challenges in capturing semantic intent or require extensive labeling and fine-tuning. This paper introduces HEISIR (Hierarchical Expansion of Inverted Semantic Indexing for Retrieval), a novel framework that enhances semantic understanding in conversational data retrieval through optimized data ingestion, eliminating the need for resource-intensive labeling or model adaptation. HEISIR implements a two-step process: (1) Hierarchical Triplets Formulation and (2) Adjunct Augmentation, creating semantic indices consisting of Subject-Verb-Object-Adjunct (SVOA) quadruplets. This structured representation effectively captures the underlying semantic information from dialogue content. HEISIR achieves high retrieval performance while maintaining low latency during the actual retrieval process. Our experimental results demonstrate that HEISIR outperforms fine-tuned models across various embedding types and language models. Beyond improving retrieval capabilities, HEISIR also offers opportunities for intent and topic analysis in conversational data, providing a versatile solution for dialogue systems.
Safe-Embed: Unveiling the Safety-Critical Knowledge of Sentence Encoders
Jul 09, 2024Despite the impressive capabilities of Large Language Models (LLMs) in various tasks, their vulnerability to unsafe prompts remains a critical issue. These prompts can lead LLMs to generate responses on illegal or sensitive topics, posing a significant threat to their safe and ethical use. Existing approaches attempt to address this issue using classification models, but they have several drawbacks. With the increasing complexity of unsafe prompts, similarity search-based techniques that identify specific features of unsafe prompts provide a more robust and effective solution to this evolving problem. This paper investigates the potential of sentence encoders to distinguish safe from unsafe prompts, and the ability to classify various unsafe prompts according to a safety taxonomy. We introduce new pairwise datasets and the Categorical Purity (CP) metric to measure this capability. Our findings reveal both the effectiveness and limitations of existing sentence encoders, proposing directions to improve sentence encoders to operate as more robust safety detectors. Our code is available at https://github.com/JwdanielJung/Safe-Embed.