 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing the Reliability of LLM-as-a-Judge via Item Response Theory
Jan 31, 2026While LLM-as-a-Judge is widely used in automated evaluation, existing validation practices primarily operate at the level of observed outputs, offering limited insight into whether LLM judges themselves function as stable and reliable measurement instruments. To address this limitation, we introduce a two-phase diagnostic framework for assessing reliability of LLM-as-a-Judge, grounded in Item Response Theory (IRT). The framework adopts Graded Response Model (GRM) of IRT and formalizes reliability along two complementary dimensions: (1) intrinsic consistency, defined as the stability of measurement behavior under prompt variations, and (2) human alignment, capturing correspondence with human quality assessments. We empirically examine diverse LLM judges with this framework, and show that leveraging IRT-GRM yields interpretable signals for diagnosing judgments systematically. These signals provide practical guidance for verifying reliablity of LLM-as-a-Judge and identifying potential causes of unreliability.
PsyProbe: Proactive and Interpretable Dialogue through User State Modeling for Exploratory Counseling
Jan 27, 2026Recent advances in large language models have enabled mental health dialogue systems, yet existing approaches remain predominantly reactive, lacking systematic user state modeling for proactive therapeutic exploration. We introduce PsyProbe, a dialogue system designed for the exploration phase of counseling that systematically tracks user psychological states through the PPPPPI framework (Presenting, Predisposing, Precipitating, Perpetuating, Protective, Impact) augmented with cognitive error detection. PsyProbe combines State Builder for extracting structured psychological profiles, Memory Construction for tracking information gaps, Strategy Planner for Motivational Interviewing behavioral codes, and Response Generator with Question Ideation and Critic/Revision modules to generate contextually appropriate, proactive questions. We evaluate PsyProbe with 27 participants in real-world Korean counseling scenarios, including automatic evaluation across ablation modes, user evaluation, and expert evaluation by a certified counselor. The full PsyProbe model consistently outperforms baseline and ablation modes in automatic evaluation. User evaluation demonstrates significantly increased engagement intention and improved naturalness compared to baseline. Expert evaluation shows that PsyProbe substantially improves core issue understanding and achieves question rates comparable to professional counselors, validating the effectiveness of systematic state modeling and proactive questioning for therapeutic exploration.
LLM-guided Plan and Retrieval: A Strategic Alignment for Interpretable User Satisfaction Estimation in Dialogue
Mar 06, 2025
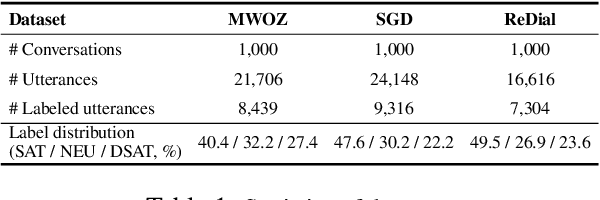
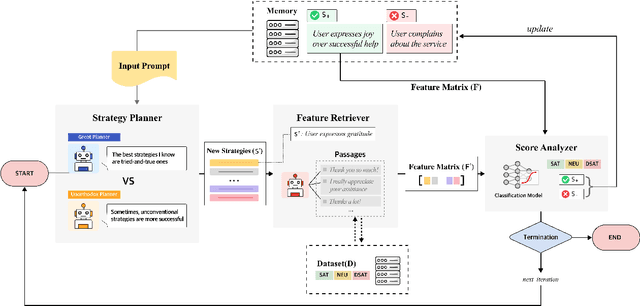

Understanding user satisfaction with conversational systems, known as User Satisfaction Estimation (USE), is essential for assessing dialogue quality and enhancing user experiences. However, existing methods for USE face challenges due to limited understanding of underlying reasons for user dissatisfaction and the high costs of annotating user intentions. To address these challenges, we propose PRAISE (Plan and Retrieval Alignment for Interpretable Satisfaction Estimation), an interpretable framework for effective user satisfaction prediction. PRAISE operates through three key modules. The Strategy Planner develops strategies, which are natural language criteria for classifying user satisfaction. The Feature Retriever then incorporates knowledge on user satisfaction from Large Language Models (LLMs) and retrieves relevance features from utterances. Finally, the Score Analyzer evaluates strategy predictions and classifies user satisfaction. Experimental results demonstrate that PRAISE achieves state-of-the-art performance on three benchmarks for the USE task. Beyond its superior performance, PRAISE offers additional benefits. It enhances interpretability by providing instance-level explanations through effective alignment of utterances with strategies. Moreover, PRAISE operates more efficiently than existing approaches by eliminating the need for LLMs during the inference phase.