 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Milestone in Formalization: The Sphere Packing Problem in Dimension 8
Apr 28, 2026In 2016, Viazovska famously solved the sphere packing problem in dimension $8$, using modular forms to construct a 'magic' function satisfying optimality conditions determined by Cohn and Elkies in 2003. In March 2024, Hariharan and Viazovska launched a project to formalize this solution and related mathematical facts in the Lean Theorem Prover. A significant milestone was achieved in February 2026: the result was formally verified, with the final stages of the verification done by Math, Inc.'s autoformalization model 'Gauss'. We discuss the techniques used to achieve this milestone, reflect on the unique collaboration between humans and Gauss, and discuss project objectives that remain.
HETAL: Efficient Privacy-preserving Transfer Learning with Homomorphic Encryption
Mar 21, 2024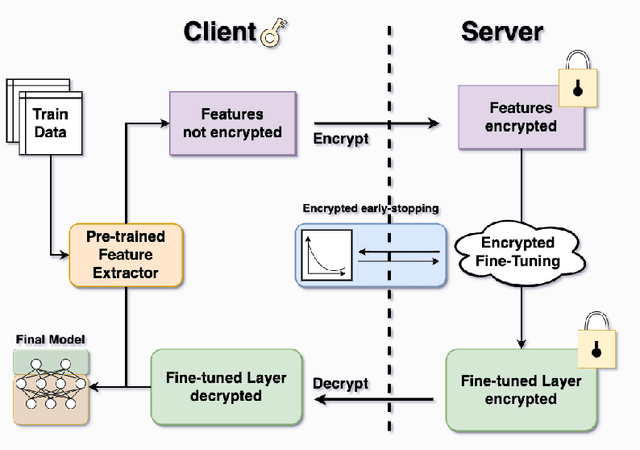
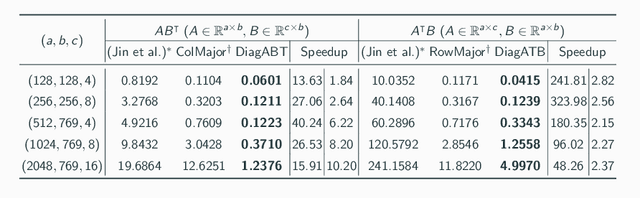
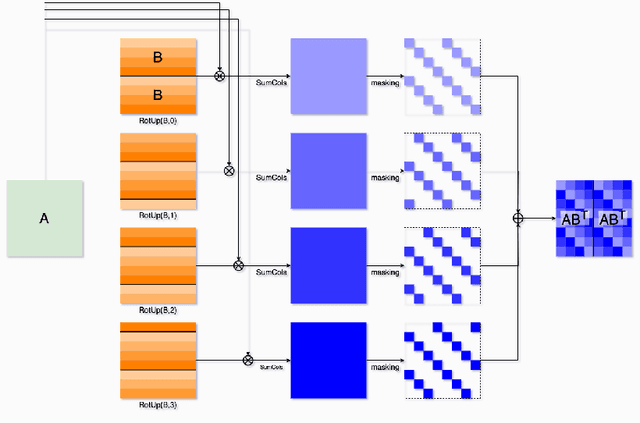
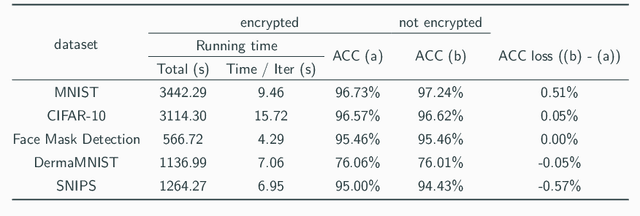
Transfer learning is a de facto standard method for efficiently training machine learning models for data-scarce problems by adding and fine-tuning new classification layers to a model pre-trained on large datasets. Although numerous previous studies proposed to use homomorphic encryption to resolve the data privacy issue in transfer learning in the machine learning as a service setting, most of them only focused on encrypted inference. In this study, we present HETAL, an efficient Homomorphic Encryption based Transfer Learning algorithm, that protects the client's privacy in training tasks by encrypting the client data using the CKKS homomorphic encryption scheme. HETAL is the first practical scheme that strictly provides encrypted training, adopting validation-based early stopping and achieving the accuracy of nonencrypted training. We propose an efficient encrypted matrix multiplication algorithm, which is 1.8 to 323 times faster than prior methods, and a highly precise softmax approximation algorithm with increased coverage. The experimental results for five well-known benchmark datasets show total training times of 567-3442 seconds, which is less than an hour.
Consistency and Monotonicity Regularization for Neural Knowledge Tracing
May 03, 2021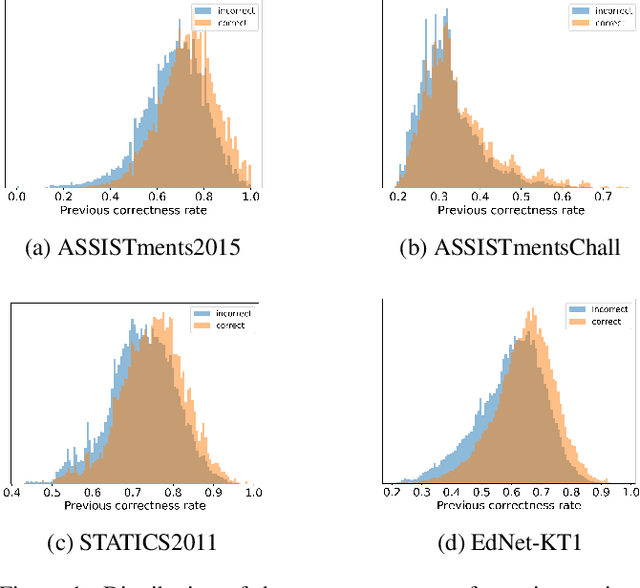
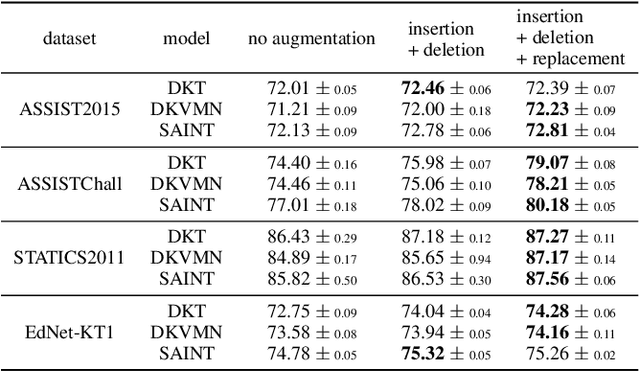

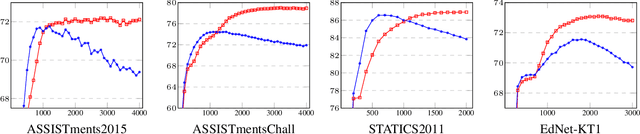
Knowledge Tracing (KT), tracking a human's knowledge acquisition, is a central component in online learning and AI in Education. In this paper, we present a simple, yet effective strategy to improve the generalization ability of KT models: we propose three types of novel data augmentation, coined replacement, insertion, and deletion, along with corresponding regularization losses that impose certain consistency or monotonicity biases on the model's predictions for the original and augmented sequence. Extensive experiments on various KT benchmarks show that our regularization scheme consistently improves the model performances, under 3 widely-used neural networks and 4 public benchmarks, e.g., it yields 6.3% improvement in AUC under the DKT model and the ASSISTmentsChall dataset.
SAINT+: Integrating Temporal Features for EdNet Correctness Prediction
Oct 19, 2020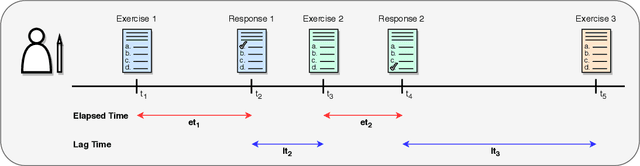

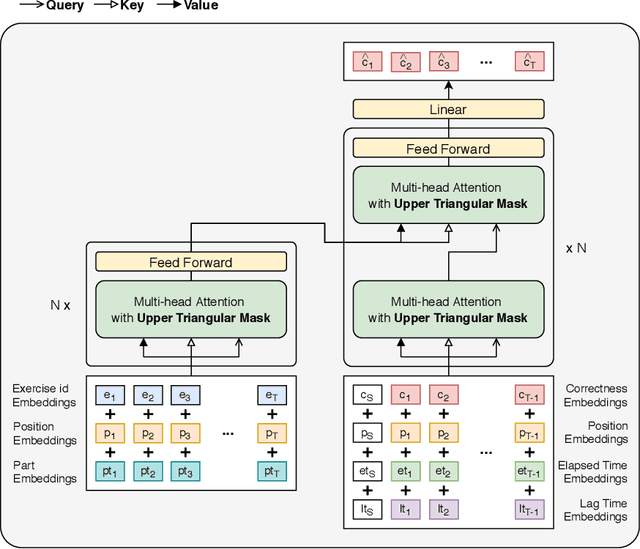
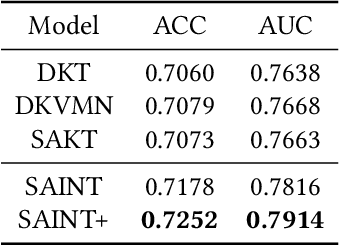
We propose SAINT+, a successor of SAINT which is a Transformer based knowledge tracing model that separately processes exercise information and student response information. Following the architecture of SAINT, SAINT+ has an encoder-decoder structure where the encoder applies self-attention layers to a stream of exercise embeddings, and the decoder alternately applies self-attention layers and encoder-decoder attention layers to streams of response embeddings and encoder output. Moreover, SAINT+ incorporates two temporal feature embeddings into the response embeddings: elapsed time, the time taken for a student to answer, and lag time, the time interval between adjacent learning activities. We empirically evaluate the effectiveness of SAINT+ on EdNet, the largest publicly available benchmark dataset in the education domain. Experimental results show that SAINT+ achieves state-of-the-art performance in knowledge tracing with an improvement of 1.25% in area under receiver operating characteristic curve compared to SAINT, the current state-of-the-art model in EdNet dataset.
Assessment Modeling: Fundamental Pre-training Tasks for Interactive Educational Systems
Jan 01, 2020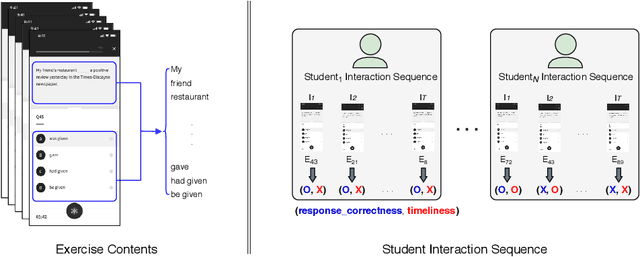

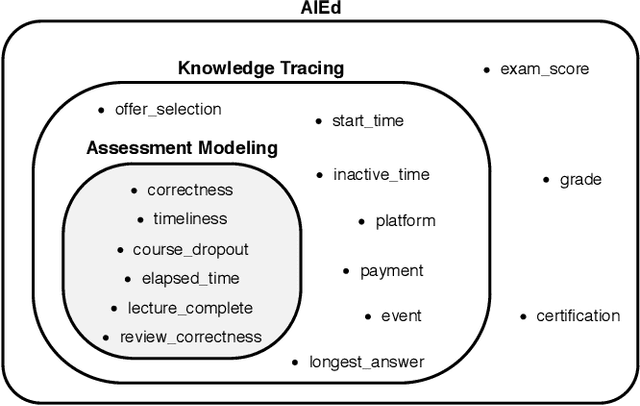
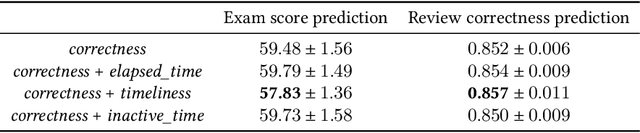
Interactive Educational Systems (IESs) have developed rapidly in recent years to address the issue of quality and affordability of education. Analogous to other domains in AI, there are specific tasks of AIEd for which labels are scarce. For instance, labels like exam score and grade are considered important in educational and social context. However, obtaining the labels is costly as they require student actions taken outside the system. Likewise, while student events like course dropout and review correctness are automatically recorded by IESs, they are few in number as the events occur sporadically in practice. A common way of circumventing the label-scarcity problem is the pre-train/fine-tine method. Accordingly, existing works pre-train a model to learn representations of contents in learning items. However, such methods fail to utilize the student interaction data available and model student learning behavior. To this end, we propose assessment modeling, fundamental pre-training tasks for IESs. An assessment is a feature of student-system interactions which can act as pedagogical evaluation, such as student response correctness or timeliness. Assessment modeling is the prediction of assessments conditioned on the surrounding context of interactions. Although it is natural to pre-train interactive features available in large amount, narrowing down the prediction targets to assessments holds relevance to the label-scarce educational problems while reducing irrelevant noises. To the best of our knowledge, this is the first work investigating appropriate pre-training method of predicting educational features from student-system interactions. While the effectiveness of different combinations of assessments is open for exploration, we suggest assessment modeling as a guiding principle for selecting proper pre-training tasks for the label-scarce educational problems.
EdNet: A Large-Scale Hierarchical Dataset in Education
Dec 06, 2019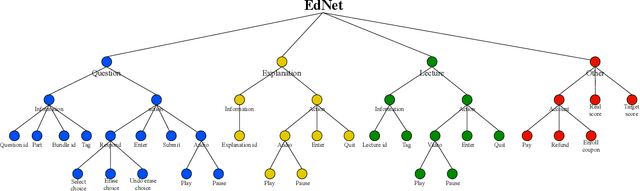
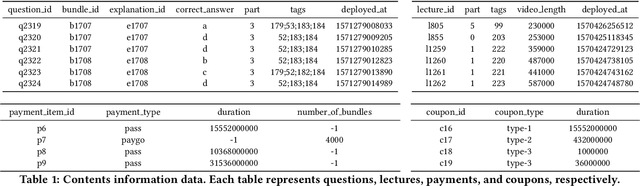
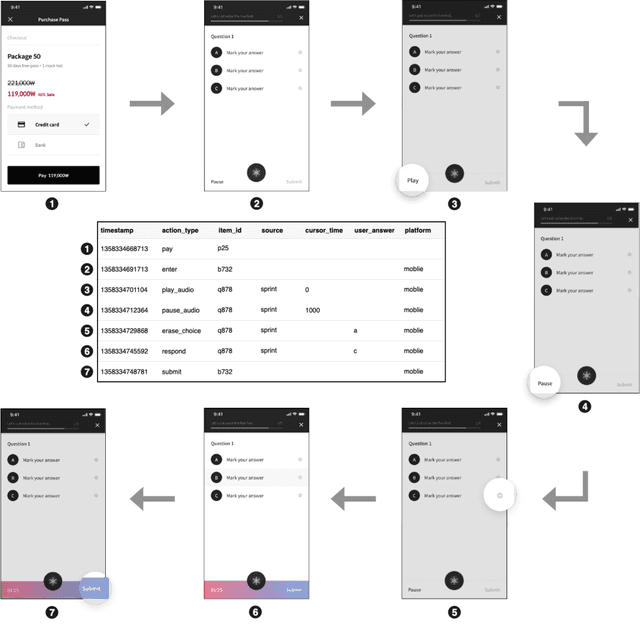
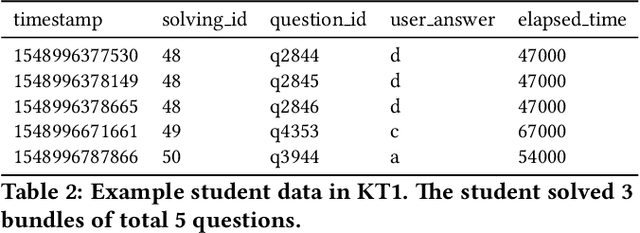
With advances in Artificial Intelligence in Education (AIEd) and the ever-growing scale of Interactive Educational Systems (IESs), data-driven approach has become a common recipe for various tasks such as knowledge tracing and learning path recommendation. Unfortunately, collecting real students' interaction data is often challenging, which results in the lack of public large-scale benchmark dataset reflecting a wide variety of student behaviors in modern IESs. Although several datasets, such as ASSISTments, Junyi Academy, Synthetic and STATICS, are publicly available and widely used, they are not large enough to leverage the full potential of state-of-the-art data-driven models and limits the recorded behaviors to question-solving activities. To this end, we introduce EdNet, a large-scale hierarchical dataset of diverse student activities collected by Santa, a multi-platform self-study solution equipped with artificial intelligence tutoring system. EdNet contains 131,441,538 interactions from 784,309 students collected over more than 2 years, which is the largest among the ITS datasets released to the public so far. Unlike existing datasets, EdNet provides a wide variety of student actions ranging from question-solving to lecture consumption and item purchasing. Also, EdNet has a hierarchical structure where the student actions are divided into 4 different levels of abstractions. The features of EdNet are domain-agnostic, allowing EdNet to be extended to different domains easily. The dataset is publicly released under Creative Commons Attribution-NonCommercial 4.0 International license for research purposes. We plan to host challenges in multiple AIEd tasks with EdNet to provide a common ground for the fair comparison between different state of the art models and encourage the development of practical and effective methods.