 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHETAL: Efficient Privacy-preserving Transfer Learning with Homomorphic Encryption
Mar 21, 2024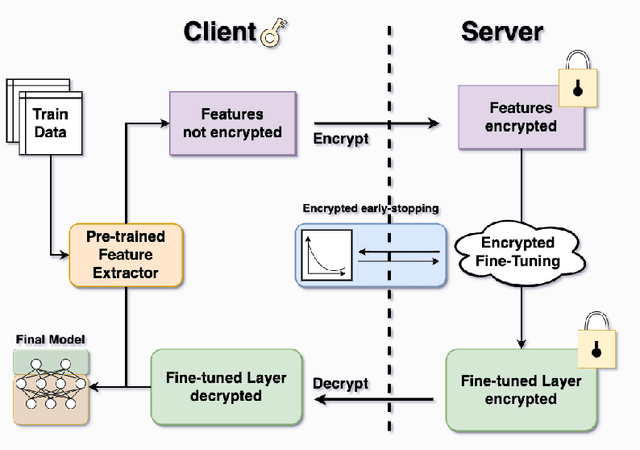
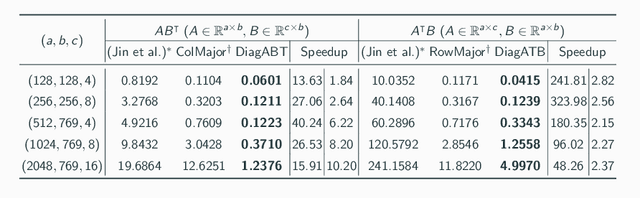
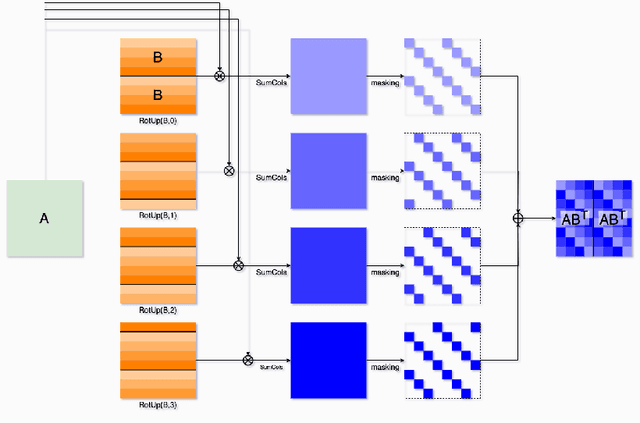
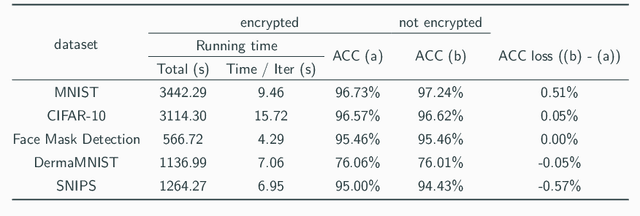
Transfer learning is a de facto standard method for efficiently training machine learning models for data-scarce problems by adding and fine-tuning new classification layers to a model pre-trained on large datasets. Although numerous previous studies proposed to use homomorphic encryption to resolve the data privacy issue in transfer learning in the machine learning as a service setting, most of them only focused on encrypted inference. In this study, we present HETAL, an efficient Homomorphic Encryption based Transfer Learning algorithm, that protects the client's privacy in training tasks by encrypting the client data using the CKKS homomorphic encryption scheme. HETAL is the first practical scheme that strictly provides encrypted training, adopting validation-based early stopping and achieving the accuracy of nonencrypted training. We propose an efficient encrypted matrix multiplication algorithm, which is 1.8 to 323 times faster than prior methods, and a highly precise softmax approximation algorithm with increased coverage. The experimental results for five well-known benchmark datasets show total training times of 567-3442 seconds, which is less than an hour.
Privacy-Preserving Text Classification on BERT Embeddings with Homomorphic Encryption
Oct 05, 2022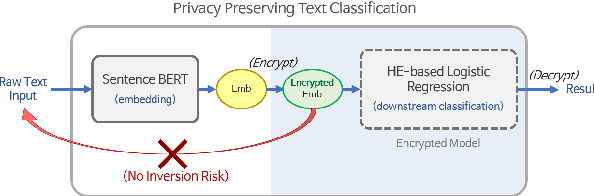

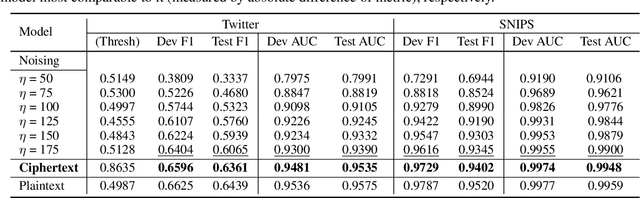

Embeddings, which compress information in raw text into semantics-preserving low-dimensional vectors, have been widely adopted for their efficacy. However, recent research has shown that embeddings can potentially leak private information about sensitive attributes of the text, and in some cases, can be inverted to recover the original input text. To address these growing privacy challenges, we propose a privatization mechanism for embeddings based on homomorphic encryption, to prevent potential leakage of any piece of information in the process of text classification. In particular, our method performs text classification on the encryption of embeddings from state-of-the-art models like BERT, supported by an efficient GPU implementation of CKKS encryption scheme. We show that our method offers encrypted protection of BERT embeddings, while largely preserving their utility on downstream text classification tasks.