 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncryption-Friendly LLM Architecture
Oct 03, 2024



Large language models (LLMs) offer personalized responses based on user interactions, but this use case raises serious privacy concerns. Homomorphic encryption (HE) is a cryptographic protocol supporting arithmetic computations in encrypted states and provides a potential solution for privacy-preserving machine learning (PPML). However, the computational intensity of transformers poses challenges for applying HE to LLMs. In this work, we propose a modified HE-friendly transformer architecture with an emphasis on inference following personalized (private) fine-tuning. Utilizing LoRA fine-tuning and Gaussian kernels, we achieve significant computational speedups -- 6.94x for fine-tuning and 2.3x for inference -- while maintaining performance comparable to plaintext models. Our findings provide a viable proof of concept for offering privacy-preserving LLM services in areas where data protection is crucial.
Privacy-Preserving Text Classification on BERT Embeddings with Homomorphic Encryption
Oct 05, 2022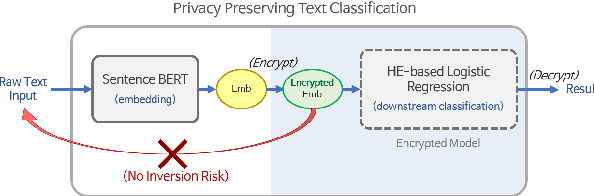

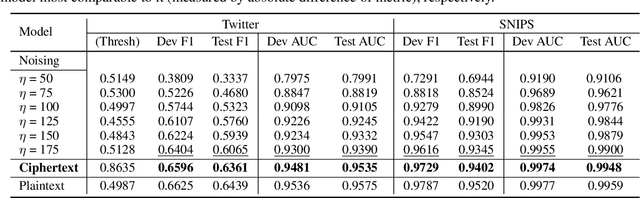

Embeddings, which compress information in raw text into semantics-preserving low-dimensional vectors, have been widely adopted for their efficacy. However, recent research has shown that embeddings can potentially leak private information about sensitive attributes of the text, and in some cases, can be inverted to recover the original input text. To address these growing privacy challenges, we propose a privatization mechanism for embeddings based on homomorphic encryption, to prevent potential leakage of any piece of information in the process of text classification. In particular, our method performs text classification on the encryption of embeddings from state-of-the-art models like BERT, supported by an efficient GPU implementation of CKKS encryption scheme. We show that our method offers encrypted protection of BERT embeddings, while largely preserving their utility on downstream text classification tasks.