 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncryption-Friendly LLM Architecture
Oct 03, 2024



Large language models (LLMs) offer personalized responses based on user interactions, but this use case raises serious privacy concerns. Homomorphic encryption (HE) is a cryptographic protocol supporting arithmetic computations in encrypted states and provides a potential solution for privacy-preserving machine learning (PPML). However, the computational intensity of transformers poses challenges for applying HE to LLMs. In this work, we propose a modified HE-friendly transformer architecture with an emphasis on inference following personalized (private) fine-tuning. Utilizing LoRA fine-tuning and Gaussian kernels, we achieve significant computational speedups -- 6.94x for fine-tuning and 2.3x for inference -- while maintaining performance comparable to plaintext models. Our findings provide a viable proof of concept for offering privacy-preserving LLM services in areas where data protection is crucial.
Unsupervised Model Drift Estimation with Batch Normalization Statistics for Dataset Shift Detection and Model Selection
Jul 01, 2021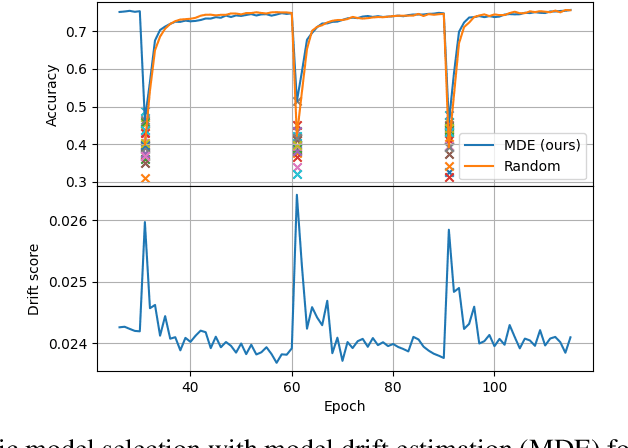



While many real-world data streams imply that they change frequently in a nonstationary way, most of deep learning methods optimize neural networks on training data, and this leads to severe performance degradation when dataset shift happens. However, it is less possible to annotate or inspect newly streamed data by humans, and thus it is desired to measure model drift at inference time in an unsupervised manner. In this paper, we propose a novel method of model drift estimation by exploiting statistics of batch normalization layer on unlabeled test data. To remedy possible sampling error of streamed input data, we adopt low-rank approximation to each representational layer. We show the effectiveness of our method not only on dataset shift detection but also on model selection when there are multiple candidate models among model zoo or training trajectories in an unsupervised way. We further demonstrate the consistency of our method by comparing model drift scores between different network architectures.
Data Proxy Generation for Fast and Efficient Neural Architecture Search
Nov 21, 2019



Due to the recent advances on Neural Architecture Search (NAS), it gains popularity in designing best networks for specific tasks. Although it shows promising results on many benchmarks and competitions, NAS still suffers from its demanding computation cost for searching high dimensional architectural design space, and this problem becomes even worse when we want to use a large-scale dataset. If we can make a reliable data proxy for NAS, the efficiency of NAS approaches increase accordingly. Our basic observation for making a data proxy is that each example in a specific dataset has a different impact on NAS process and most of examples are redundant from a relative accuracy ranking perspective, which we should preserve when making a data proxy. We propose a systematic approach to measure the importance of each example from this relative accuracy ranking point of view, and make a reliable data proxy based on the statistics of training and testing examples. Our experiment shows that we can preserve the almost same relative accuracy ranking between all possible network configurations even with 10-20$\times$ smaller data proxy.
JGAN: A Joint Formulation of GAN for Synthesizing Images and Labels
Jun 13, 2019



Image generation with explicit condition or label generally works better than unconditional image generation. In modern GAN frameworks, both generator and discriminator are formulated to model the conditional distribution of images given with labels. In this paper, we provide an alternative formulation of GAN which models joint distribution of images and labels. There are two advantages in this joint formulation over conditional approaches. The first advantage is that the joint formulation is more robust to label noises, and the second is we can use any kind of weak labels (or additional information which has dependence on the original image data) to enhance unconditional image generation. We will show the effectiveness of joint formulation in CIFAR-10, CIFAR-100, and STL dataset.
PVANet: Lightweight Deep Neural Networks for Real-time Object Detection
Dec 09, 2016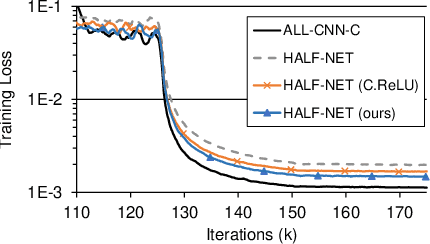
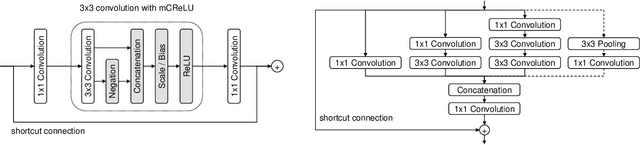
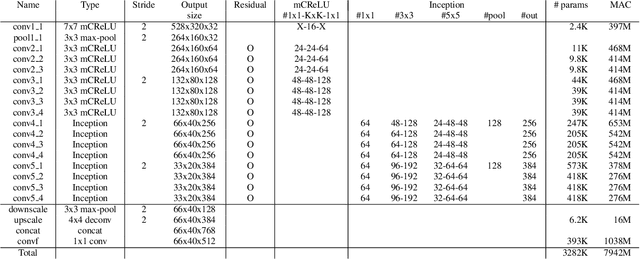
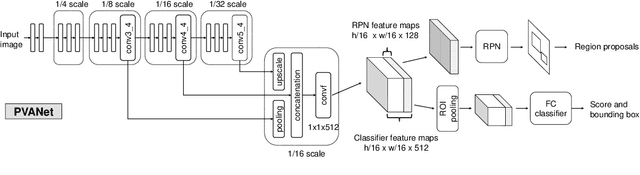
In object detection, reducing computational cost is as important as improving accuracy for most practical usages. This paper proposes a novel network structure, which is an order of magnitude lighter than other state-of-the-art networks while maintaining the accuracy. Based on the basic principle of more layers with less channels, this new deep neural network minimizes its redundancy by adopting recent innovations including C.ReLU and Inception structure. We also show that this network can be trained efficiently to achieve solid results on well-known object detection benchmarks: 84.9% and 84.2% mAP on VOC2007 and VOC2012 while the required compute is less than 10% of the recent ResNet-101.
PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
Sep 30, 2016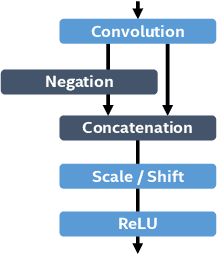
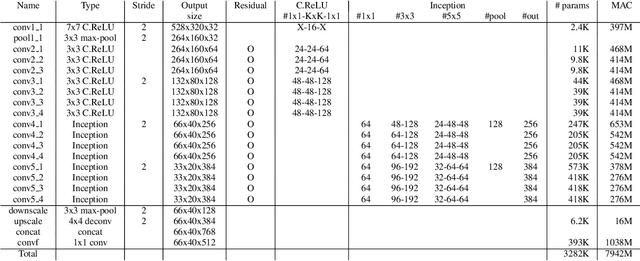
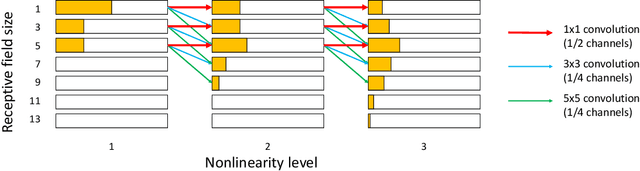
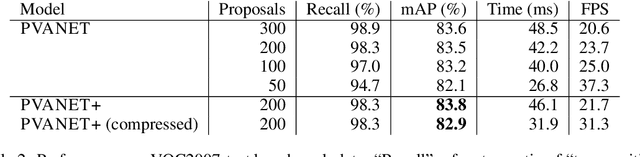
This paper presents how we can achieve the state-of-the-art accuracy in multi-category object detection task while minimizing the computational cost by adapting and combining recent technical innovations. Following the common pipeline of "CNN feature extraction + region proposal + RoI classification", we mainly redesign the feature extraction part, since region proposal part is not computationally expensive and classification part can be efficiently compressed with common techniques like truncated SVD. Our design principle is "less channels with more layers" and adoption of some building blocks including concatenated ReLU, Inception, and HyperNet. The designed network is deep and thin and trained with the help of batch normalization, residual connections, and learning rate scheduling based on plateau detection. We obtained solid results on well-known object detection benchmarks: 83.8% mAP (mean average precision) on VOC2007 and 82.5% mAP on VOC2012 (2nd place), while taking only 750ms/image on Intel i7-6700K CPU with a single core and 46ms/image on NVIDIA Titan X GPU. Theoretically, our network requires only 12.3% of the computational cost compared to ResNet-101, the winner on VOC2012.