 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHintPose
Mar 04, 2020
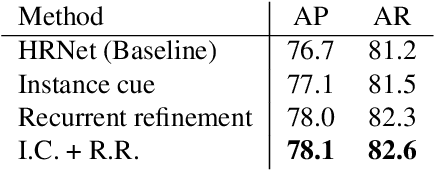
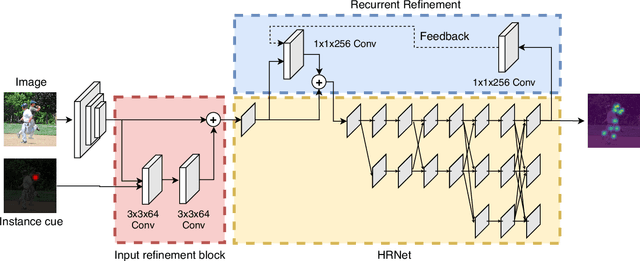
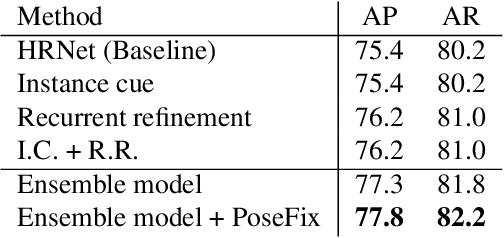
Most of the top-down pose estimation models assume that there exists only one person in a bounding box. However, the assumption is not always correct. In this technical report, we introduce two ideas, instance cue and recurrent refinement, to an existing pose estimator so that the model is able to handle detection boxes with multiple persons properly. When we evaluated our model on the COCO17 keypoints dataset, it showed non-negligible improvement compared to its baseline model. Our model achieved 76.2 mAP as a single model and 77.3 mAP as an ensemble on the test-dev set without additional training data. After additional post-processing with a separate refinement network, our final predictions achieved 77.8 mAP on the COCO test-dev set.
ChoiceNet: Robust Learning by Revealing Output Correlations
May 18, 2018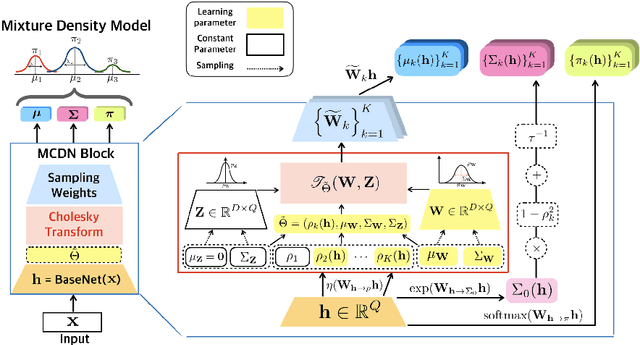
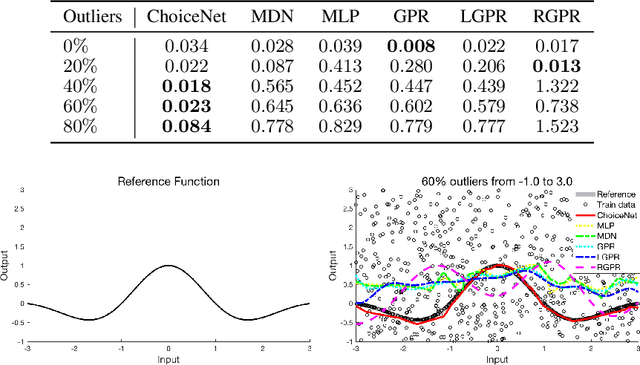
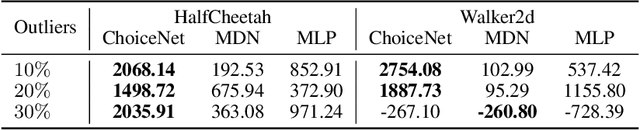
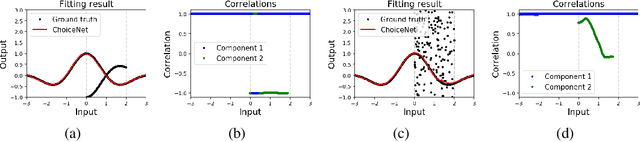
In this paper, we focus on the supervised learning problem with corrupted training data. We assume that the training dataset is generated from a mixture of a target distribution and other unknown distributions. We estimate the quality of each data by revealing the correlation between the generated distribution and the target distribution. To this end, we present a novel framework referred to here as ChoiceNet that can robustly infer the target distribution in the presence of inconsistent data. We demonstrate that the proposed framework is applicable to both classification and regression tasks. ChoiceNet is evaluated in comprehensive experiments, where we show that it constantly outperforms existing baseline methods in the handling of noisy data. Particularly, ChoiceNet is successfully applied to autonomous driving tasks where it learns a safe driving policy from a dataset with mixed qualities. In the classification task, we apply the proposed method to the MNIST and CIFAR-10 datasets and it shows superior performances in terms of robustness to noisy labels.
PVANet: Lightweight Deep Neural Networks for Real-time Object Detection
Dec 09, 2016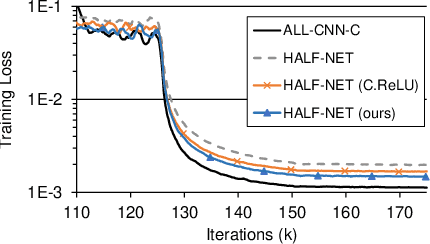
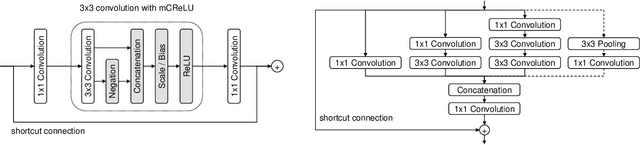
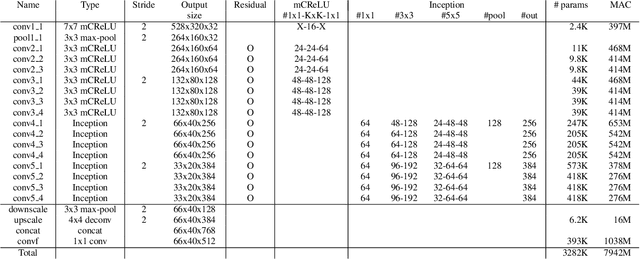
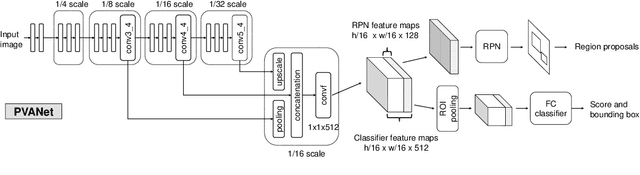
In object detection, reducing computational cost is as important as improving accuracy for most practical usages. This paper proposes a novel network structure, which is an order of magnitude lighter than other state-of-the-art networks while maintaining the accuracy. Based on the basic principle of more layers with less channels, this new deep neural network minimizes its redundancy by adopting recent innovations including C.ReLU and Inception structure. We also show that this network can be trained efficiently to achieve solid results on well-known object detection benchmarks: 84.9% and 84.2% mAP on VOC2007 and VOC2012 while the required compute is less than 10% of the recent ResNet-101.
PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
Sep 30, 2016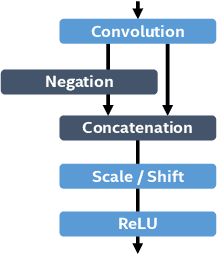
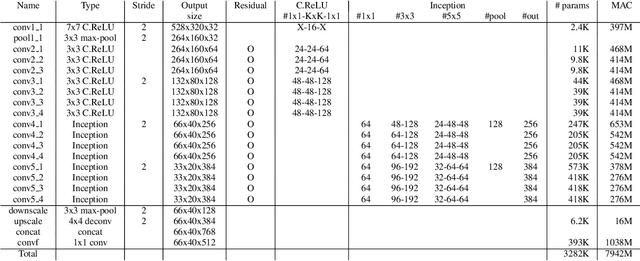
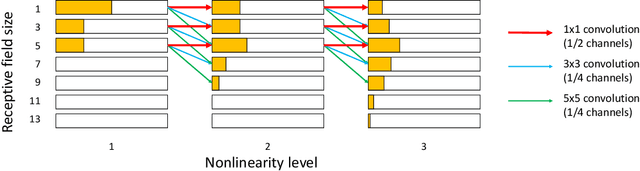
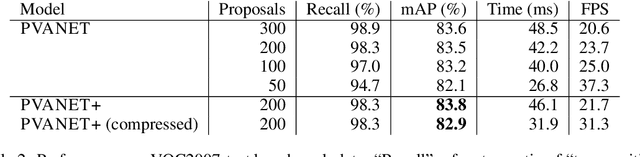
This paper presents how we can achieve the state-of-the-art accuracy in multi-category object detection task while minimizing the computational cost by adapting and combining recent technical innovations. Following the common pipeline of "CNN feature extraction + region proposal + RoI classification", we mainly redesign the feature extraction part, since region proposal part is not computationally expensive and classification part can be efficiently compressed with common techniques like truncated SVD. Our design principle is "less channels with more layers" and adoption of some building blocks including concatenated ReLU, Inception, and HyperNet. The designed network is deep and thin and trained with the help of batch normalization, residual connections, and learning rate scheduling based on plateau detection. We obtained solid results on well-known object detection benchmarks: 83.8% mAP (mean average precision) on VOC2007 and 82.5% mAP on VOC2012 (2nd place), while taking only 750ms/image on Intel i7-6700K CPU with a single core and 46ms/image on NVIDIA Titan X GPU. Theoretically, our network requires only 12.3% of the computational cost compared to ResNet-101, the winner on VOC2012.