 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Regularization for Semi-Supervised Learning
Jan 17, 2022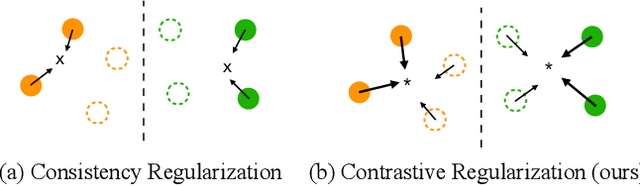
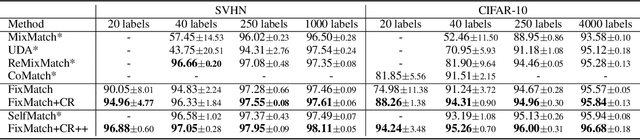
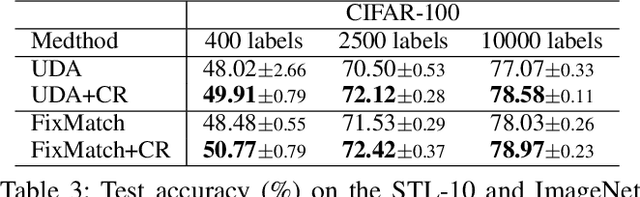

Consistency regularization on label predictions becomes a fundamental technique in semi-supervised learning, but it still requires a large number of training iterations for high performance. In this study, we analyze that the consistency regularization restricts the propagation of labeling information due to the exclusion of samples with unconfident pseudo-labels in the model updates. Then, we propose contrastive regularization to improve both efficiency and accuracy of the consistency regularization by well-clustered features of unlabeled data. In specific, after strongly augmented samples are assigned to clusters by their pseudo-labels, our contrastive regularization updates the model so that the features with confident pseudo-labels aggregate the features in the same cluster, while pushing away features in different clusters. As a result, the information of confident pseudo-labels can be effectively propagated into more unlabeled samples during training by the well-clustered features. On benchmarks of semi-supervised learning tasks, our contrastive regularization improves the previous consistency-based methods and achieves state-of-the-art results, especially with fewer training iterations. Our method also shows robust performance on open-set semi-supervised learning where unlabeled data includes out-of-distribution samples.
Regularizing Attention Networks for Anomaly Detection in Visual Question Answering
Sep 21, 2020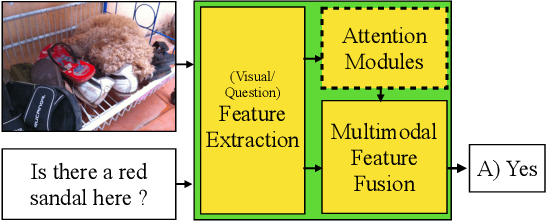
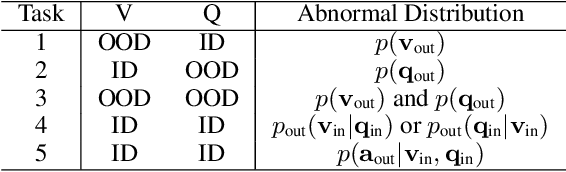

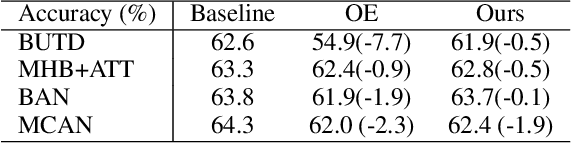
For stability and reliability of real-world applications, the robustness of DNNs in unimodal tasks has been evaluated. However, few studies consider abnormal situations that a visual question answering (VQA) model might encounter at test time after deployment in the real-world. In this study, we evaluate the robustness of state-of-the-art VQA models to five different anomalies, including worst-case scenarios, the most frequent scenarios, and the current limitation of VQA models. Different from the results in unimodal tasks, the maximum confidence of answers in VQA models cannot detect anomalous inputs, and post-training of the outputs, such as outlier exposure, is ineffective for VQA models. Thus, we propose an attention-based method, which uses confidence of reasoning between input images and questions and shows much more promising results than the previous methods in unimodal tasks. In addition, we show that a maximum entropy regularization of attention networks can significantly improve the attention-based anomaly detection of the VQA models. Thanks to the simplicity, attention-based anomaly detection and the regularization are model-agnostic methods, which can be used for various cross-modal attentions in the state-of-the-art VQA models. The results imply that cross-modal attention in VQA is important to improve not only VQA accuracy, but also the robustness to various anomalies.
Soft Labeling Affects Out-of-Distribution Detection of Deep Neural Networks
Jul 07, 2020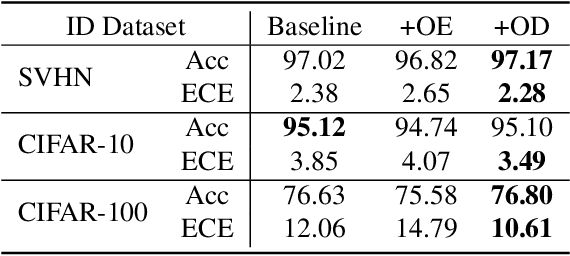
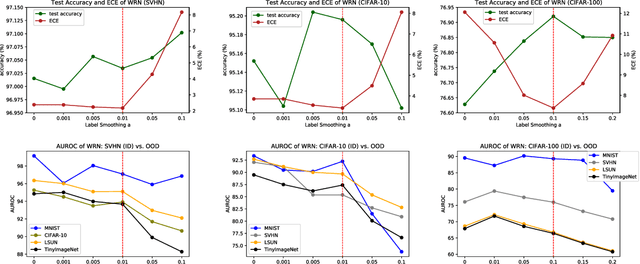
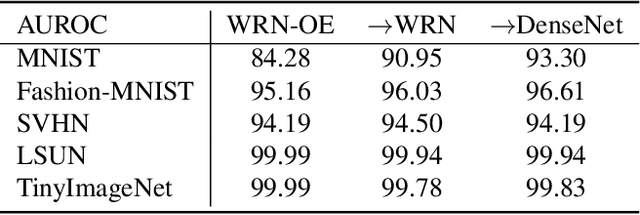
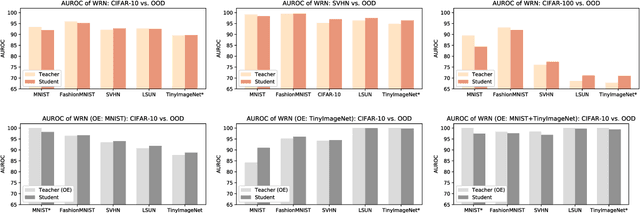
Soft labeling becomes a common output regularization for generalization and model compression of deep neural networks. However, the effect of soft labeling on out-of-distribution (OOD) detection, which is an important topic of machine learning safety, is not explored. In this study, we show that soft labeling can determine OOD detection performance. Specifically, how to regularize outputs of incorrect classes by soft labeling can deteriorate or improve OOD detection. Based on the empirical results, we postulate a future work for OOD-robust DNNs: a proper output regularization by soft labeling can construct OOD-robust DNNs without additional training of OOD samples or modifying the models, while improving classification accuracy.
Demand Forecasting from Spatiotemporal Data with Graph Networks and Temporal-Guided Embedding
May 26, 2019
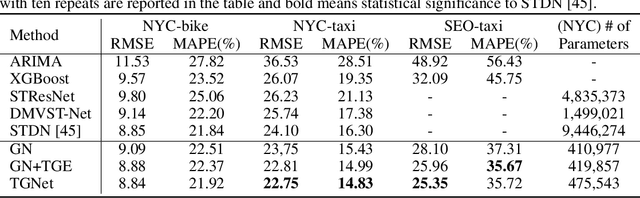
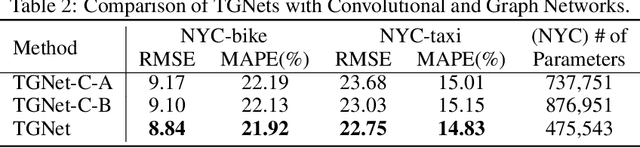
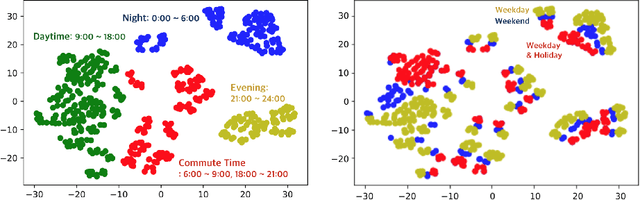
Short-term demand forecasting models commonly combine convolutional and recurrent layers to extract complex spatiotemporal patterns in data. Long-term histories are also used to consider periodicity and seasonality patterns as time series data. In this study, we propose an efficient architecture, Temporal-Guided Network (TGNet), which utilizes graph networks and temporal-guided embedding. Graph networks extract invariant features to permutations of adjacent regions instead of convolutional layers. Temporal-guided embedding explicitly learns temporal contexts from training data and is substituted for the input of long-term histories from days/weeks ago. TGNet learns an autoregressive model, conditioned on temporal contexts of forecasting targets from temporal-guided embedding. Finally, our model achieves competitive performances with other baselines on three spatiotemporal demand dataset from real-world, but the number of trainable parameters is about 20 times smaller than a state-of-the-art baseline. We also show that temporal-guided embedding learns temporal contexts as intended and TGNet has robust forecasting performances even to atypical event situations.
PVANet: Lightweight Deep Neural Networks for Real-time Object Detection
Dec 09, 2016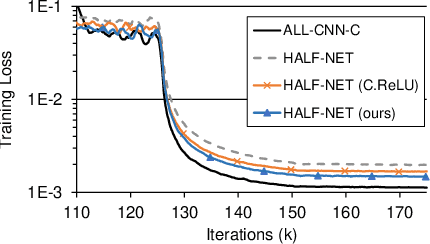
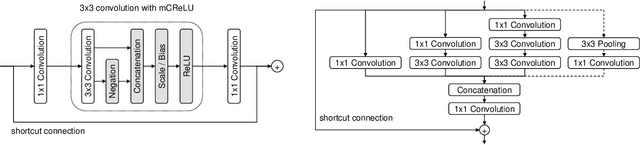
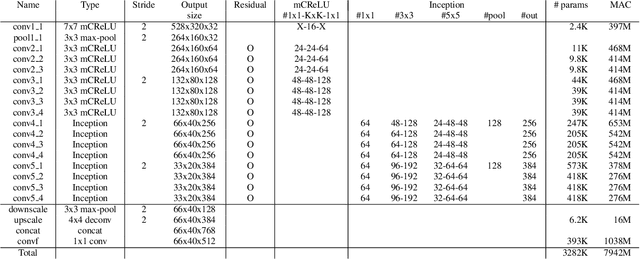
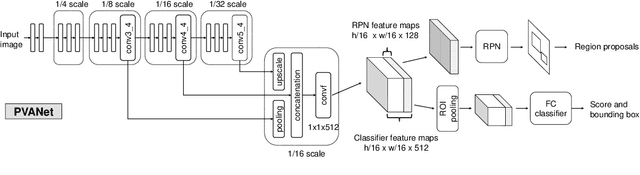
In object detection, reducing computational cost is as important as improving accuracy for most practical usages. This paper proposes a novel network structure, which is an order of magnitude lighter than other state-of-the-art networks while maintaining the accuracy. Based on the basic principle of more layers with less channels, this new deep neural network minimizes its redundancy by adopting recent innovations including C.ReLU and Inception structure. We also show that this network can be trained efficiently to achieve solid results on well-known object detection benchmarks: 84.9% and 84.2% mAP on VOC2007 and VOC2012 while the required compute is less than 10% of the recent ResNet-101.
PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
Sep 30, 2016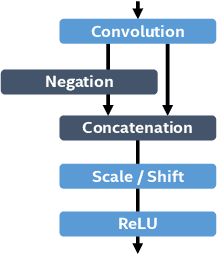
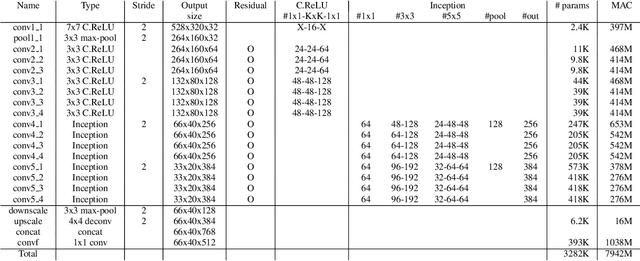
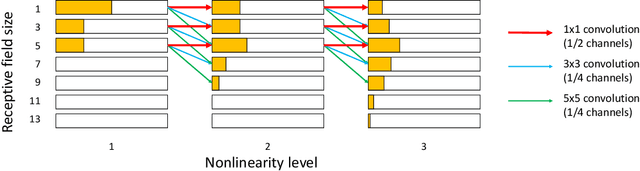
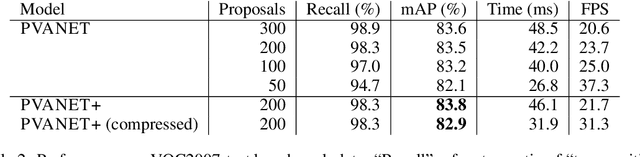
This paper presents how we can achieve the state-of-the-art accuracy in multi-category object detection task while minimizing the computational cost by adapting and combining recent technical innovations. Following the common pipeline of "CNN feature extraction + region proposal + RoI classification", we mainly redesign the feature extraction part, since region proposal part is not computationally expensive and classification part can be efficiently compressed with common techniques like truncated SVD. Our design principle is "less channels with more layers" and adoption of some building blocks including concatenated ReLU, Inception, and HyperNet. The designed network is deep and thin and trained with the help of batch normalization, residual connections, and learning rate scheduling based on plateau detection. We obtained solid results on well-known object detection benchmarks: 83.8% mAP (mean average precision) on VOC2007 and 82.5% mAP on VOC2012 (2nd place), while taking only 750ms/image on Intel i7-6700K CPU with a single core and 46ms/image on NVIDIA Titan X GPU. Theoretically, our network requires only 12.3% of the computational cost compared to ResNet-101, the winner on VOC2012.