 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARTA: Scalable and Principled Benchmark of Tree-Structured Multi-hop QA over Text and Tables
Feb 26, 2026Real-world Table-Text question answering (QA) tasks require models that can reason across long text and source tables, traversing multiple hops and executing complex operations such as aggregation. Yet existing benchmarks are small, manually curated - and therefore error-prone - and contain shallow questions that seldom demand more than two hops or invoke aggregations, grouping, or other advanced analytical operations expressible in natural-language queries. We present SPARTA, an end-to-end construction framework that automatically generates large-scale Table-Text QA benchmarks with lightweight human validation, requiring only one quarter of the annotation time of HybridQA. The framework first constructs a reference fact database by enriching each source table with grounding tables whose tuples are atomic facts automatically extracted from the accompanying unstructured passages, then synthesizes nested queries whose number of nested predicates matches the desired hop count. To ensure that every SQL statement is executable and that its verbalization yields a fluent, human-sounding question, we propose two novel techniques: provenance-based refinement, which rewrites any syntactically valid query that returns a non-empty result, and realistic-structure enforcement, which confines generation to post-order traversals of the query graph. The resulting pipeline produces thousands of high-fidelity question-answer pairs covering aggregations, grouping, and deep multi-hop reasoning across text and tables. On SPARTA, state-of-the-art models that reach over 70 F1 on HybridQA or over 50 F1 on OTT-QA drop by more than 30 F1 points, exposing fundamental weaknesses in current cross-modal reasoning. Our benchmark, construction code, and baseline models are available at https://github.com/pshlego/SPARTA/tree/main.
* 10 pages, 5 figures. Published as a conference paper at ICLR 2026. Project page: https://sparta-projectpage.github.io/
LILaC: Late Interacting in Layered Component Graph for Open-domain Multimodal Multihop Retrieval
Feb 04, 2026Multimodal document retrieval aims to retrieve query-relevant components from documents composed of textual, tabular, and visual elements. An effective multimodal retriever needs to handle two main challenges: (1) mitigate the effect of irrelevant contents caused by fixed, single-granular retrieval units, and (2) support multihop reasoning by effectively capturing semantic relationships among components within and across documents. To address these challenges, we propose LILaC, a multimodal retrieval framework featuring two core innovations. First, we introduce a layered component graph, explicitly representing multimodal information at two layers - each representing coarse and fine granularity - facilitating efficient yet precise reasoning. Second, we develop a late-interaction-based subgraph retrieval method, an edge-based approach that initially identifies coarse-grained nodes for efficient candidate generation, then performs fine-grained reasoning via late interaction. Extensive experiments demonstrate that LILaC achieves state-of-the-art retrieval performance on all five benchmarks, notably without additional fine-tuning. We make the artifacts publicly available at github.com/joohyung00/lilac.
Failure is Feedback: History-Aware Backtracking for Agentic Traversal in Multimodal Graphs
Feb 03, 2026Open-domain multimodal document retrieval aims to retrieve specific components (paragraphs, tables, or images) from large and interconnected document corpora. Existing graph-based retrieval approaches typically rely on a uniform similarity metric that overlooks hop-specific semantics, and their rigid pre-defined plans hinder dynamic error correction. These limitations suggest that a retriever should adapt its reasoning to the evolving context and recover intelligently from dead ends. To address these needs, we propose Failure is Feedback (FiF), which casts subgraph retrieval as a sequential decision process and introduces two key innovations. (i) We introduce a history-aware backtracking mechanism; unlike standard backtracking that simply reverts the state, our approach piggybacks on the context of failed traversals, leveraging insights from previous failures. (ii) We implement an economically-rational agentic workflow. Unlike conventional agents with static strategies, our orchestrator employs a cost-aware traversal method to dynamically manage the trade-off between retrieval accuracy and inference costs, escalating to intensive LLM-based reasoning only when the prior failure justifies the additional computational investment. Extensive experiments show that FiF achieves state-of-the-art retrieval on the benchmarks of MultimodalQA, MMCoQA and WebQA.
Bring My Cup! Personalizing Vision-Language-Action Models with Visual Attentive Prompting
Dec 23, 2025While Vision-Language-Action (VLA) models generalize well to generic instructions, they struggle with personalized commands such as "bring my cup", where the robot must act on one specific instance among visually similar objects. We study this setting of manipulating personal objects, in which a VLA must identify and control a user-specific object unseen during training using only a few reference images. To address this challenge, we propose Visual Attentive Prompting (VAP), a simple-yet-effective training-free perceptual adapter that equips frozen VLAs with top-down selective attention. VAP treats the reference images as a non-parametric visual memory, grounds the personal object in the scene through open-vocabulary detection and embedding-based matching, and then injects this grounding as a visual prompt by highlighting the object and rewriting the instruction. We construct two simulation benchmarks, Personalized-SIMPLER and Personalized-VLABench, and a real-world tabletop benchmark to evaluate personalized manipulation across multiple robots and tasks. Experiments show that VAP consistently outperforms generic policies and token-learning baselines in both success rate and correct-object manipulation, helping to bridge the gap between semantic understanding and instance-level control.
Locality-Aware Generalizable Implicit Neural Representation
Oct 12, 2023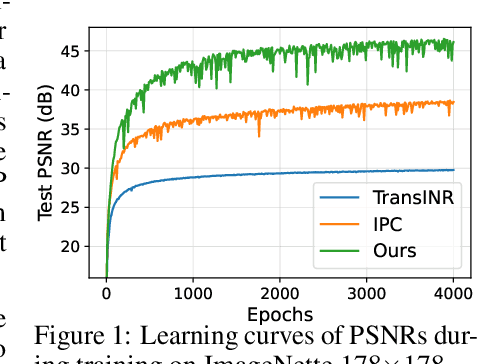
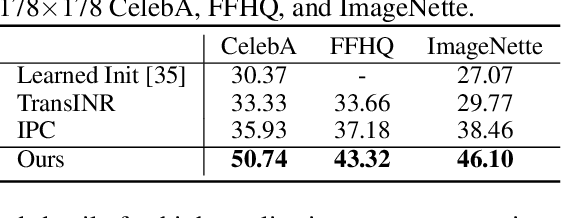
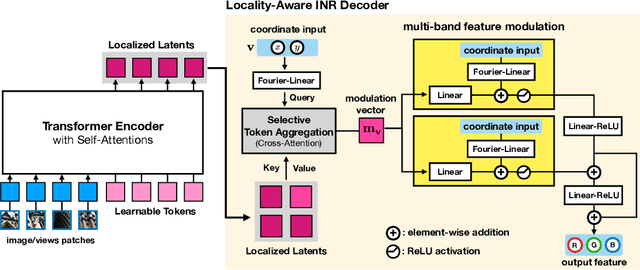

Generalizable implicit neural representation (INR) enables a single continuous function, i.e., a coordinate-based neural network, to represent multiple data instances by modulating its weights or intermediate features using latent codes. However, the expressive power of the state-of-the-art modulation is limited due to its inability to localize and capture fine-grained details of data entities such as specific pixels and rays. To address this issue, we propose a novel framework for generalizable INR that combines a transformer encoder with a locality-aware INR decoder. The transformer encoder predicts a set of latent tokens from a data instance to encode local information into each latent token. The locality-aware INR decoder extracts a modulation vector by selectively aggregating the latent tokens via cross-attention for a coordinate input and then predicts the output by progressively decoding with coarse-to-fine modulation through multiple frequency bandwidths. The selective token aggregation and the multi-band feature modulation enable us to learn locality-aware representation in spatial and spectral aspects, respectively. Our framework significantly outperforms previous generalizable INRs and validates the usefulness of the locality-aware latents for downstream tasks such as image generation.
Generalizable Implicit Neural Representations via Instance Pattern Composers
Nov 23, 2022



Despite recent advances in implicit neural representations (INRs), it remains challenging for a coordinate-based multi-layer perceptron (MLP) of INRs to learn a common representation across data instances and generalize it for unseen instances. In this work, we introduce a simple yet effective framework for generalizable INRs that enables a coordinate-based MLP to represent complex data instances by modulating only a small set of weights in an early MLP layer as an instance pattern composer; the remaining MLP weights learn pattern composition rules for common representations across instances. Our generalizable INR framework is fully compatible with existing meta-learning and hypernetworks in learning to predict the modulated weight for unseen instances. Extensive experiments demonstrate that our method achieves high performance on a wide range of domains such as an audio, image, and 3D object, while the ablation study validates our weight modulation.
Draft-and-Revise: Effective Image Generation with Contextual RQ-Transformer
Jun 09, 2022
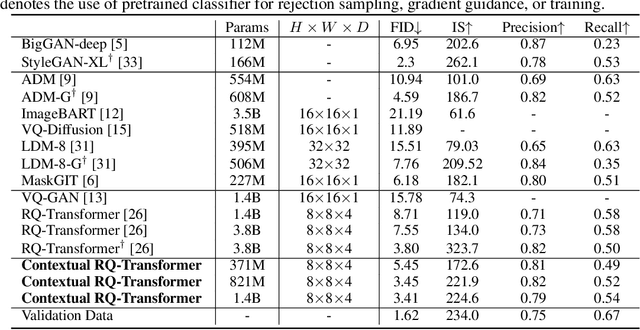
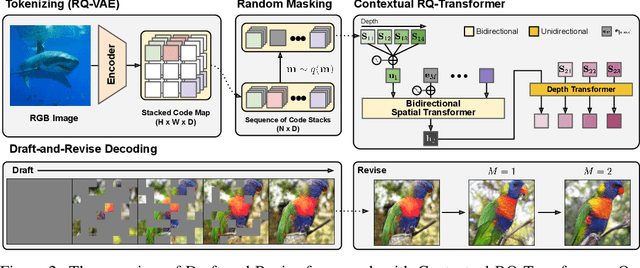
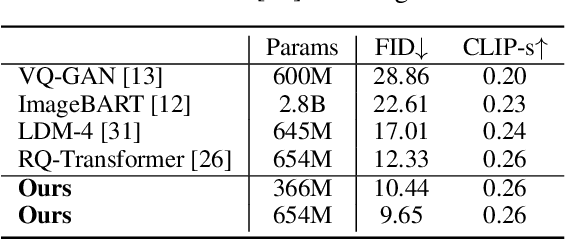
Although autoregressive models have achieved promising results on image generation, their unidirectional generation process prevents the resultant images from fully reflecting global contexts. To address the issue, we propose an effective image generation framework of Draft-and-Revise with Contextual RQ-transformer to consider global contexts during the generation process. As a generalized VQ-VAE, RQ-VAE first represents a high-resolution image as a sequence of discrete code stacks. After code stacks in the sequence are randomly masked, Contextual RQ-Transformer is trained to infill the masked code stacks based on the unmasked contexts of the image. Then, Contextual RQ-Transformer uses our two-phase decoding, Draft-and-Revise, and generates an image, while exploiting the global contexts of the image during the generation process. Specifically. in the draft phase, our model first focuses on generating diverse images despite rather low quality. Then, in the revise phase, the model iteratively improves the quality of images, while preserving the global contexts of generated images. In experiments, our method achieves state-of-the-art results on conditional image generation. We also validate that the Draft-and-Revise decoding can achieve high performance by effectively controlling the quality-diversity trade-off in image generation.
Autoregressive Image Generation using Residual Quantization
Mar 09, 2022
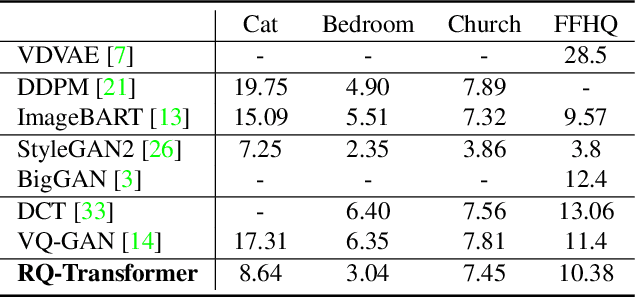
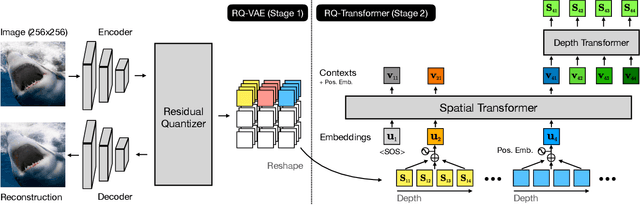

For autoregressive (AR) modeling of high-resolution images, vector quantization (VQ) represents an image as a sequence of discrete codes. A short sequence length is important for an AR model to reduce its computational costs to consider long-range interactions of codes. However, we postulate that previous VQ cannot shorten the code sequence and generate high-fidelity images together in terms of the rate-distortion trade-off. In this study, we propose the two-stage framework, which consists of Residual-Quantized VAE (RQ-VAE) and RQ-Transformer, to effectively generate high-resolution images. Given a fixed codebook size, RQ-VAE can precisely approximate a feature map of an image and represent the image as a stacked map of discrete codes. Then, RQ-Transformer learns to predict the quantized feature vector at the next position by predicting the next stack of codes. Thanks to the precise approximation of RQ-VAE, we can represent a 256$\times$256 image as 8$\times$8 resolution of the feature map, and RQ-Transformer can efficiently reduce the computational costs. Consequently, our framework outperforms the existing AR models on various benchmarks of unconditional and conditional image generation. Our approach also has a significantly faster sampling speed than previous AR models to generate high-quality images.
Contrastive Regularization for Semi-Supervised Learning
Jan 17, 2022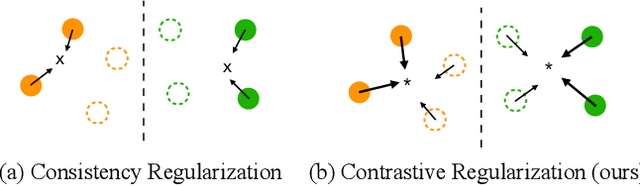
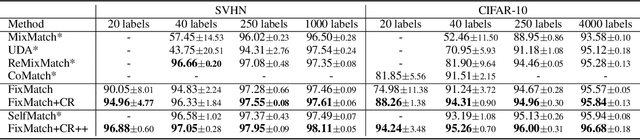
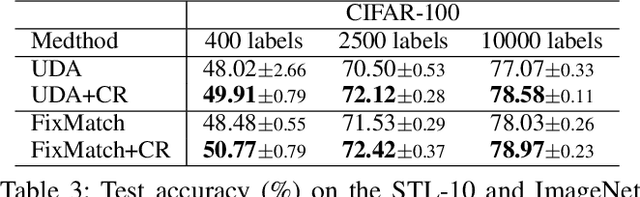

Consistency regularization on label predictions becomes a fundamental technique in semi-supervised learning, but it still requires a large number of training iterations for high performance. In this study, we analyze that the consistency regularization restricts the propagation of labeling information due to the exclusion of samples with unconfident pseudo-labels in the model updates. Then, we propose contrastive regularization to improve both efficiency and accuracy of the consistency regularization by well-clustered features of unlabeled data. In specific, after strongly augmented samples are assigned to clusters by their pseudo-labels, our contrastive regularization updates the model so that the features with confident pseudo-labels aggregate the features in the same cluster, while pushing away features in different clusters. As a result, the information of confident pseudo-labels can be effectively propagated into more unlabeled samples during training by the well-clustered features. On benchmarks of semi-supervised learning tasks, our contrastive regularization improves the previous consistency-based methods and achieves state-of-the-art results, especially with fewer training iterations. Our method also shows robust performance on open-set semi-supervised learning where unlabeled data includes out-of-distribution samples.
Regularizing Attention Networks for Anomaly Detection in Visual Question Answering
Sep 21, 2020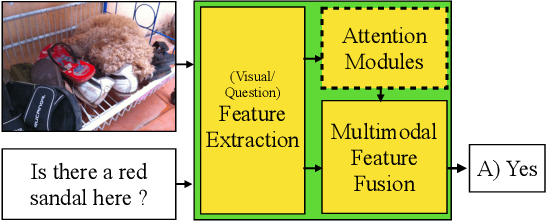
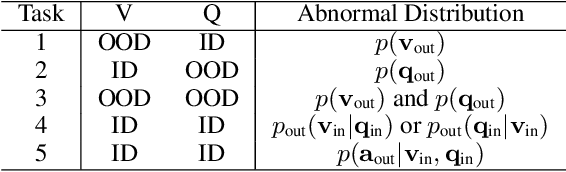

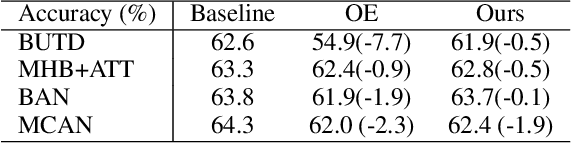
For stability and reliability of real-world applications, the robustness of DNNs in unimodal tasks has been evaluated. However, few studies consider abnormal situations that a visual question answering (VQA) model might encounter at test time after deployment in the real-world. In this study, we evaluate the robustness of state-of-the-art VQA models to five different anomalies, including worst-case scenarios, the most frequent scenarios, and the current limitation of VQA models. Different from the results in unimodal tasks, the maximum confidence of answers in VQA models cannot detect anomalous inputs, and post-training of the outputs, such as outlier exposure, is ineffective for VQA models. Thus, we propose an attention-based method, which uses confidence of reasoning between input images and questions and shows much more promising results than the previous methods in unimodal tasks. In addition, we show that a maximum entropy regularization of attention networks can significantly improve the attention-based anomaly detection of the VQA models. Thanks to the simplicity, attention-based anomaly detection and the regularization are model-agnostic methods, which can be used for various cross-modal attentions in the state-of-the-art VQA models. The results imply that cross-modal attention in VQA is important to improve not only VQA accuracy, but also the robustness to various anomalies.