 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDraft-and-Revise: Effective Image Generation with Contextual RQ-Transformer
Paper and Code

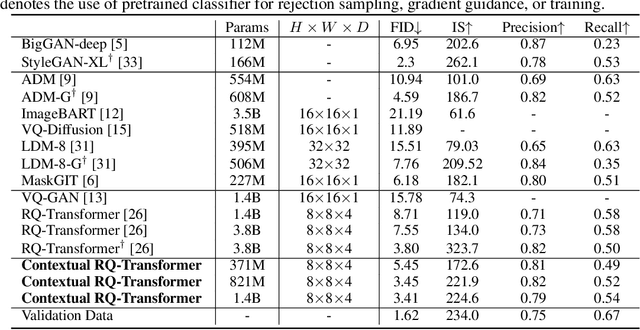
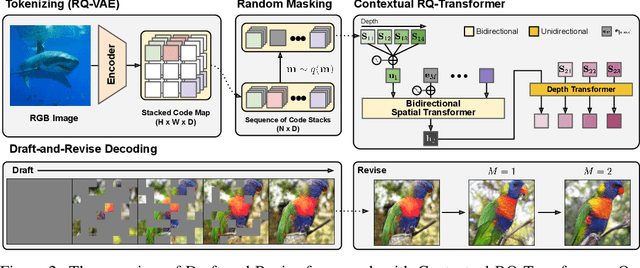
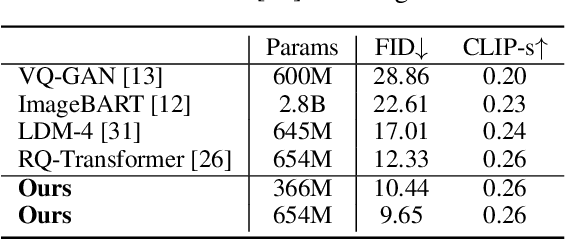
Although autoregressive models have achieved promising results on image generation, their unidirectional generation process prevents the resultant images from fully reflecting global contexts. To address the issue, we propose an effective image generation framework of Draft-and-Revise with Contextual RQ-transformer to consider global contexts during the generation process. As a generalized VQ-VAE, RQ-VAE first represents a high-resolution image as a sequence of discrete code stacks. After code stacks in the sequence are randomly masked, Contextual RQ-Transformer is trained to infill the masked code stacks based on the unmasked contexts of the image. Then, Contextual RQ-Transformer uses our two-phase decoding, Draft-and-Revise, and generates an image, while exploiting the global contexts of the image during the generation process. Specifically. in the draft phase, our model first focuses on generating diverse images despite rather low quality. Then, in the revise phase, the model iteratively improves the quality of images, while preserving the global contexts of generated images. In experiments, our method achieves state-of-the-art results on conditional image generation. We also validate that the Draft-and-Revise decoding can achieve high performance by effectively controlling the quality-diversity trade-off in image generation.