 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViT-ReciproCAM: Gradient and Attention-Free Visual Explanations for Vision Transformer
Oct 04, 2023This paper presents a novel approach to address the challenges of understanding the prediction process and debugging prediction errors in Vision Transformers (ViT), which have demonstrated superior performance in various computer vision tasks such as image classification and object detection. While several visual explainability techniques, such as CAM, Grad-CAM, Score-CAM, and Recipro-CAM, have been extensively researched for Convolutional Neural Networks (CNNs), limited research has been conducted on ViT. Current state-of-the-art solutions for ViT rely on class agnostic Attention-Rollout and Relevance techniques. In this work, we propose a new gradient-free visual explanation method for ViT, called ViT-ReciproCAM, which does not require attention matrix and gradient information. ViT-ReciproCAM utilizes token masking and generated new layer outputs from the target layer's input to exploit the correlation between activated tokens and network predictions for target classes. Our proposed method outperforms the state-of-the-art Relevance method in the Average Drop-Coherence-Complexity (ADCC) metric by $4.58\%$ to $5.80\%$ and generates more localized saliency maps. Our experiments demonstrate the effectiveness of ViT-ReciproCAM and showcase its potential for understanding and debugging ViT models. Our proposed method provides an efficient and easy-to-implement alternative for generating visual explanations, without requiring attention and gradient information, which can be beneficial for various applications in the field of computer vision.
Recipro-CAM: Gradient-free reciprocal class activation map
Sep 28, 2022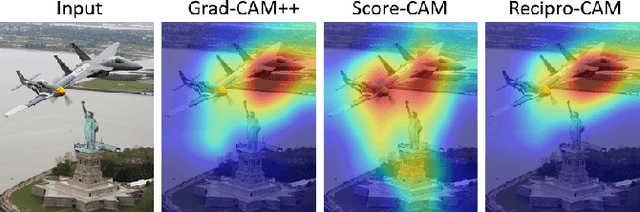
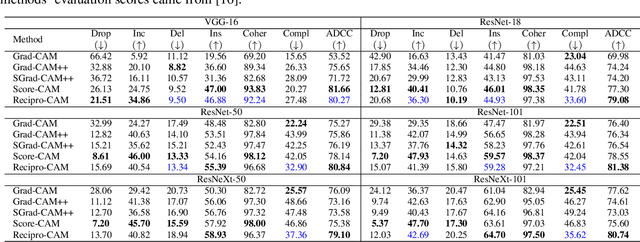


Convolutional neural network (CNN) becomes one of the most popular and prominent deep learning architectures for computer vision, but its black box feature hides the internal prediction process. For this reason, AI practitioners have shed light on explainable AI to provide the interpretability of the model behavior. In particular, class activation map (CAM) and Grad-CAM based methods have shown promise results, but they have architectural limitation or gradient computing burden. To resolve these, Score-CAM has been suggested as a gradient-free method, however, it requires more execution time compared to CAM or Grad-CAM based methods. Therefore, we propose a lightweight architecture and gradient free Reciprocal CAM (Recipro-CAM) by spatially masking the extracted feature maps to exploit the correlation between activation maps and network outputs. With the proposed method, we achieved the gains of 1:78 - 3:72% in the ResNet family compared to Score-CAM in Average Drop- Coherence-Complexity (ADCC) metric, excluding the VGG-16 (1:39% drop). In addition, Recipro-CAM exhibits a saliency map generation rate similar to Grad-CAM and approximately 148 times faster than Score-CAM.
Unsupervised Model Drift Estimation with Batch Normalization Statistics for Dataset Shift Detection and Model Selection
Jul 01, 2021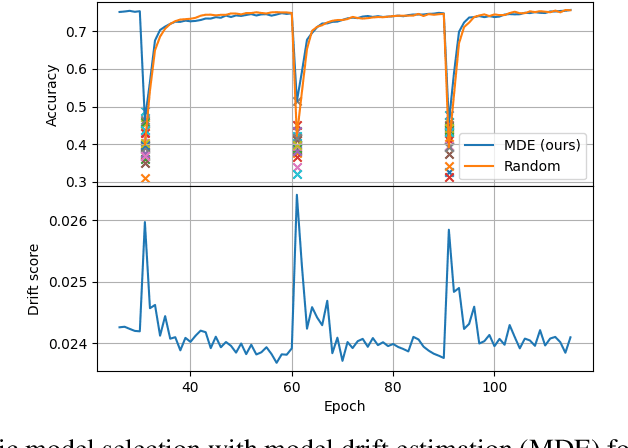



While many real-world data streams imply that they change frequently in a nonstationary way, most of deep learning methods optimize neural networks on training data, and this leads to severe performance degradation when dataset shift happens. However, it is less possible to annotate or inspect newly streamed data by humans, and thus it is desired to measure model drift at inference time in an unsupervised manner. In this paper, we propose a novel method of model drift estimation by exploiting statistics of batch normalization layer on unlabeled test data. To remedy possible sampling error of streamed input data, we adopt low-rank approximation to each representational layer. We show the effectiveness of our method not only on dataset shift detection but also on model selection when there are multiple candidate models among model zoo or training trajectories in an unsupervised way. We further demonstrate the consistency of our method by comparing model drift scores between different network architectures.