 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Item Representation Learning for Cold-start Content Recommendations
Apr 22, 2024


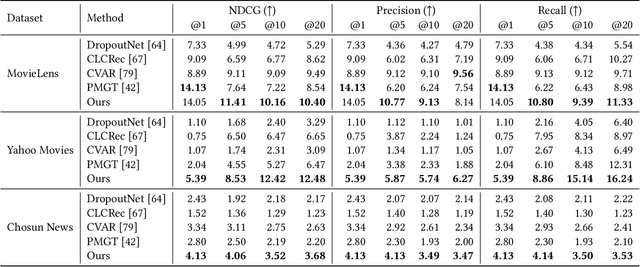
Cold-start item recommendation is a long-standing challenge in recommendation systems. A common remedy is to use a content-based approach, but rich information from raw contents in various forms has not been fully utilized. In this paper, we propose a domain/data-agnostic item representation learning framework for cold-start recommendations, naturally equipped with multimodal alignment among various features by adopting a Transformer-based architecture. Our proposed model is end-to-end trainable completely free from classification labels, not just costly to collect but suboptimal for recommendation-purpose representation learning. From extensive experiments on real-world movie and news recommendation benchmarks, we verify that our approach better preserves fine-grained user taste than state-of-the-art baselines, universally applicable to multiple domains at large scale.
Modality-Aware Representation Learning for Zero-shot Sketch-based Image Retrieval
Jan 10, 2024



Zero-shot learning offers an efficient solution for a machine learning model to treat unseen categories, avoiding exhaustive data collection. Zero-shot Sketch-based Image Retrieval (ZS-SBIR) simulates real-world scenarios where it is hard and costly to collect paired sketch-photo samples. We propose a novel framework that indirectly aligns sketches and photos by contrasting them through texts, removing the necessity of access to sketch-photo pairs. With an explicit modality encoding learned from data, our approach disentangles modality-agnostic semantics from modality-specific information, bridging the modality gap and enabling effective cross-modal content retrieval within a joint latent space. From comprehensive experiments, we verify the efficacy of the proposed model on ZS-SBIR, and it can be also applied to generalized and fine-grained settings.
Unsupervised Model Drift Estimation with Batch Normalization Statistics for Dataset Shift Detection and Model Selection
Jul 01, 2021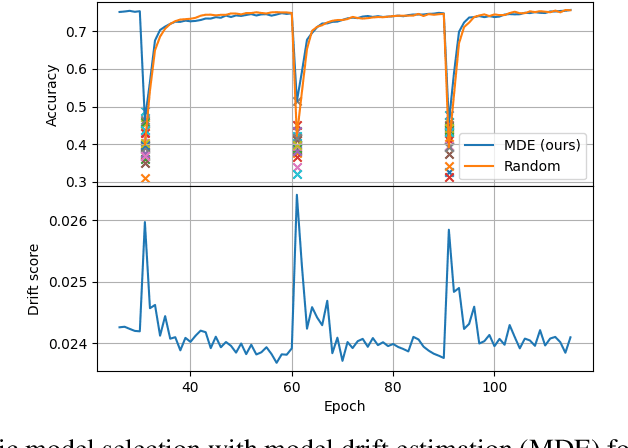



While many real-world data streams imply that they change frequently in a nonstationary way, most of deep learning methods optimize neural networks on training data, and this leads to severe performance degradation when dataset shift happens. However, it is less possible to annotate or inspect newly streamed data by humans, and thus it is desired to measure model drift at inference time in an unsupervised manner. In this paper, we propose a novel method of model drift estimation by exploiting statistics of batch normalization layer on unlabeled test data. To remedy possible sampling error of streamed input data, we adopt low-rank approximation to each representational layer. We show the effectiveness of our method not only on dataset shift detection but also on model selection when there are multiple candidate models among model zoo or training trajectories in an unsupervised way. We further demonstrate the consistency of our method by comparing model drift scores between different network architectures.