 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLOT: Pseudo-Labeling via Video Object Tracking for Scalable Monocular 3D Object Detection
Jul 03, 2025Monocular 3D object detection (M3OD) has long faced challenges due to data scarcity caused by high annotation costs and inherent 2D-to-3D ambiguity. Although various weakly supervised methods and pseudo-labeling methods have been proposed to address these issues, they are mostly limited by domain-specific learning or rely solely on shape information from a single observation. In this paper, we propose a novel pseudo-labeling framework that uses only video data and is more robust to occlusion, without requiring a multi-view setup, additional sensors, camera poses, or domain-specific training. Specifically, we explore a technique for aggregating the pseudo-LiDARs of both static and dynamic objects across temporally adjacent frames using object point tracking, enabling 3D attribute extraction in scenarios where 3D data acquisition is infeasible. Extensive experiments demonstrate that our method ensures reliable accuracy and strong scalability, making it a practical and effective solution for M3OD.
Channel-wise Noise Scheduled Diffusion for Inverse Rendering in Indoor Scenes
Mar 13, 2025We propose a diffusion-based inverse rendering framework that decomposes a single RGB image into geometry, material, and lighting. Inverse rendering is inherently ill-posed, making it difficult to predict a single accurate solution. To address this challenge, recent generative model-based methods aim to present a range of possible solutions. However, finding a single accurate solution and generating diverse solutions can be conflicting. In this paper, we propose a channel-wise noise scheduling approach that allows a single diffusion model architecture to achieve two conflicting objectives. The resulting two diffusion models, trained with different channel-wise noise schedules, can predict a single highly accurate solution and present multiple possible solutions. The experimental results demonstrate the superiority of our two models in terms of both diversity and accuracy, which translates to enhanced performance in downstream applications such as object insertion and material editing.
Multi-View Pedestrian Occupancy Prediction with a Novel Synthetic Dataset
Dec 18, 2024We address an advanced challenge of predicting pedestrian occupancy as an extension of multi-view pedestrian detection in urban traffic. To support this, we have created a new synthetic dataset called MVP-Occ, designed for dense pedestrian scenarios in large-scale scenes. Our dataset provides detailed representations of pedestrians using voxel structures, accompanied by rich semantic scene understanding labels, facilitating visual navigation and insights into pedestrian spatial information. Furthermore, we present a robust baseline model, termed OmniOcc, capable of predicting both the voxel occupancy state and panoptic labels for the entire scene from multi-view images. Through in-depth analysis, we identify and evaluate the key elements of our proposed model, highlighting their specific contributions and importance.
MAIR++: Improving Multi-view Attention Inverse Rendering with Implicit Lighting Representation
Aug 13, 2024
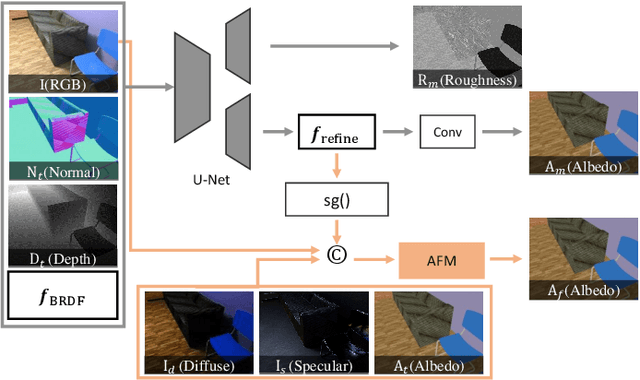


In this paper, we propose a scene-level inverse rendering framework that uses multi-view images to decompose the scene into geometry, SVBRDF, and 3D spatially-varying lighting. While multi-view images have been widely used for object-level inverse rendering, scene-level inverse rendering has primarily been studied using single-view images due to the lack of a dataset containing high dynamic range multi-view images with ground-truth geometry, material, and spatially-varying lighting. To improve the quality of scene-level inverse rendering, a novel framework called Multi-view Attention Inverse Rendering (MAIR) was recently introduced. MAIR performs scene-level multi-view inverse rendering by expanding the OpenRooms dataset, designing efficient pipelines to handle multi-view images, and splitting spatially-varying lighting. Although MAIR showed impressive results, its lighting representation is fixed to spherical Gaussians, which limits its ability to render images realistically. Consequently, MAIR cannot be directly used in applications such as material editing. Moreover, its multi-view aggregation networks have difficulties extracting rich features because they only focus on the mean and variance between multi-view features. In this paper, we propose its extended version, called MAIR++. MAIR++ addresses the aforementioned limitations by introducing an implicit lighting representation that accurately captures the lighting conditions of an image while facilitating realistic rendering. Furthermore, we design a directional attention-based multi-view aggregation network to infer more intricate relationships between views. Experimental results show that MAIR++ not only achieves better performance than MAIR and single-view-based methods, but also displays robust performance on unseen real-world scenes.
VIGFace: Virtual Identity Generation Model for Face Image Synthesis
Mar 13, 2024



Deep learning-based face recognition continues to face challenges due to its reliance on huge datasets obtained from web crawling, which can be costly to gather and raise significant real-world privacy concerns. To address this issue, we propose VIGFace, a novel framework capable of generating synthetic facial images. Initially, we train the face recognition model using a real face dataset and create a feature space for both real and virtual IDs where virtual prototypes are orthogonal to other prototypes. Subsequently, we generate synthetic images by using the diffusion model based on the feature space. Our proposed framework provides two significant benefits. Firstly, it allows for creating virtual facial images without concerns about portrait rights, guaranteeing that the generated virtual face images are clearly differentiated from existing individuals. Secondly, it serves as an effective augmentation method by incorporating real existing images. Further experiments demonstrate the efficacy of our framework, achieving state-of-the-art results from both perspectives without any external data.
MAIR: Multi-view Attention Inverse Rendering with 3D Spatially-Varying Lighting Estimation
Mar 27, 2023



We propose a scene-level inverse rendering framework that uses multi-view images to decompose the scene into geometry, a SVBRDF, and 3D spatially-varying lighting. Because multi-view images provide a variety of information about the scene, multi-view images in object-level inverse rendering have been taken for granted. However, owing to the absence of multi-view HDR synthetic dataset, scene-level inverse rendering has mainly been studied using single-view image. We were able to successfully perform scene-level inverse rendering using multi-view images by expanding OpenRooms dataset and designing efficient pipelines to handle multi-view images, and splitting spatially-varying lighting. Our experiments show that the proposed method not only achieves better performance than single-view-based methods, but also achieves robust performance on unseen real-world scene. Also, our sophisticated 3D spatially-varying lighting volume allows for photorealistic object insertion in any 3D location.
ExtremeNeRF: Few-shot Neural Radiance Fields Under Unconstrained Illumination
Mar 22, 2023



In this paper, we propose a new challenge that synthesizes a novel view in a more practical environment, where the number of input multi-view images is limited and illumination variations are significant. Despite recent success, neural radiance fields (NeRF) require a massive amount of input multi-view images taken under constrained illuminations. To address the problem, we suggest ExtremeNeRF, which utilizes occlusion-aware multiview albedo consistency, supported by geometric alignment and depth consistency. We extract intrinsic image components that should be illumination-invariant across different views, enabling direct appearance comparison between the input and novel view under unconstrained illumination. We provide extensive experimental results for an evaluation of the task, using the newly built NeRF Extreme benchmark, which is the first in-the-wild novel view synthesis benchmark taken under multiple viewing directions and varying illuminations. The project page is at https://seokyeong94.github.io/ExtremeNeRF/
K-FACE: A Large-Scale KIST Face Database in Consideration with Unconstrained Environments
Mar 03, 2021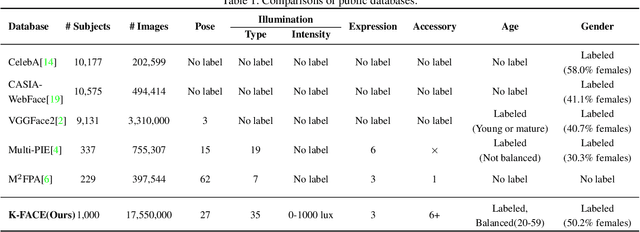
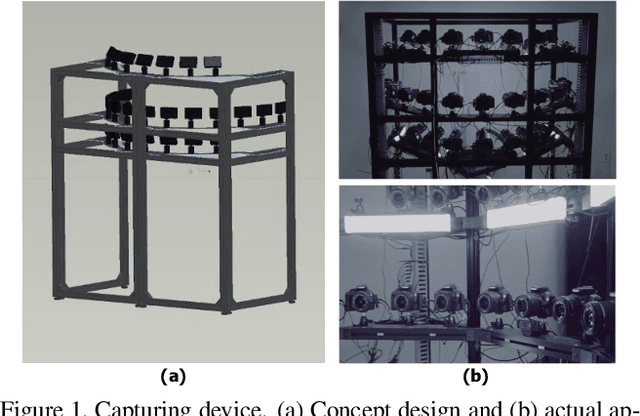
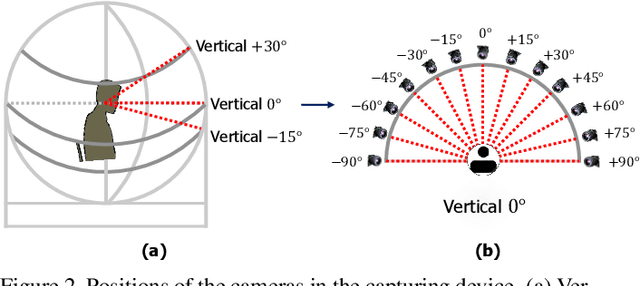
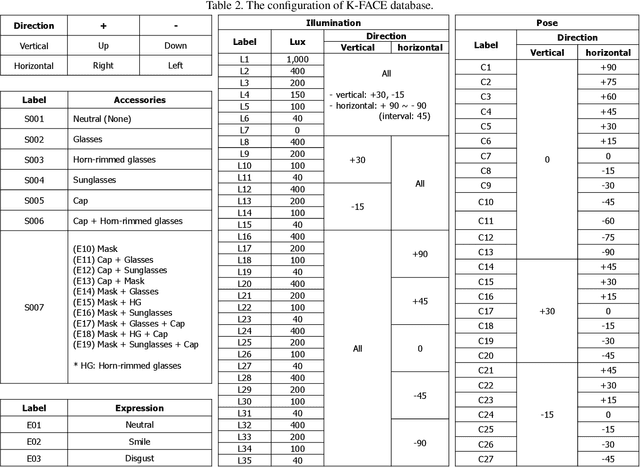
In this paper, we introduce a new large-scale face database from KIST, denoted as K-FACE, and describe a novel capturing device specifically designed to obtain the data. The K-FACE database contains more than 1 million high-quality images of 1,000 subjects selected by considering the ratio of gender and age groups. It includes a variety of attributes, including 27 poses, 35 lighting conditions, three expressions, and occlusions by the combination of five types of accessories. As the K-FACE database is systematically constructed through a hemispherical capturing system with elaborate lighting control and multiple cameras, it is possible to accurately analyze the effects of factors that cause performance degradation, such as poses, lighting changes, and accessories. We consider not only the balance of external environmental factors, such as pose and lighting, but also the balance of personal characteristics such as gender and age group. The gender ratio is the same, while the age groups of subjects are uniformly distributed from the 20s to 50s for both genders. The K-FACE database can be extensively utilized in various vision tasks, such as face recognition, face frontalization, illumination normalization, face age estimation, and three-dimensional face model generation. We expect systematic diversity and uniformity of the K-FACE database to promote these research fields.
A 3D model-based approach for fitting masks to faces in the wild
Mar 01, 2021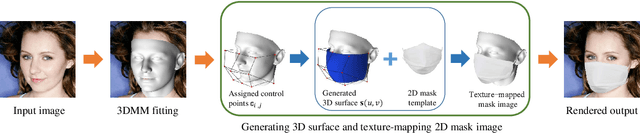
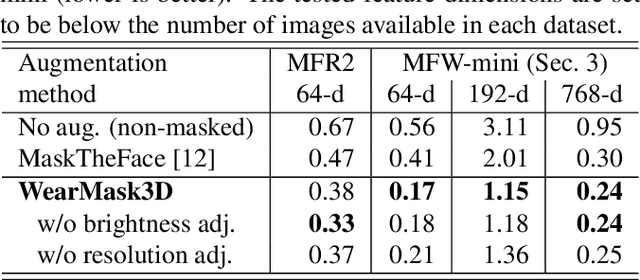

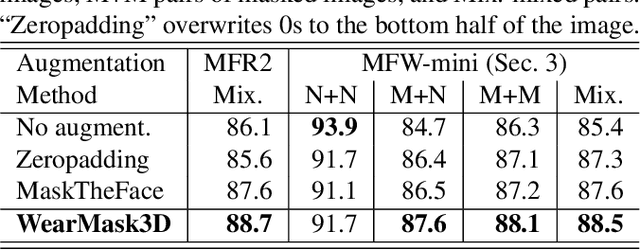
Face recognition research now requires a large number of labelled masked face images in the era of this unprecedented COVID-19 pandemic. Unfortunately, the rapid spread of the virus has left us little time to prepare for such dataset in the wild. To circumvent this issue, we present a 3D model-based approach called WearMask3D for augmenting face images of various poses to the masked face counterparts. Our method proceeds by first fitting a 3D morphable model on the input image, second overlaying the mask surface onto the face model and warping the respective mask texture, and last projecting the 3D mask back to 2D. The mask texture is adapted based on the brightness and resolution of the input image. By working in 3D, our method can produce more natural masked faces of diverse poses from a single mask texture. To compare precisely between different augmentation approaches, we have constructed a dataset comprising masked and unmasked faces with labels called MFW-mini. Experimental results demonstrate WearMask3D, which will be made publicly available, produces more realistic masked images, and utilizing these images for training leads to improved recognition accuracy of masked faces compared to the state-of-the-art.
ElderSim: A Synthetic Data Generation Platform for Human Action Recognition in Eldercare Applications
Oct 28, 2020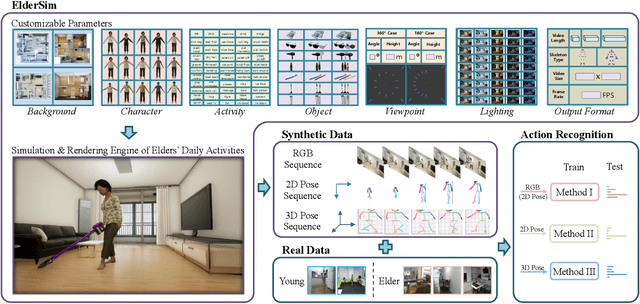
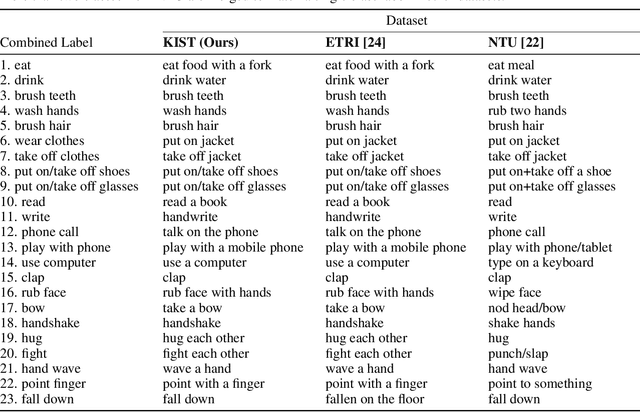
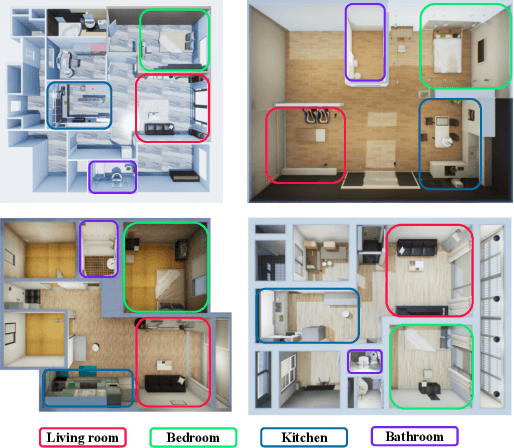

To train deep learning models for vision-based action recognition of elders' daily activities, we need large-scale activity datasets acquired under various daily living environments and conditions. However, most public datasets used in human action recognition either differ from or have limited coverage of elders' activities in many aspects, making it challenging to recognize elders' daily activities well by only utilizing existing datasets. Recently, such limitations of available datasets have actively been compensated by generating synthetic data from realistic simulation environments and using those data to train deep learning models. In this paper, based on these ideas we develop ElderSim, an action simulation platform that can generate synthetic data on elders' daily activities. For 55 kinds of frequent daily activities of the elders, ElderSim generates realistic motions of synthetic characters with various adjustable data-generating options, and provides different output modalities including RGB videos, two- and three-dimensional skeleton trajectories. We then generate KIST SynADL, a large-scale synthetic dataset of elders' activities of daily living, from ElderSim and use the data in addition to real datasets to train three state-of the-art human action recognition models. From the experiments following several newly proposed scenarios that assume different real and synthetic dataset configurations for training, we observe a noticeable performance improvement by augmenting our synthetic data. We also offer guidance with insights for the effective utilization of synthetic data to help recognize elders' daily activities.