 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMAR: Gradient-Driven Multi-Head Attention Rollout for Vision Transformer Interpretability
Apr 28, 2025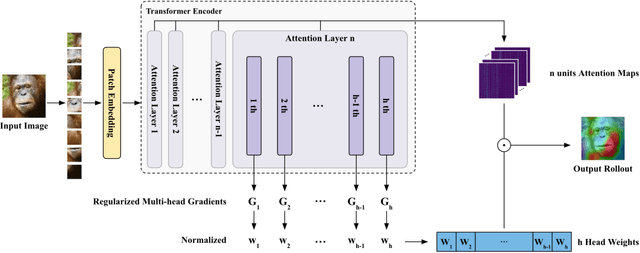
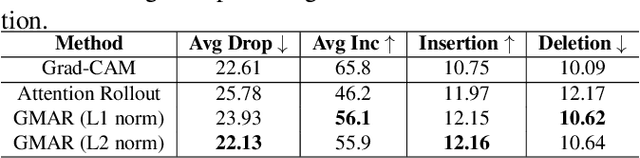
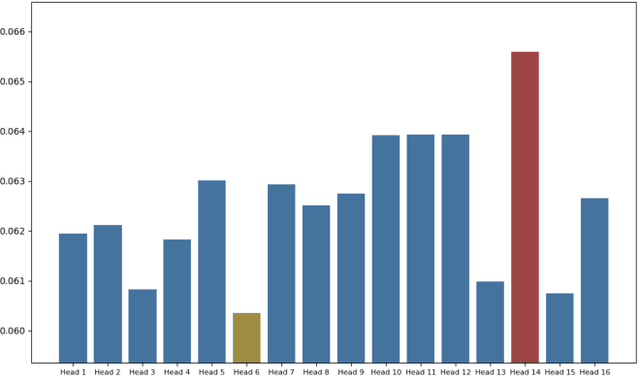
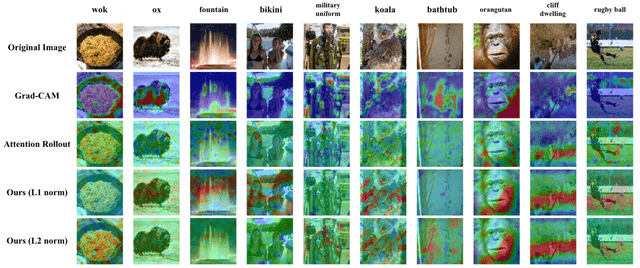
The Vision Transformer (ViT) has made significant advancements in computer vision, utilizing self-attention mechanisms to achieve state-of-the-art performance across various tasks, including image classification, object detection, and segmentation. Its architectural flexibility and capabilities have made it a preferred choice among researchers and practitioners. However, the intricate multi-head attention mechanism of ViT presents significant challenges to interpretability, as the underlying prediction process remains opaque. A critical limitation arises from an observation commonly noted in transformer architectures: "Not all attention heads are equally meaningful." Overlooking the relative importance of specific heads highlights the limitations of existing interpretability methods. To address these challenges, we introduce Gradient-Driven Multi-Head Attention Rollout (GMAR), a novel method that quantifies the importance of each attention head using gradient-based scores. These scores are normalized to derive a weighted aggregate attention score, effectively capturing the relative contributions of individual heads. GMAR clarifies the role of each head in the prediction process, enabling more precise interpretability at the head level. Experimental results demonstrate that GMAR consistently outperforms traditional attention rollout techniques. This work provides a practical contribution to transformer-based architectures, establishing a robust framework for enhancing the interpretability of Vision Transformer models.
V-NAW: Video-based Noise-aware Adaptive Weighting for Facial Expression Recognition
Mar 20, 2025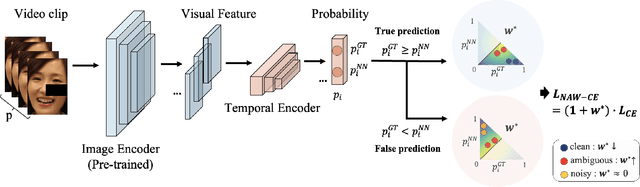


Facial Expression Recognition (FER) plays a crucial role in human affective analysis and has been widely applied in computer vision tasks such as human-computer interaction and psychological assessment. The 8th Affective Behavior Analysis in-the-Wild (ABAW) Challenge aims to assess human emotions using the video-based Aff-Wild2 dataset. This challenge includes various tasks, including the video-based EXPR recognition track, which is our primary focus. In this paper, we demonstrate that addressing label ambiguity and class imbalance, which are known to cause performance degradation, can lead to meaningful performance improvements. Specifically, we propose Video-based Noise-aware Adaptive Weighting (V-NAW), which adaptively assigns importance to each frame in a clip to address label ambiguity and effectively capture temporal variations in facial expressions. Furthermore, we introduce a simple and effective augmentation strategy to reduce redundancy between consecutive frames, which is a primary cause of overfitting. Through extensive experiments, we validate the effectiveness of our approach, demonstrating significant improvements in video-based FER performance.
MAIR++: Improving Multi-view Attention Inverse Rendering with Implicit Lighting Representation
Aug 13, 2024
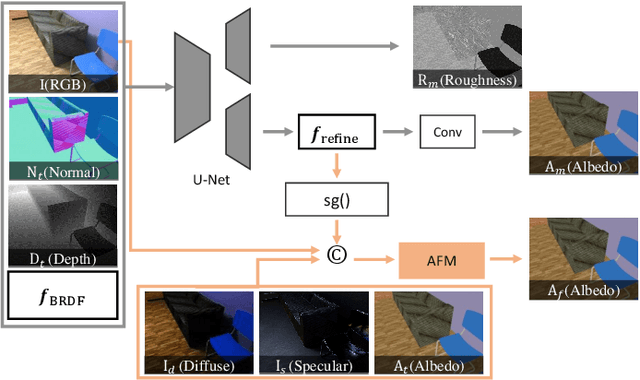


In this paper, we propose a scene-level inverse rendering framework that uses multi-view images to decompose the scene into geometry, SVBRDF, and 3D spatially-varying lighting. While multi-view images have been widely used for object-level inverse rendering, scene-level inverse rendering has primarily been studied using single-view images due to the lack of a dataset containing high dynamic range multi-view images with ground-truth geometry, material, and spatially-varying lighting. To improve the quality of scene-level inverse rendering, a novel framework called Multi-view Attention Inverse Rendering (MAIR) was recently introduced. MAIR performs scene-level multi-view inverse rendering by expanding the OpenRooms dataset, designing efficient pipelines to handle multi-view images, and splitting spatially-varying lighting. Although MAIR showed impressive results, its lighting representation is fixed to spherical Gaussians, which limits its ability to render images realistically. Consequently, MAIR cannot be directly used in applications such as material editing. Moreover, its multi-view aggregation networks have difficulties extracting rich features because they only focus on the mean and variance between multi-view features. In this paper, we propose its extended version, called MAIR++. MAIR++ addresses the aforementioned limitations by introducing an implicit lighting representation that accurately captures the lighting conditions of an image while facilitating realistic rendering. Furthermore, we design a directional attention-based multi-view aggregation network to infer more intricate relationships between views. Experimental results show that MAIR++ not only achieves better performance than MAIR and single-view-based methods, but also displays robust performance on unseen real-world scenes.
IG-FIQA: Improving Face Image Quality Assessment through Intra-class Variance Guidance robust to Inaccurate Pseudo-Labels
Mar 13, 2024In the realm of face image quality assesment (FIQA), method based on sample relative classification have shown impressive performance. However, the quality scores used as pseudo-labels assigned from images of classes with low intra-class variance could be unrelated to the actual quality in this method. To address this issue, we present IG-FIQA, a novel approach to guide FIQA training, introducing a weight parameter to alleviate the adverse impact of these classes. This method involves estimating sample intra-class variance at each iteration during training, ensuring minimal computational overhead and straightforward implementation. Furthermore, this paper proposes an on-the-fly data augmentation methodology for improved generalization performance in FIQA. On various benchmark datasets, our proposed method, IG-FIQA, achieved novel state-of-the-art (SOTA) performance.
MAIR: Multi-view Attention Inverse Rendering with 3D Spatially-Varying Lighting Estimation
Mar 27, 2023



We propose a scene-level inverse rendering framework that uses multi-view images to decompose the scene into geometry, a SVBRDF, and 3D spatially-varying lighting. Because multi-view images provide a variety of information about the scene, multi-view images in object-level inverse rendering have been taken for granted. However, owing to the absence of multi-view HDR synthetic dataset, scene-level inverse rendering has mainly been studied using single-view image. We were able to successfully perform scene-level inverse rendering using multi-view images by expanding OpenRooms dataset and designing efficient pipelines to handle multi-view images, and splitting spatially-varying lighting. Our experiments show that the proposed method not only achieves better performance than single-view-based methods, but also achieves robust performance on unseen real-world scene. Also, our sophisticated 3D spatially-varying lighting volume allows for photorealistic object insertion in any 3D location.
Joint Blind Motion Deblurring and Depth Estimation of Light Field
Jun 14, 2018
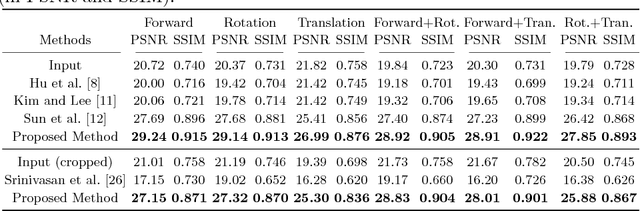
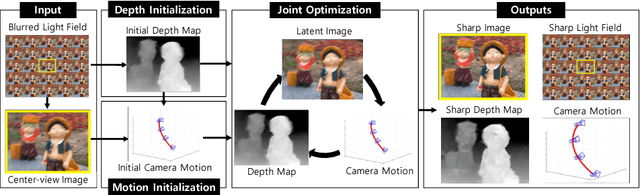
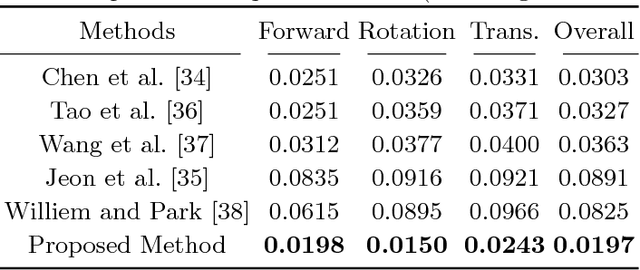
Removing camera motion blur from a single light field is a challenging task since it is highly ill-posed inverse problem. The problem becomes even worse when blur kernel varies spatially due to scene depth variation and high-order camera motion. In this paper, we propose a novel algorithm to estimate all blur model variables jointly, including latent sub-aperture image, camera motion, and scene depth from the blurred 4D light field. Exploiting multi-view nature of a light field relieves the inverse property of the optimization by utilizing strong depth cues and multi-view blur observation. The proposed joint estimation achieves high quality light field deblurring and depth estimation simultaneously under arbitrary 6-DOF camera motion and unconstrained scene depth. Intensive experiment on real and synthetic blurred light field confirms that the proposed algorithm outperforms the state-of-the-art light field deblurring and depth estimation methods.
Look Wider to Match Image Patches with Convolutional Neural Networks
Sep 19, 2017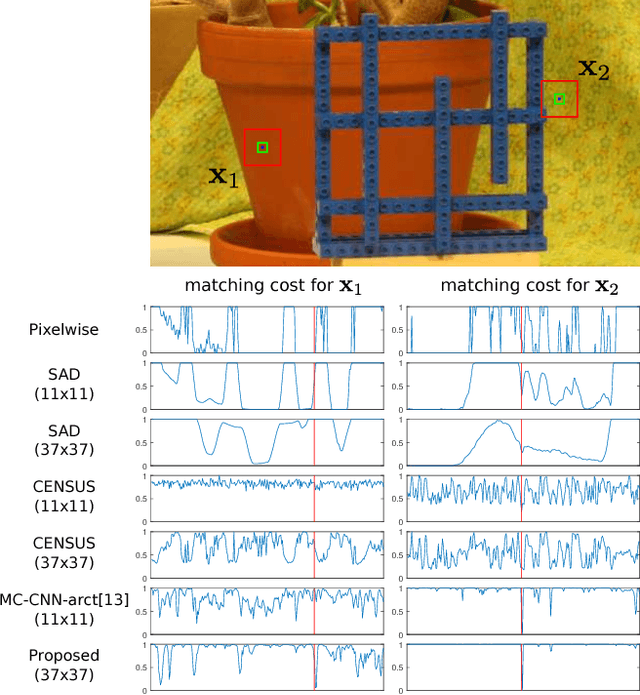

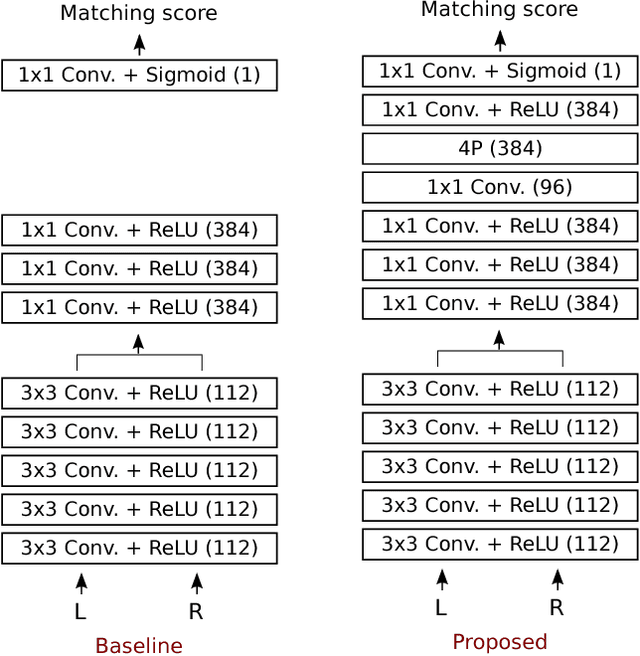
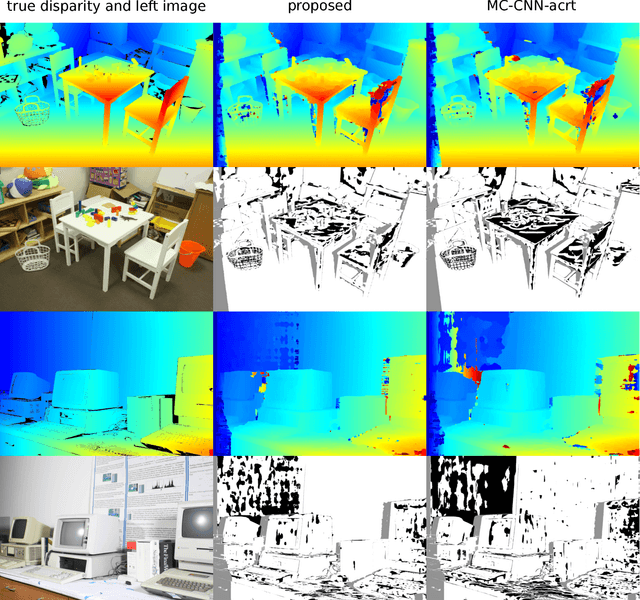
When a human matches two images, the viewer has a natural tendency to view the wide area around the target pixel to obtain clues of right correspondence. However, designing a matching cost function that works on a large window in the same way is difficult. The cost function is typically not intelligent enough to discard the information irrelevant to the target pixel, resulting in undesirable artifacts. In this paper, we propose a novel learn a stereo matching cost with a large-sized window. Unlike conventional pooling layers with strides, the proposed per-pixel pyramid-pooling layer can cover a large area without a loss of resolution and detail. Therefore, the learned matching cost function can successfully utilize the information from a large area without introducing the fattening effect. The proposed method is robust despite the presence of weak textures, depth discontinuity, illumination, and exposure difference. The proposed method achieves near-peak performance on the Middlebury benchmark.
* published in SPL
Joint Estimation of Camera Pose, Depth, Deblurring, and Super-Resolution from a Blurred Image Sequence
Sep 18, 2017
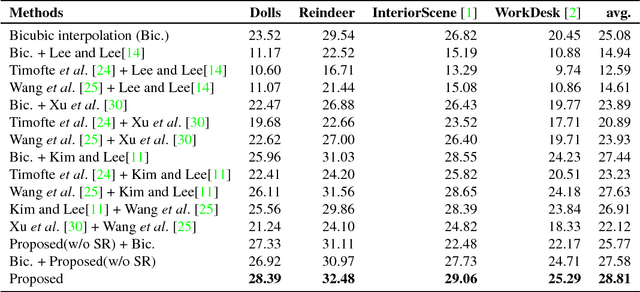
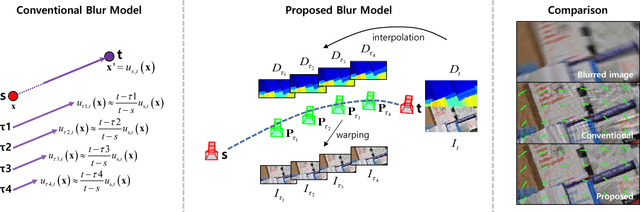
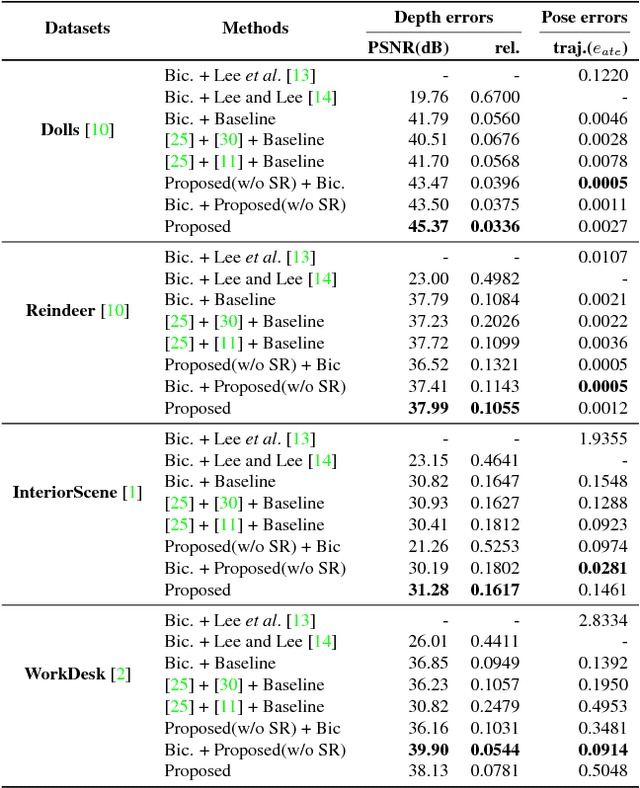
The conventional methods for estimating camera poses and scene structures from severely blurry or low resolution images often result in failure. The off-the-shelf deblurring or super-resolution methods may show visually pleasing results. However, applying each technique independently before matching is generally unprofitable because this naive series of procedures ignores the consistency between images. In this paper, we propose a pioneering unified framework that solves four problems simultaneously, namely, dense depth reconstruction, camera pose estimation, super-resolution, and deblurring. By reflecting a physical imaging process, we formulate a cost minimization problem and solve it using an alternating optimization technique. The experimental results on both synthetic and real videos show high-quality depth maps derived from severely degraded images that contrast the failures of naive multi-view stereo methods. Our proposed method also produces outstanding deblurred and super-resolved images unlike the independent application or combination of conventional video deblurring, super-resolution methods.