 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAIR++: Improving Multi-view Attention Inverse Rendering with Implicit Lighting Representation
Paper and Code
Aug 13, 2024
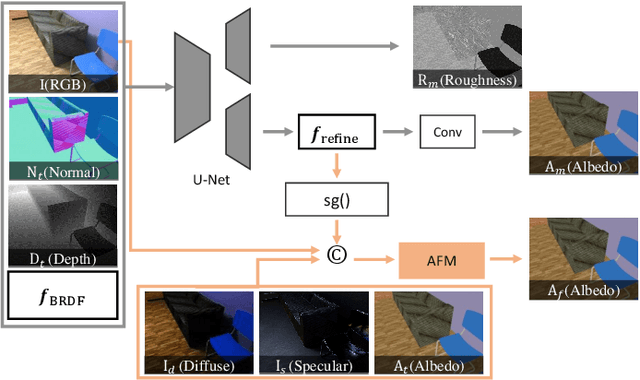


In this paper, we propose a scene-level inverse rendering framework that uses multi-view images to decompose the scene into geometry, SVBRDF, and 3D spatially-varying lighting. While multi-view images have been widely used for object-level inverse rendering, scene-level inverse rendering has primarily been studied using single-view images due to the lack of a dataset containing high dynamic range multi-view images with ground-truth geometry, material, and spatially-varying lighting. To improve the quality of scene-level inverse rendering, a novel framework called Multi-view Attention Inverse Rendering (MAIR) was recently introduced. MAIR performs scene-level multi-view inverse rendering by expanding the OpenRooms dataset, designing efficient pipelines to handle multi-view images, and splitting spatially-varying lighting. Although MAIR showed impressive results, its lighting representation is fixed to spherical Gaussians, which limits its ability to render images realistically. Consequently, MAIR cannot be directly used in applications such as material editing. Moreover, its multi-view aggregation networks have difficulties extracting rich features because they only focus on the mean and variance between multi-view features. In this paper, we propose its extended version, called MAIR++. MAIR++ addresses the aforementioned limitations by introducing an implicit lighting representation that accurately captures the lighting conditions of an image while facilitating realistic rendering. Furthermore, we design a directional attention-based multi-view aggregation network to infer more intricate relationships between views. Experimental results show that MAIR++ not only achieves better performance than MAIR and single-view-based methods, but also displays robust performance on unseen real-world scenes.