 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLink to the Past: Temporal Propagation for Fast 3D Human Reconstruction from Monocular Video
May 12, 2025Fast 3D clothed human reconstruction from monocular video remains a significant challenge in computer vision, particularly in balancing computational efficiency with reconstruction quality. Current approaches are either focused on static image reconstruction but too computationally intensive, or achieve high quality through per-video optimization that requires minutes to hours of processing, making them unsuitable for real-time applications. To this end, we present TemPoFast3D, a novel method that leverages temporal coherency of human appearance to reduce redundant computation while maintaining reconstruction quality. Our approach is a "plug-and play" solution that uniquely transforms pixel-aligned reconstruction networks to handle continuous video streams by maintaining and refining a canonical appearance representation through efficient coordinate mapping. Extensive experiments demonstrate that TemPoFast3D matches or exceeds state-of-the-art methods across standard metrics while providing high-quality textured reconstruction across diverse pose and appearance, with a maximum speed of 12 FPS.
IFQA: Interpretable Face Quality Assessment
Nov 17, 2022



Existing face restoration models have relied on general assessment metrics that do not consider the characteristics of facial regions. Recent works have therefore assessed their methods using human studies, which is not scalable and involves significant effort. This paper proposes a novel face-centric metric based on an adversarial framework where a generator simulates face restoration and a discriminator assesses image quality. Specifically, our per-pixel discriminator enables interpretable evaluation that cannot be provided by traditional metrics. Moreover, our metric emphasizes facial primary regions considering that even minor changes to the eyes, nose, and mouth significantly affect human cognition. Our face-oriented metric consistently surpasses existing general or facial image quality assessment metrics by impressive margins. We demonstrate the generalizability of the proposed strategy in various architectural designs and challenging scenarios. Interestingly, we find that our IFQA can lead to performance improvement as an objective function.
Human and Scene Motion Deblurring using Pseudo-blur Synthesizer
Nov 25, 2021
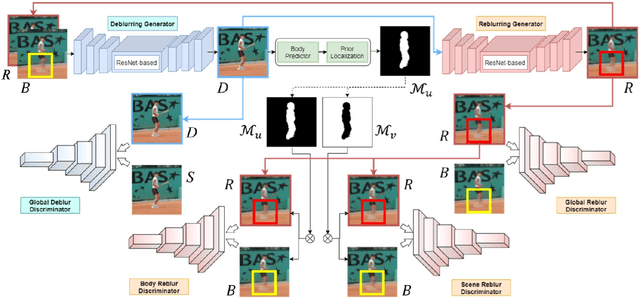

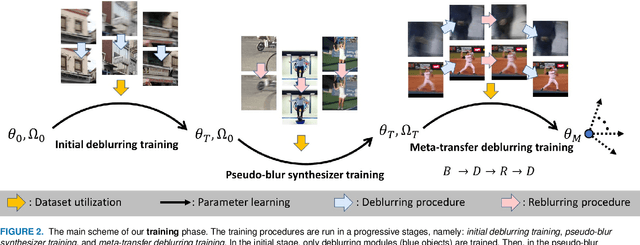
Present-day deep learning-based motion deblurring methods utilize the pair of synthetic blur and sharp data to regress any particular framework. This task is designed for directly translating a blurry image input into its restored version as output. The aforementioned approach relies heavily on the quality of the synthetic blurry data, which are only available before the training stage. Handling this issue by providing a large amount of data is expensive for common usage. We answer this challenge by providing an on-the-fly blurry data augmenter that can be run during training and test stages. To fully utilize it, we incorporate an unorthodox scheme of deblurring framework that employs the sequence of blur-deblur-reblur-deblur steps. The reblur step is assisted by a reblurring module (synthesizer) that provides the reblurred version (pseudo-blur) of its sharp or deblurred counterpart. The proposed module is also equipped with hand-crafted prior extracted using the state-of-the-art human body statistical model. This prior is employed to map human and non-human regions during adversarial learning to fully perceive the characteristics of human-articulated and scene motion blurs. By engaging this approach, our deblurring module becomes adaptive and achieves superior outcomes compared to recent state-of-the-art deblurring algorithms.
5D Light Field Synthesis from a Monocular Video
Dec 23, 2019


Commercially available light field cameras have difficulty in capturing 5D (4D + time) light field videos. They can only capture still light filed images or are excessively expensive for normal users to capture the light field video. To tackle this problem, we propose a deep learning-based method for synthesizing a light field video from a monocular video. We propose a new synthetic light field video dataset that renders photorealistic scenes using UnrealCV rendering engine because no light field dataset is available. The proposed deep learning framework synthesizes the light field video with a full set (9$\times$9) of sub-aperture images from a normal monocular video. The proposed network consists of three sub-networks, namely, feature extraction, 5D light field video synthesis, and temporal consistency refinement. Experimental results show that our model can successfully synthesize the light field video for synthetic and actual scenes and outperforms the previous frame-by-frame methods quantitatively and qualitatively. The synthesized light field can be used for conventional light field applications, namely, depth estimation, viewpoint change, and refocusing.
Joint Face Super-Resolution and Deblurring Using a Generative Adversarial Network
Dec 22, 2019

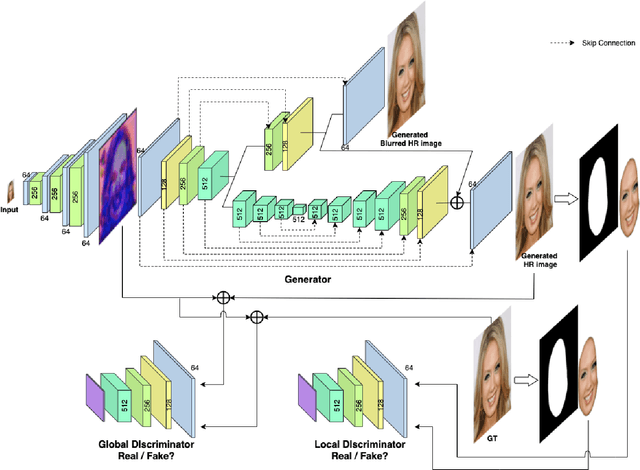

Facial image super-resolution (SR) is an important preprocessing for facial image analysis, face recognition, and image-based 3D face reconstruction. Recent convolutional neural network (CNN) based method has shown excellent performance by learning mapping relation using pairs of low-resolution (LR) and high-resolution (HR) facial images. However, since the HR facial image reconstruction using CNN is conventionally aimed to increase the PSNR and SSIM metrics, the reconstructed HR image might not be realistic even with high scores. An adversarial framework is proposed in this study to reconstruct the HR facial image by simultaneously generating an HR image with and without blur. First, the spatial resolution of the LR facial image is increased by eight times using a five-layer CNN. Then, the encoder extracts the features of the up-scaled image. These features are finally sent to two branches (decoders) to generate an HR facial image with and without blur. In addition, local and global discriminators are combined to focus on the reconstruction of HR facial structures. Experiment results show that the proposed algorithm generates a realistic HR facial image. Furthermore, the proposed method can generate a variety of different facial images.
Joint Spatial and Angular Super-Resolution from a Single Image
Nov 29, 2019
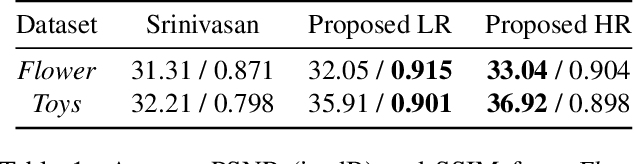

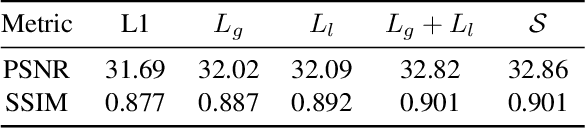
Synthesizing a densely sampled light field from a single image is highly beneficial for many applications. Moreover, jointly solving both angular and spatial super-resolution problem also introduces new possibilities in light field imaging. The conventional method relies on physical-based rendering and a secondary network to solve the angular super-resolution problem. In addition, pixel-based loss limits the network capability to infer scene geometry globally. In this paper, we show that both super-resolution problems can be solved jointly from a single image by proposing a single end-to-end deep neural network that does not require a physical-based approach. Two novel loss functions based on known light field domain knowledge are proposed to enable the network to preserve the spatio-angular consistency between sub-aperture images. Experimental results show that the proposed model successfully synthesizes dense high resolution light field and it outperforms the state-of-the-art method in both quantitative and qualitative criteria. The method can be generalized to arbitrary scenes, rather than focusing on a particular subject. The synthesized light field can be used for various applications, such as depth estimation and refocusing.
Face De-occlusion using 3D Morphable Model and Generative Adversarial Network
Apr 12, 2019
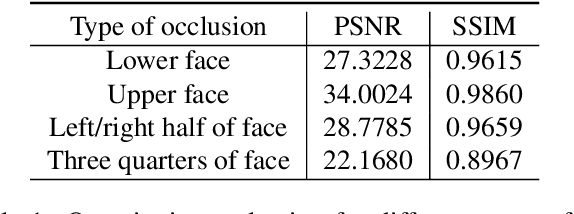
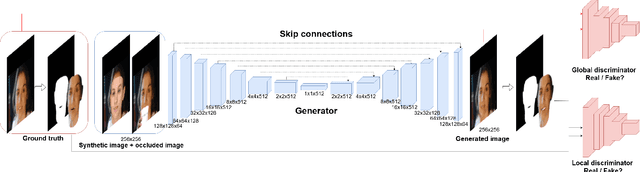

In recent decades, 3D morphable model (3DMM) has been commonly used in image-based photorealistic 3D face reconstruction. However, face images are often corrupted by serious occlusion by non-face objects including eyeglasses, masks, and hands. Such objects block the correct capture of landmarks and shading information. Therefore, the reconstructed 3D face model is hardly reusable. In this paper, a novel method is proposed to restore de-occluded face images based on inverse use of 3DMM and generative adversarial network. We utilize the 3DMM prior to the proposed adversarial network and combine a global and local adversarial convolutional neural network to learn face de-occlusion model. The 3DMM serves not only as geometric prior but also proposes the face region for the local discriminator. Experiment results confirm the effectiveness and robustness of the proposed algorithm in removing challenging types of occlusions with various head poses and illumination. Furthermore, the proposed method reconstructs the correct 3D face model with de-occluded textures.
360 Panorama Synthesis from a Sparse Set of Images with Unknown FOV
Apr 06, 2019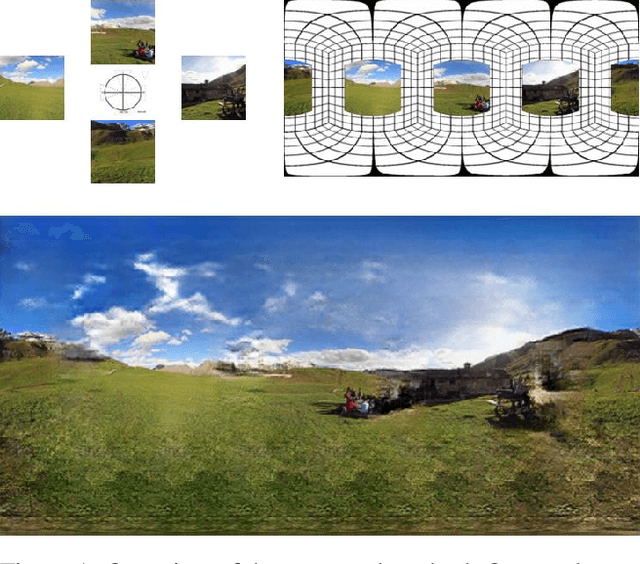
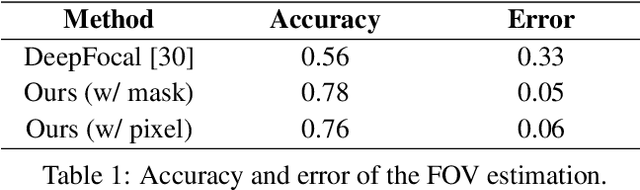
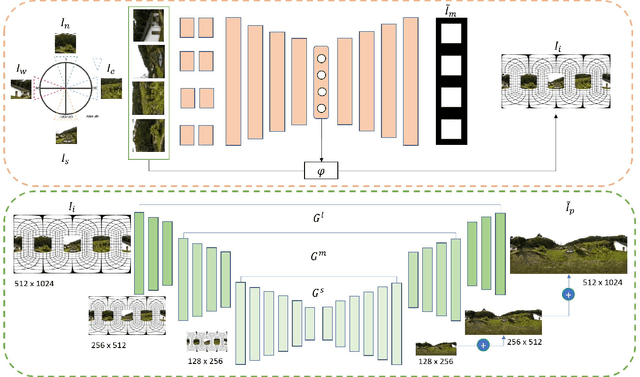
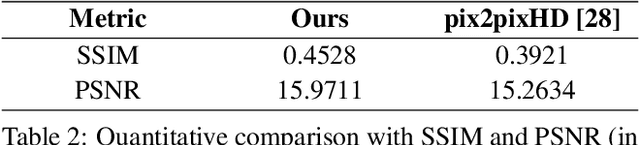
360 images represent scenes captured in all possible viewing directions. They enable viewers to navigate freely around the scene and thus provide an immersive experience. Conversely, conventional images represent scenes in a single viewing direction. These images are captured with a small or limited field of view. As a result, only some parts of the scenes are observed, and valuable information about the surroundings is lost. We propose a learning-based approach that reconstructs the scene in 360 x180 from conventional images. This approach first estimates the field of view of input images relative to the panorama. The estimated field of view is then used as the prior for synthesizing a high-resolution 360 panoramic output. Experimental results demonstrate that our approach outperforms alternative method and is robust enough to synthesize real-world data (e.g. scenes captured using smartphones).
Fast and Full-Resolution Light Field Deblurring using a Deep Neural Network
Mar 31, 2019
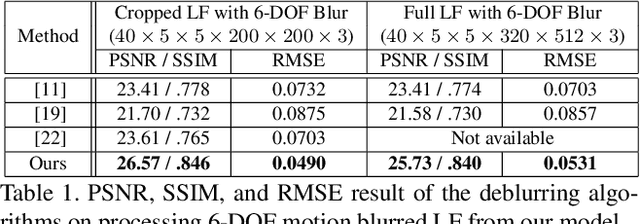
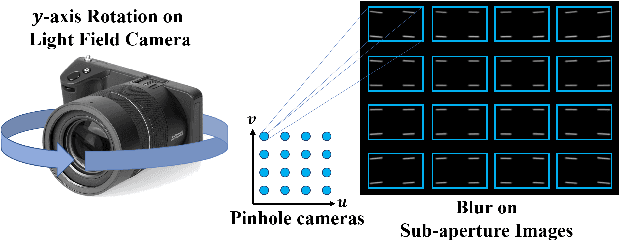
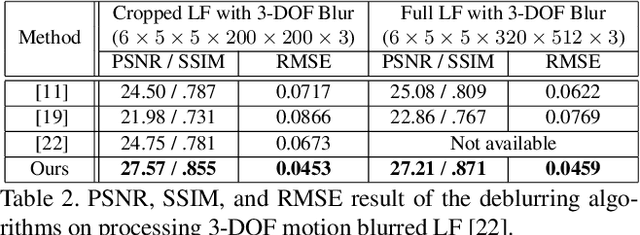
Restoring a sharp light field image from its blurry input has become essential due to the increasing popularity of parallax-based image processing. State-of-the-art blind light field deblurring methods suffer from several issues such as slow processing, reduced spatial size, and a limited motion blur model. In this work, we address these challenging problems by generating a complex blurry light field dataset and proposing a learning-based deblurring approach. In particular, we model the full 6-degree of freedom (6-DOF) light field camera motion, which is used to create the blurry dataset using a combination of real light fields captured with a Lytro Illum camera, and synthetic light field renderings of 3D scenes. Furthermore, we propose a light field deblurring network that is built with the capability of large receptive fields. We also introduce a simple strategy of angular sampling to train on the large-scale blurry light field effectively. We evaluate our method through both quantitative and qualitative measurements and demonstrate superior performance compared to the state-of-the-art method with a massive speedup in execution time. Our method is about 16K times faster than Srinivasan et. al. [22] and can deblur a full-resolution light field in less than 2 seconds.
Synthesizing a 4D Spatio-Angular Consistent Light Field from a Single Image
Mar 29, 2019
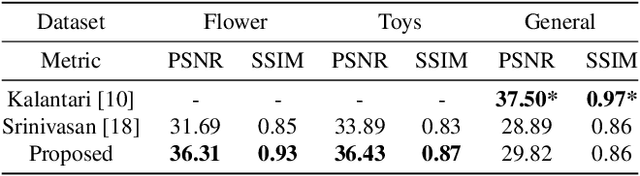
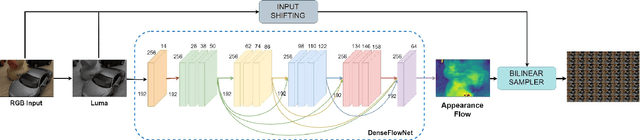
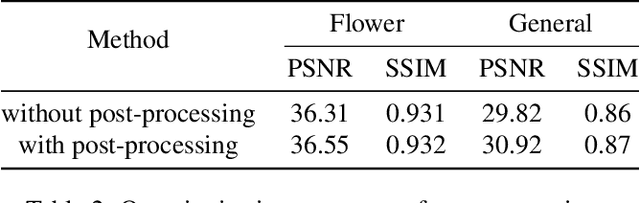
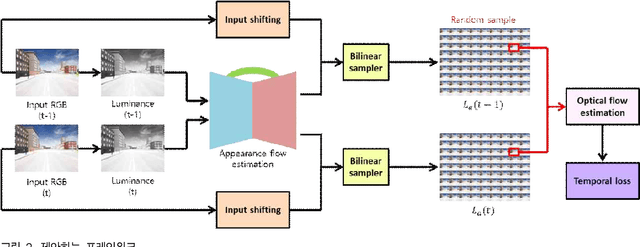
Synthesizing a densely sampled light field from a single image is highly beneficial for many applications. The conventional method reconstructs a depth map and relies on physical-based rendering and a secondary network to improve the synthesized novel views. Simple pixel-based loss also limits the network by making it rely on pixel intensity cue rather than geometric reasoning. In this study, we show that a different geometric representation, namely, appearance flow, can be used to synthesize a light field from a single image robustly and directly. A single end-to-end deep neural network that does not require a physical-based approach nor a post-processing subnetwork is proposed. Two novel loss functions based on known light field domain knowledge are presented to enable the network to preserve the spatio-angular consistency between sub-aperture images effectively. Experimental results show that the proposed model successfully synthesizes dense light fields and qualitatively and quantitatively outperforms the previous model . The method can be generalized to arbitrary scenes, rather than focusing on a particular class of object. The synthesized light field can be used for various applications, such as depth estimation and refocusing.