 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEf-QuantFace: Streamlined Face Recognition with Small Data and Low-Bit Precision
Feb 28, 2024In recent years, model quantization for face recognition has gained prominence. Traditionally, compressing models involved vast datasets like the 5.8 million-image MS1M dataset as well as extensive training times, raising the question of whether such data enormity is essential. This paper addresses this by introducing an efficiency-driven approach, fine-tuning the model with just up to 14,000 images, 440 times smaller than MS1M. We demonstrate that effective quantization is achievable with a smaller dataset, presenting a new paradigm. Moreover, we incorporate an evaluation-based metric loss and achieve an outstanding 96.15% accuracy on the IJB-C dataset, establishing a new state-of-the-art compressed model training for face recognition. The subsequent analysis delves into potential applications, emphasizing the transformative power of this approach. This paper advances model quantization by highlighting the efficiency and optimal results with small data and training time.
Joint Spatial and Angular Super-Resolution from a Single Image
Nov 29, 2019
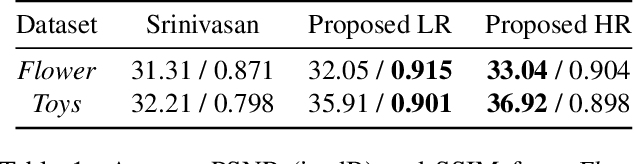

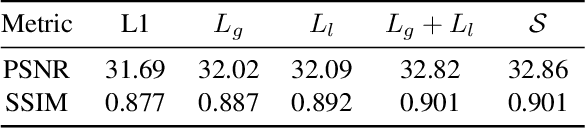
Synthesizing a densely sampled light field from a single image is highly beneficial for many applications. Moreover, jointly solving both angular and spatial super-resolution problem also introduces new possibilities in light field imaging. The conventional method relies on physical-based rendering and a secondary network to solve the angular super-resolution problem. In addition, pixel-based loss limits the network capability to infer scene geometry globally. In this paper, we show that both super-resolution problems can be solved jointly from a single image by proposing a single end-to-end deep neural network that does not require a physical-based approach. Two novel loss functions based on known light field domain knowledge are proposed to enable the network to preserve the spatio-angular consistency between sub-aperture images. Experimental results show that the proposed model successfully synthesizes dense high resolution light field and it outperforms the state-of-the-art method in both quantitative and qualitative criteria. The method can be generalized to arbitrary scenes, rather than focusing on a particular subject. The synthesized light field can be used for various applications, such as depth estimation and refocusing.
Synthesizing a 4D Spatio-Angular Consistent Light Field from a Single Image
Mar 29, 2019
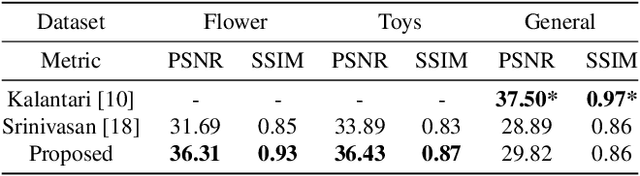
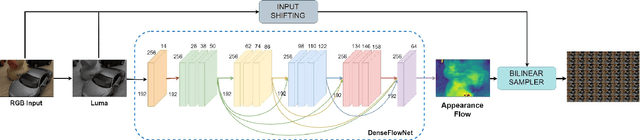
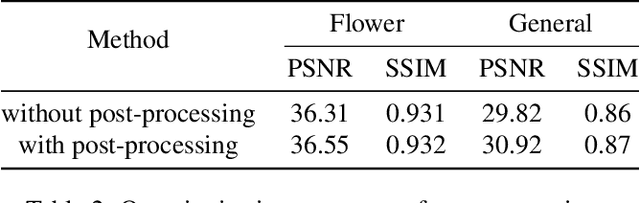
Synthesizing a densely sampled light field from a single image is highly beneficial for many applications. The conventional method reconstructs a depth map and relies on physical-based rendering and a secondary network to improve the synthesized novel views. Simple pixel-based loss also limits the network by making it rely on pixel intensity cue rather than geometric reasoning. In this study, we show that a different geometric representation, namely, appearance flow, can be used to synthesize a light field from a single image robustly and directly. A single end-to-end deep neural network that does not require a physical-based approach nor a post-processing subnetwork is proposed. Two novel loss functions based on known light field domain knowledge are presented to enable the network to preserve the spatio-angular consistency between sub-aperture images effectively. Experimental results show that the proposed model successfully synthesizes dense light fields and qualitatively and quantitatively outperforms the previous model . The method can be generalized to arbitrary scenes, rather than focusing on a particular class of object. The synthesized light field can be used for various applications, such as depth estimation and refocusing.