 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHYPNOS : Highly Precise Foreground-focused Diffusion Finetuning for Inanimate Objects
Oct 18, 2024In recent years, personalized diffusion-based text-to-image generative tasks have been a hot topic in computer vision studies. A robust diffusion model is determined by its ability to perform near-perfect reconstruction of certain product outcomes given few related input samples. Unfortunately, the current prominent diffusion-based finetuning technique falls short in maintaining the foreground object consistency while being constrained to produce diverse backgrounds in the image outcome. In the worst scenario, the overfitting issue may occur, meaning that the foreground object is less controllable due to the condition above, for example, the input prompt information is transferred ambiguously to both foreground and background regions, instead of the supposed background region only. To tackle the issues above, we proposed Hypnos, a highly precise foreground-focused diffusion finetuning technique. On the image level, this strategy works best for inanimate object generation tasks, and to do so, Hypnos implements two main approaches, namely: (i) a content-centric prompting strategy and (ii) the utilization of our additional foreground-focused discriminative module. The utilized module is connected with the diffusion model and finetuned with our proposed set of supervision mechanism. Combining the strategies above yielded to the foreground-background disentanglement capability of the diffusion model. Our experimental results showed that the proposed strategy gave a more robust performance and visually pleasing results compared to the former technique. For better elaborations, we also provided extensive studies to assess the fruitful outcomes above, which reveal how personalization behaves in regard to several training conditions.
3DHR-Co: A Collaborative Test-time Refinement Framework for In-the-Wild 3D Human-Body Reconstruction Task
Oct 02, 2023
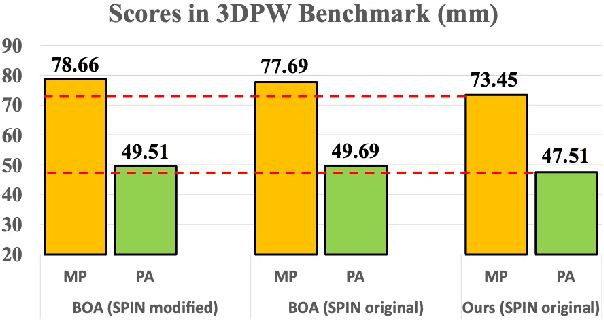

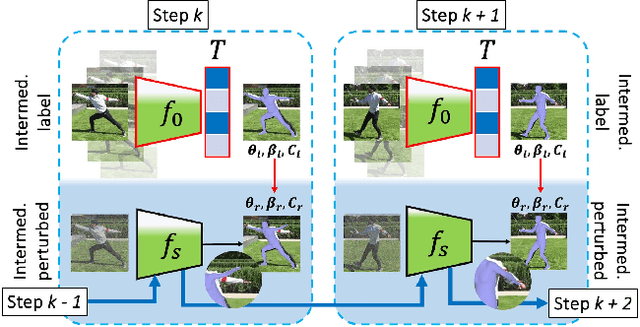
The field of 3D human-body reconstruction (abbreviated as 3DHR) that utilizes parametric pose and shape representations has witnessed significant advancements in recent years. However, the application of 3DHR techniques to handle real-world, diverse scenes, known as in-the-wild data, still faces limitations. The primary challenge arises as curating accurate 3D human pose ground truth (GT) for in-the-wild scenes is still difficult to obtain due to various factors. Recent test-time refinement approaches on 3DHR leverage initial 2D off-the-shelf human keypoints information to support the lack of 3D supervision on in-the-wild data. However, we observed that additional 2D supervision alone could cause the overfitting issue on common 3DHR backbones, making the 3DHR test-time refinement task seem intractable. We answer this challenge by proposing a strategy that complements 3DHR test-time refinement work under a collaborative approach. Specifically, we initially apply a pre-adaptation approach that works by collaborating various 3DHR models in a single framework to directly improve their initial outputs. This approach is then further combined with the test-time adaptation work under specific settings that minimize the overfitting issue to further boost the 3DHR performance. The whole framework is termed as 3DHR-Co, and on the experiment sides, we showed that the proposed work can significantly enhance the scores of common classic 3DHR backbones up to -34 mm pose error suppression, putting them among the top list on the in-the-wild benchmark data. Such achievement shows that our approach helps unveil the true potential of the common classic 3DHR backbones. Based on these findings, we further investigate various settings on the proposed framework to better elaborate the capability of our collaborative approach in the 3DHR task.
Human and Scene Motion Deblurring using Pseudo-blur Synthesizer
Nov 25, 2021
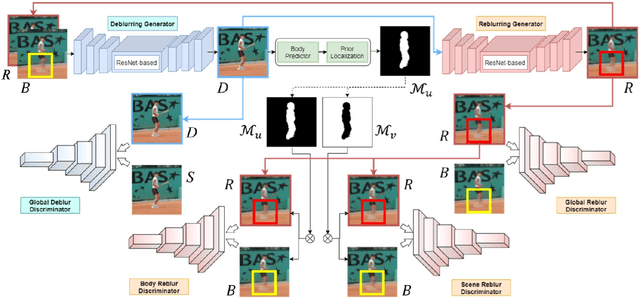

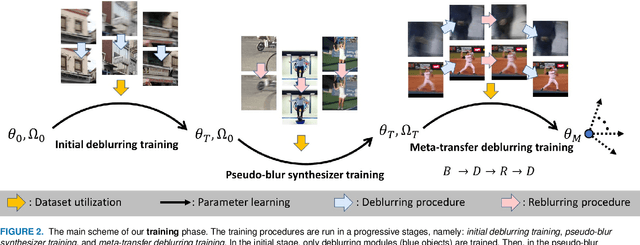
Present-day deep learning-based motion deblurring methods utilize the pair of synthetic blur and sharp data to regress any particular framework. This task is designed for directly translating a blurry image input into its restored version as output. The aforementioned approach relies heavily on the quality of the synthetic blurry data, which are only available before the training stage. Handling this issue by providing a large amount of data is expensive for common usage. We answer this challenge by providing an on-the-fly blurry data augmenter that can be run during training and test stages. To fully utilize it, we incorporate an unorthodox scheme of deblurring framework that employs the sequence of blur-deblur-reblur-deblur steps. The reblur step is assisted by a reblurring module (synthesizer) that provides the reblurred version (pseudo-blur) of its sharp or deblurred counterpart. The proposed module is also equipped with hand-crafted prior extracted using the state-of-the-art human body statistical model. This prior is employed to map human and non-human regions during adversarial learning to fully perceive the characteristics of human-articulated and scene motion blurs. By engaging this approach, our deblurring module becomes adaptive and achieves superior outcomes compared to recent state-of-the-art deblurring algorithms.
Fast and Full-Resolution Light Field Deblurring using a Deep Neural Network
Mar 31, 2019
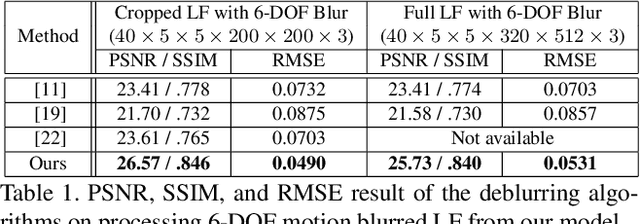
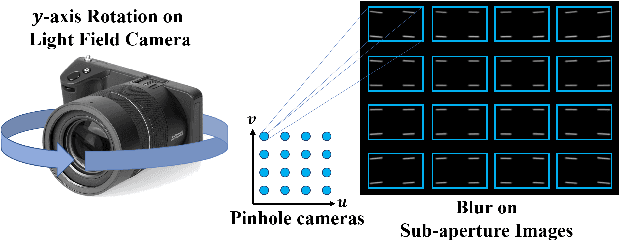
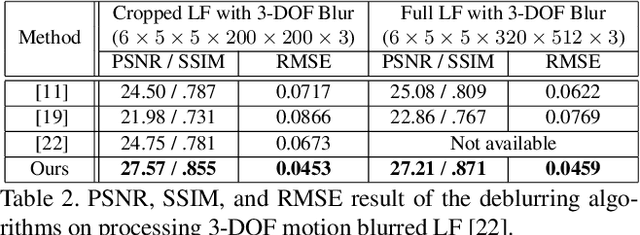
Restoring a sharp light field image from its blurry input has become essential due to the increasing popularity of parallax-based image processing. State-of-the-art blind light field deblurring methods suffer from several issues such as slow processing, reduced spatial size, and a limited motion blur model. In this work, we address these challenging problems by generating a complex blurry light field dataset and proposing a learning-based deblurring approach. In particular, we model the full 6-degree of freedom (6-DOF) light field camera motion, which is used to create the blurry dataset using a combination of real light fields captured with a Lytro Illum camera, and synthetic light field renderings of 3D scenes. Furthermore, we propose a light field deblurring network that is built with the capability of large receptive fields. We also introduce a simple strategy of angular sampling to train on the large-scale blurry light field effectively. We evaluate our method through both quantitative and qualitative measurements and demonstrate superior performance compared to the state-of-the-art method with a massive speedup in execution time. Our method is about 16K times faster than Srinivasan et. al. [22] and can deblur a full-resolution light field in less than 2 seconds.