 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCMNet: Uncertainty-Aware Context Memory Network for Under-Display Camera Image Restoration
Apr 01, 2026Under-display cameras (UDCs) allow for full-screen designs by positioning the imaging sensor underneath the display. Nonetheless, light diffraction and scattering through the various display layers result in spatially varying and complex degradations, which significantly reduce high-frequency details. Current PSF-based physical modeling techniques and frequency-separation networks are effective at reconstructing low-frequency structures and maintaining overall color consistency. However, they still face challenges in recovering fine details when dealing with complex, spatially varying degradation. To solve this problem, we propose a lightweight \textbf{U}ncertainty-aware \textbf{C}ontext-\textbf{M}emory \textbf{Network} (\textbf{UCMNet}), for UDC image restoration. Unlike previous methods that apply uniform restoration, UCMNet performs uncertainty-aware adaptive processing to restore high-frequency details in regions with varying degradations. The estimated uncertainty maps, learned through an uncertainty-driven loss, quantify spatial uncertainty induced by diffraction and scattering, and guide the Memory Bank to retrieve region-adaptive context from the Context Bank. This process enables effective modeling of the non-uniform degradation characteristics inherent to UDC imaging. Leveraging this uncertainty as a prior, UCMNet achieves state-of-the-art performance on multiple benchmarks with 30\% fewer parameters than previous models. Project page: \href{https://kdhrick2222.github.io/projects/UCMNet/}{https://kdhrick2222.github.io/projects/UCMNet}.
Diffusion-Based sRGB Real Noise Generation via Prompt-Driven Noise Representation Learning
Mar 05, 2026Denoising in the sRGB image space is challenging due to noise variability. Although end-to-end methods perform well, their effectiveness in real-world scenarios is limited by the scarcity of real noisy-clean image pairs, which are expensive and difficult to collect. To address this limitation, several generative methods have been developed to synthesize realistic noisy images from limited data. These generative approaches often rely on camera metadata during both training and testing to synthesize real-world noise. However, the lack of metadata or inconsistencies between devices restricts their usability. Therefore, we propose a novel framework called Prompt-Driven Noise Generation (PNG). This model is capable of acquiring high-dimensional prompt features that capture the characteristics of real-world input noise and creating a variety of realistic noisy images consistent with the distribution of the input noise. By eliminating the dependency on explicit camera metadata, our approach significantly enhances the generalizability and applicability of noise synthesis. Comprehensive experiments reveal that our model effectively produces realistic noisy images and show the successful application of these generated images in removing real-world noise across various benchmark datasets.
Continuous Degradation Modeling via Latent Flow Matching for Real-World Super-Resolution
Feb 04, 2026While deep learning-based super-resolution (SR) methods have shown impressive outcomes with synthetic degradation scenarios such as bicubic downsampling, they frequently struggle to perform well on real-world images that feature complex, nonlinear degradations like noise, blur, and compression artifacts. Recent efforts to address this issue have involved the painstaking compilation of real low-resolution (LR) and high-resolution (HR) image pairs, usually limited to several specific downscaling factors. To address these challenges, our work introduces a novel framework capable of synthesizing authentic LR images from a single HR image by leveraging the latent degradation space with flow matching. Our approach generates LR images with realistic artifacts at unseen degradation levels, which facilitates the creation of large-scale, real-world SR training datasets. Comprehensive quantitative and qualitative assessments verify that our synthetic LR images accurately replicate real-world degradations. Furthermore, both traditional and arbitrary-scale SR models trained using our datasets consistently yield much better HR outcomes.
IDF: Iterative Dynamic Filtering Networks for Generalizable Image Denoising
Aug 27, 2025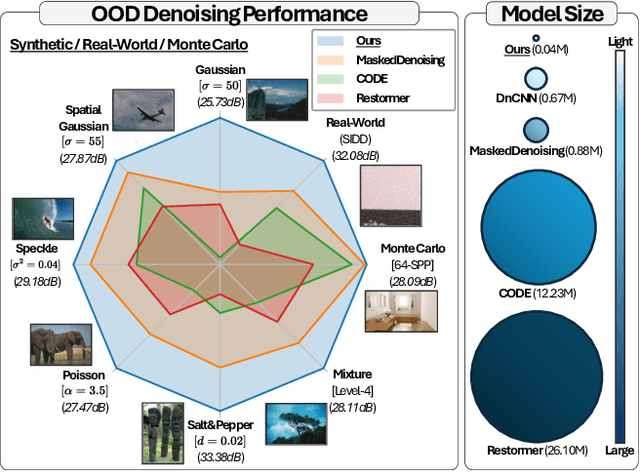
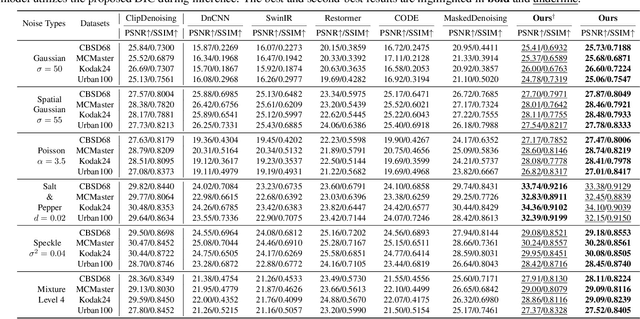

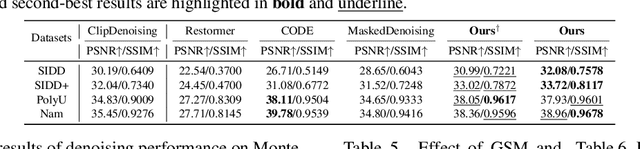
Image denoising is a fundamental challenge in computer vision, with applications in photography and medical imaging. While deep learning-based methods have shown remarkable success, their reliance on specific noise distributions limits generalization to unseen noise types and levels. Existing approaches attempt to address this with extensive training data and high computational resources but they still suffer from overfitting. To address these issues, we conduct image denoising by utilizing dynamically generated kernels via efficient operations. This approach helps prevent overfitting and improves resilience to unseen noise. Specifically, our method leverages a Feature Extraction Module for robust noise-invariant features, Global Statistics and Local Correlation Modules to capture comprehensive noise characteristics and structural correlations. The Kernel Prediction Module then employs these cues to produce pixel-wise varying kernels adapted to local structures, which are then applied iteratively for denoising. This ensures both efficiency and superior restoration quality. Despite being trained on single-level Gaussian noise, our compact model (~ 0.04 M) excels across diverse noise types and levels, demonstrating the promise of iterative dynamic filtering for practical image denoising.
Harnessing Meta-Learning for Controllable Full-Frame Video Stabilization
Aug 26, 2025Video stabilization remains a fundamental problem in computer vision, particularly pixel-level synthesis solutions for video stabilization, which synthesize full-frame outputs, add to the complexity of this task. These methods aim to enhance stability while synthesizing full-frame videos, but the inherent diversity in motion profiles and visual content present in each video sequence makes robust generalization with fixed parameters difficult. To address this, we present a novel method that improves pixel-level synthesis video stabilization methods by rapidly adapting models to each input video at test time. The proposed approach takes advantage of low-level visual cues available during inference to improve both the stability and visual quality of the output. Notably, the proposed rapid adaptation achieves significant performance gains even with a single adaptation pass. We further propose a jerk localization module and a targeted adaptation strategy, which focuses the adaptation on high-jerk segments for maximizing stability with fewer adaptation steps. The proposed methodology enables modern stabilizers to overcome the longstanding SOTA approaches while maintaining the full frame nature of the modern methods, while offering users with control mechanisms akin to classical approaches. Extensive experiments on diverse real-world datasets demonstrate the versatility of the proposed method. Our approach consistently improves the performance of various full-frame synthesis models in both qualitative and quantitative terms, including results on downstream applications.
LAN: Learning to Adapt Noise for Image Denoising
Dec 14, 2024

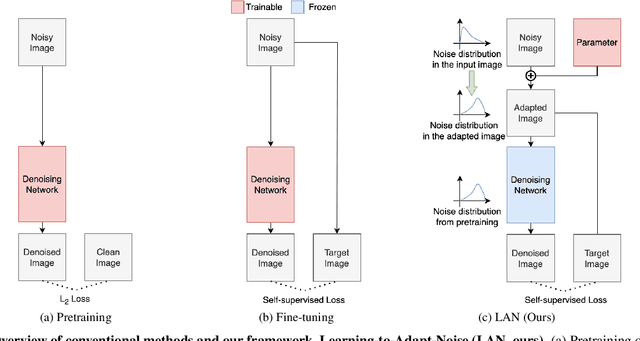

Removing noise from images, a.k.a image denoising, can be a very challenging task since the type and amount of noise can greatly vary for each image due to many factors including a camera model and capturing environments. While there have been striking improvements in image denoising with the emergence of advanced deep learning architectures and real-world datasets, recent denoising networks struggle to maintain performance on images with noise that has not been seen during training. One typical approach to address the challenge would be to adapt a denoising network to new noise distribution. Instead, in this work, we shift our focus to adapting the input noise itself, rather than adapting a network. Thus, we keep a pretrained network frozen, and adapt an input noise to capture the fine-grained deviations. As such, we propose a new denoising algorithm, dubbed Learning-to-Adapt-Noise (LAN), where a learnable noise offset is directly added to a given noisy image to bring a given input noise closer towards the noise distribution a denoising network is trained to handle. Consequently, the proposed framework exhibits performance improvement on images with unseen noise, displaying the potential of the proposed research direction. The code is available at https://github.com/chjinny/LAN
Deep Variational Bayesian Modeling of Haze Degradation Process
Dec 04, 2024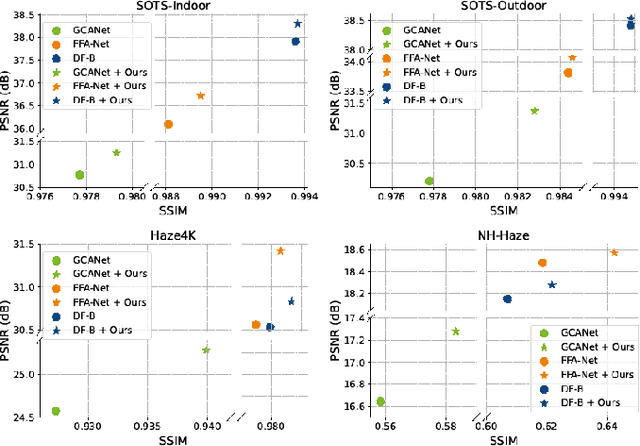
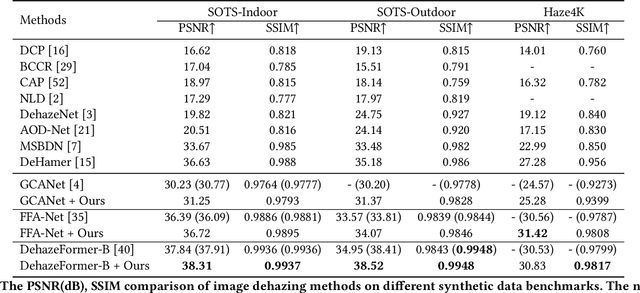
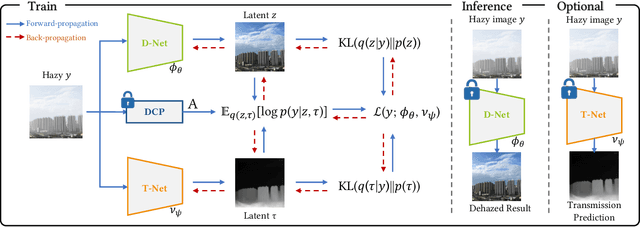
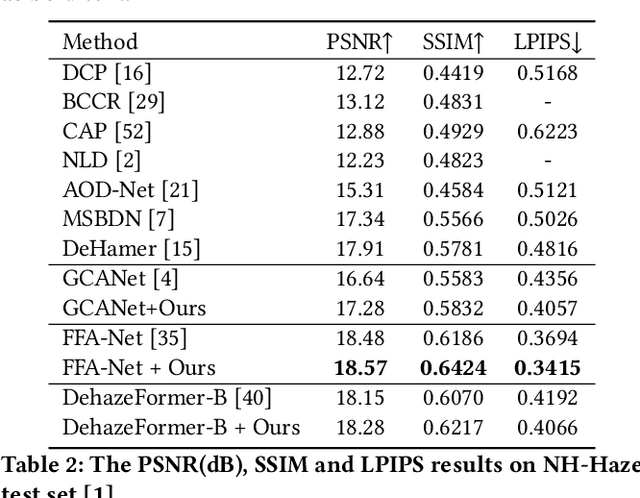
Relying on the representation power of neural networks, most recent works have often neglected several factors involved in haze degradation, such as transmission (the amount of light reaching an observer from a scene over distance) and atmospheric light. These factors are generally unknown, making dehazing problems ill-posed and creating inherent uncertainties. To account for such uncertainties and factors involved in haze degradation, we introduce a variational Bayesian framework for single image dehazing. We propose to take not only a clean image and but also transmission map as latent variables, the posterior distributions of which are parameterized by corresponding neural networks: dehazing and transmission networks, respectively. Based on a physical model for haze degradation, our variational Bayesian framework leads to a new objective function that encourages the cooperation between them, facilitating the joint training of and thereby boosting the performance of each other. In our framework, a dehazing network can estimate a clean image independently of a transmission map estimation during inference, introducing no overhead. Furthermore, our model-agnostic framework can be seamlessly incorporated with other existing dehazing networks, greatly enhancing the performance consistently across datasets and models.
* Published in CIKM 2023, 10 pages, 9 figures
Harnessing Meta-Learning for Improving Full-Frame Video Stabilization
Mar 06, 2024



Video stabilization is a longstanding computer vision problem, particularly pixel-level synthesis solutions for video stabilization which synthesize full frames add to the complexity of this task. These techniques aim to stabilize videos by synthesizing full frames while enhancing the stability of the considered video. This intensifies the complexity of the task due to the distinct mix of unique motion profiles and visual content present in each video sequence, making robust generalization with fixed parameters difficult. In our study, we introduce a novel approach to enhance the performance of pixel-level synthesis solutions for video stabilization by adapting these models to individual input video sequences. The proposed adaptation exploits low-level visual cues accessible during test-time to improve both the stability and quality of resulting videos. We highlight the efficacy of our methodology of "test-time adaptation" through simple fine-tuning of one of these models, followed by significant stability gain via the integration of meta-learning techniques. Notably, significant improvement is achieved with only a single adaptation step. The versatility of the proposed algorithm is demonstrated by consistently improving the performance of various pixel-level synthesis models for video stabilization in real-world scenarios.
Efficient Model Agnostic Approach for Implicit Neural Representation Based Arbitrary-Scale Image Super-Resolution
Nov 20, 2023Single image super-resolution (SISR) has experienced significant advancements, primarily driven by deep convolutional networks. Traditional networks, however, are limited to upscaling images to a fixed scale, leading to the utilization of implicit neural functions for generating arbitrarily scaled images. Nevertheless, these methodologies have imposed substantial computational demands as they involve querying every target pixel to a single resource-intensive decoder. In this paper, we introduce a novel and efficient framework, the Mixture of Experts Implicit Super-Resolution (MoEISR), which enables super-resolution at arbitrary scales with significantly increased computational efficiency without sacrificing reconstruction quality. MoEISR dynamically allocates the most suitable decoding expert to each pixel using a lightweight mapper module, allowing experts with varying capacities to reconstruct pixels across regions with diverse complexities. Our experiments demonstrate that MoEISR successfully reduces up to 73% in floating point operations (FLOPs) while delivering comparable or superior peak signal-to-noise ratio (PSNR).
NoiseTransfer: Image Noise Generation with Contrastive Embeddings
Jan 31, 2023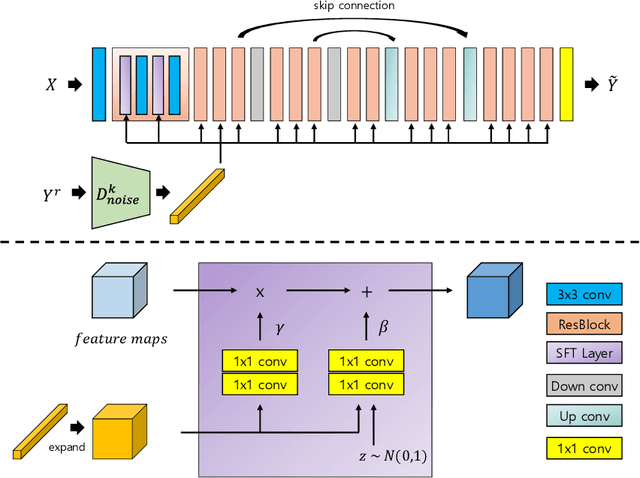
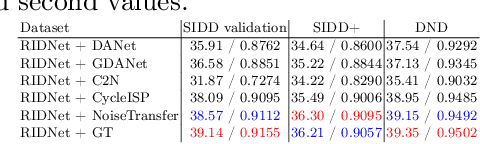
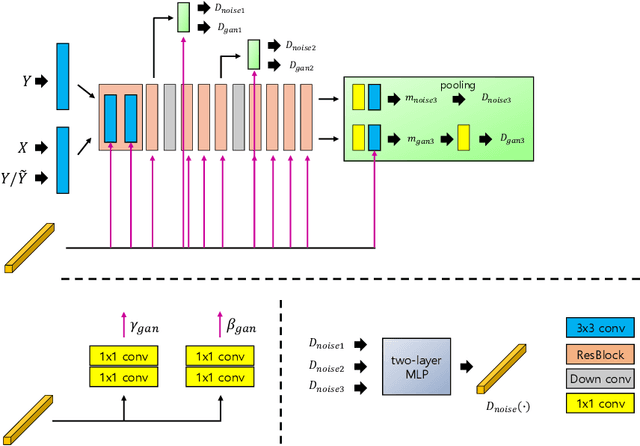

Deep image denoising networks have achieved impressive success with the help of a considerably large number of synthetic train datasets. However, real-world denoising is a still challenging problem due to the dissimilarity between distributions of real and synthetic noisy datasets. Although several real-world noisy datasets have been presented, the number of train datasets (i.e., pairs of clean and real noisy images) is limited, and acquiring more real noise datasets is laborious and expensive. To mitigate this problem, numerous attempts to simulate real noise models using generative models have been studied. Nevertheless, previous works had to train multiple networks to handle multiple different noise distributions. By contrast, we propose a new generative model that can synthesize noisy images with multiple different noise distributions. Specifically, we adopt recent contrastive learning to learn distinguishable latent features of the noise. Moreover, our model can generate new noisy images by transferring the noise characteristics solely from a single reference noisy image. We demonstrate the accuracy and the effectiveness of our noise model for both known and unknown noise removal.