 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDF: Iterative Dynamic Filtering Networks for Generalizable Image Denoising
Aug 27, 2025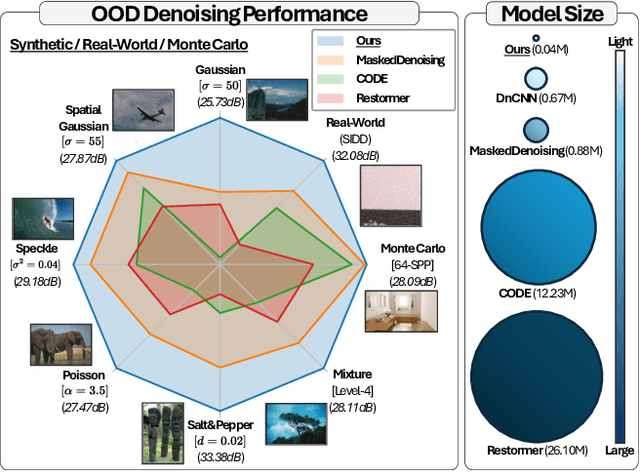
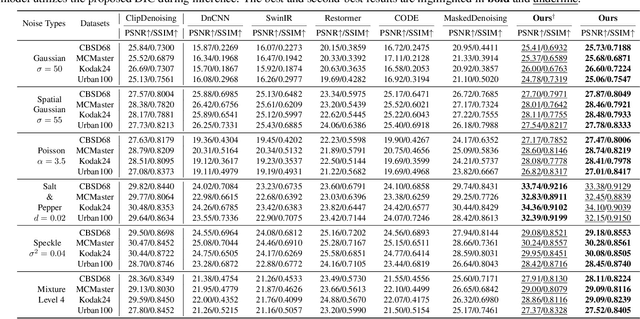

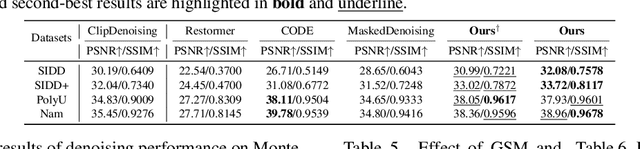
Image denoising is a fundamental challenge in computer vision, with applications in photography and medical imaging. While deep learning-based methods have shown remarkable success, their reliance on specific noise distributions limits generalization to unseen noise types and levels. Existing approaches attempt to address this with extensive training data and high computational resources but they still suffer from overfitting. To address these issues, we conduct image denoising by utilizing dynamically generated kernels via efficient operations. This approach helps prevent overfitting and improves resilience to unseen noise. Specifically, our method leverages a Feature Extraction Module for robust noise-invariant features, Global Statistics and Local Correlation Modules to capture comprehensive noise characteristics and structural correlations. The Kernel Prediction Module then employs these cues to produce pixel-wise varying kernels adapted to local structures, which are then applied iteratively for denoising. This ensures both efficiency and superior restoration quality. Despite being trained on single-level Gaussian noise, our compact model (~ 0.04 M) excels across diverse noise types and levels, demonstrating the promise of iterative dynamic filtering for practical image denoising.
Harnessing Meta-Learning for Controllable Full-Frame Video Stabilization
Aug 26, 2025Video stabilization remains a fundamental problem in computer vision, particularly pixel-level synthesis solutions for video stabilization, which synthesize full-frame outputs, add to the complexity of this task. These methods aim to enhance stability while synthesizing full-frame videos, but the inherent diversity in motion profiles and visual content present in each video sequence makes robust generalization with fixed parameters difficult. To address this, we present a novel method that improves pixel-level synthesis video stabilization methods by rapidly adapting models to each input video at test time. The proposed approach takes advantage of low-level visual cues available during inference to improve both the stability and visual quality of the output. Notably, the proposed rapid adaptation achieves significant performance gains even with a single adaptation pass. We further propose a jerk localization module and a targeted adaptation strategy, which focuses the adaptation on high-jerk segments for maximizing stability with fewer adaptation steps. The proposed methodology enables modern stabilizers to overcome the longstanding SOTA approaches while maintaining the full frame nature of the modern methods, while offering users with control mechanisms akin to classical approaches. Extensive experiments on diverse real-world datasets demonstrate the versatility of the proposed method. Our approach consistently improves the performance of various full-frame synthesis models in both qualitative and quantitative terms, including results on downstream applications.
Harnessing Meta-Learning for Improving Full-Frame Video Stabilization
Mar 06, 2024



Video stabilization is a longstanding computer vision problem, particularly pixel-level synthesis solutions for video stabilization which synthesize full frames add to the complexity of this task. These techniques aim to stabilize videos by synthesizing full frames while enhancing the stability of the considered video. This intensifies the complexity of the task due to the distinct mix of unique motion profiles and visual content present in each video sequence, making robust generalization with fixed parameters difficult. In our study, we introduce a novel approach to enhance the performance of pixel-level synthesis solutions for video stabilization by adapting these models to individual input video sequences. The proposed adaptation exploits low-level visual cues accessible during test-time to improve both the stability and quality of resulting videos. We highlight the efficacy of our methodology of "test-time adaptation" through simple fine-tuning of one of these models, followed by significant stability gain via the integration of meta-learning techniques. Notably, significant improvement is achieved with only a single adaptation step. The versatility of the proposed algorithm is demonstrated by consistently improving the performance of various pixel-level synthesis models for video stabilization in real-world scenarios.
Learning Task Agnostic Temporal Consistency Correction
Jun 08, 2022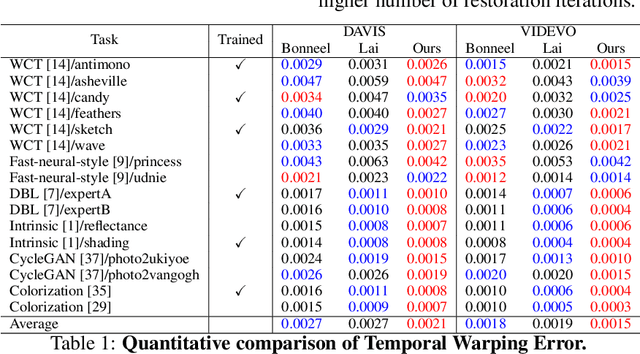

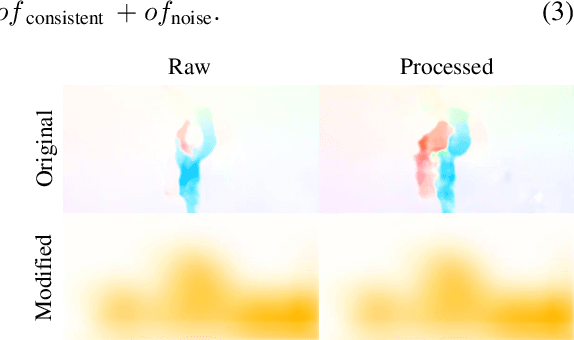
Due to the scarcity of video processing methodologies, image processing operations are naively extended to the video domain by processing each frame independently. This disregard for the temporal connection in video processing often leads to severe temporal inconsistencies. State-of-the-art techniques that address these inconsistencies rely on the availability of unprocessed videos to siphon consistent video dynamics to restore the temporal consistency of frame-wise processed videos. We propose a novel general framework for this task that learns to infer consistent motion dynamics from inconsistent videos to mitigate the temporal flicker while preserving the perceptual quality for both the temporally neighboring and relatively distant frames. The proposed framework produces state-of-the-art results on two large-scale datasets, DAVIS and videvo.net, processed by numerous image processing tasks in a feed-forward manner. The code and the trained models will be released upon acceptance.
Learning Deep Video Stabilization without Optical Flow
Nov 19, 2020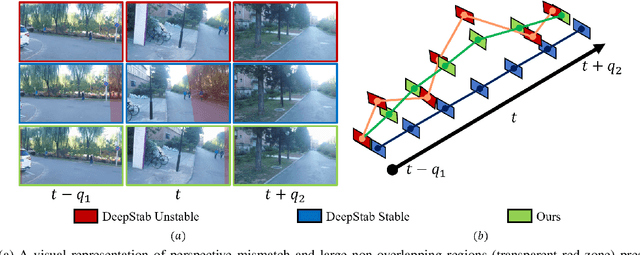

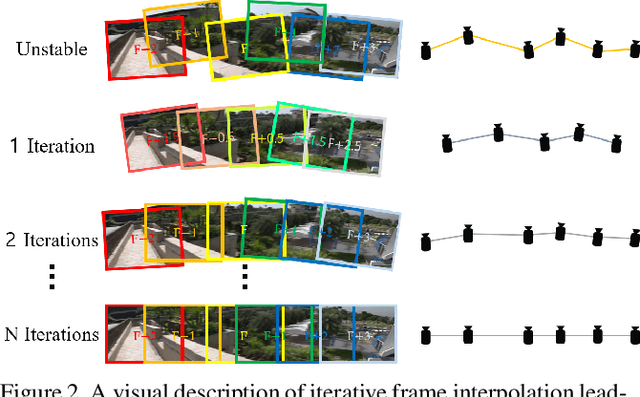

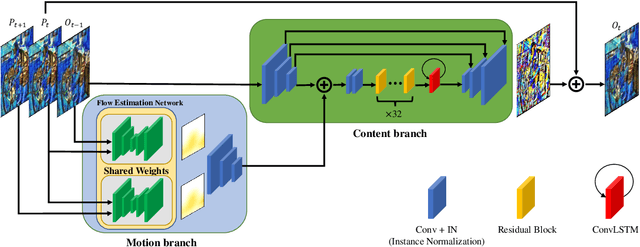
Learning the necessary high-level reasoning for video stabilization without the help of optical flow has proved to be one of the most challenging tasks in the field of computer vision. In this work, we present an iterative frame interpolation strategy to generate a novel dataset that is diverse enough to formulate video stabilization as a supervised learning problem unassisted by optical flow. A major benefit of treating video stabilization as a pure RGB based generative task over the conventional optical flow assisted approaches is the preservation of content and resolution, which is usually obstructed in the latter approaches. To do so, we provide a new video stabilization dataset and train an efficient network that can produce competitive stabilization results in a fraction of the time taken to do the same with the recent iterative frame interpolation schema. Our method provides qualitatively and quantitatively better results than those generated through state-of-the-art video stabilization methods. To the best of our knowledge, this is the only work that demonstrates the importance of perspective in formulating video stabilization as a deep learning problem instead of replacing it with an inter-frame motion measure