 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcrete Jungle: Towards Concreteness Paved Contrastive Negative Mining for Compositional Understanding
Apr 14, 2026Vision-Language Models demonstrate remarkable capabilities but often struggle with compositional reasoning, exhibiting vulnerabilities regarding word order and attribute binding. This limitation arises from a scarcity of informative samples needed to differentiate subtle semantic variations during contrastive pretraining. Although hard negative mining offers a promising remedy, existing methods lack explicit mechanisms to dictate which linguistic elements undergo modification. Instead of engineering generative architectures, this study establishes lexical concreteness as a fundamental determinant of negative sample efficacy. Modifying highly concrete terms generates more pronounced structural and visual discrepancies, providing a substantially stronger learning signal. Leveraging this principle, ConcretePlant is proposed to systematically isolate and manipulate perceptually grounded concepts. Analyses of the InfoNCE further reveals a severe gradient imbalance, where easily distinguishable pairs disproportionately overwhelm the optimization process and restrict the bandwidth available for nuanced learning. To resolve this degradation, the Cement loss is formulated utilizing a margin-based approach. By correlating psycholinguistic scores with sample difficulty, this objective dynamically calibrates the penalization applied to individual training pairs. Comprehensive evaluations substantiate these theoretical claims. The integrated framework, designated as Slipform, achieves state-of-the-art accuracy across diverse compositional evaluation benchmarks, general cross-modal retrieval, single and multi label linear probing.
Harnessing Meta-Learning for Controllable Full-Frame Video Stabilization
Aug 26, 2025Video stabilization remains a fundamental problem in computer vision, particularly pixel-level synthesis solutions for video stabilization, which synthesize full-frame outputs, add to the complexity of this task. These methods aim to enhance stability while synthesizing full-frame videos, but the inherent diversity in motion profiles and visual content present in each video sequence makes robust generalization with fixed parameters difficult. To address this, we present a novel method that improves pixel-level synthesis video stabilization methods by rapidly adapting models to each input video at test time. The proposed approach takes advantage of low-level visual cues available during inference to improve both the stability and visual quality of the output. Notably, the proposed rapid adaptation achieves significant performance gains even with a single adaptation pass. We further propose a jerk localization module and a targeted adaptation strategy, which focuses the adaptation on high-jerk segments for maximizing stability with fewer adaptation steps. The proposed methodology enables modern stabilizers to overcome the longstanding SOTA approaches while maintaining the full frame nature of the modern methods, while offering users with control mechanisms akin to classical approaches. Extensive experiments on diverse real-world datasets demonstrate the versatility of the proposed method. Our approach consistently improves the performance of various full-frame synthesis models in both qualitative and quantitative terms, including results on downstream applications.
Deep Variational Bayesian Modeling of Haze Degradation Process
Dec 04, 2024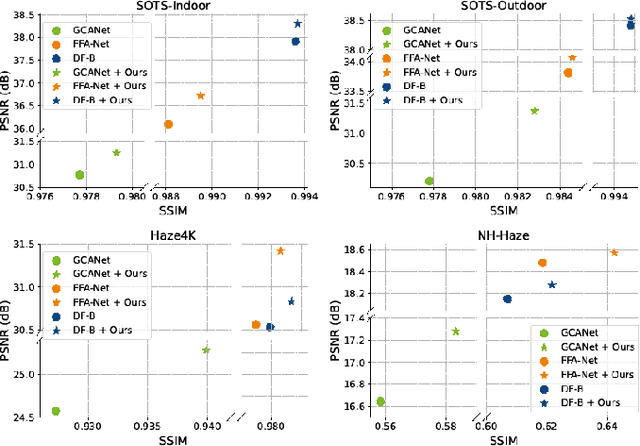
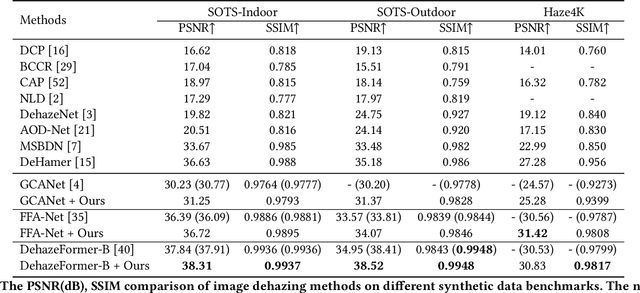
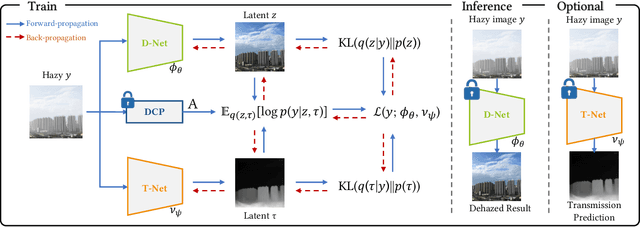
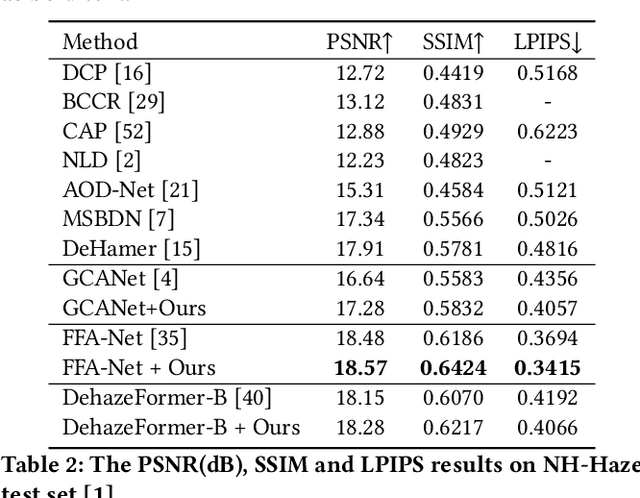
Relying on the representation power of neural networks, most recent works have often neglected several factors involved in haze degradation, such as transmission (the amount of light reaching an observer from a scene over distance) and atmospheric light. These factors are generally unknown, making dehazing problems ill-posed and creating inherent uncertainties. To account for such uncertainties and factors involved in haze degradation, we introduce a variational Bayesian framework for single image dehazing. We propose to take not only a clean image and but also transmission map as latent variables, the posterior distributions of which are parameterized by corresponding neural networks: dehazing and transmission networks, respectively. Based on a physical model for haze degradation, our variational Bayesian framework leads to a new objective function that encourages the cooperation between them, facilitating the joint training of and thereby boosting the performance of each other. In our framework, a dehazing network can estimate a clean image independently of a transmission map estimation during inference, introducing no overhead. Furthermore, our model-agnostic framework can be seamlessly incorporated with other existing dehazing networks, greatly enhancing the performance consistently across datasets and models.
* Published in CIKM 2023, 10 pages, 9 figures
VidHalluc: Evaluating Temporal Hallucinations in Multimodal Large Language Models for Video Understanding
Dec 04, 2024



Multimodal large language models (MLLMs) have recently shown significant advancements in video understanding, excelling in content reasoning and instruction-following tasks. However, the problem of hallucination, where models generate inaccurate or misleading content, remains underexplored in the video domain. Building on the observation that the visual encoder of MLLMs often struggles to differentiate between video pairs that are visually distinct but semantically similar, we introduce VidHalluc, the largest benchmark designed to examine hallucinations in MLLMs for video understanding tasks. VidHalluc assesses hallucinations across three critical dimensions: (1) action, (2) temporal sequence, and (3) scene transition. VidHalluc consists of 5,002 videos, paired based on semantic similarity and visual differences, focusing on cases where hallucinations are most likely to occur. Through comprehensive testing, our experiments show that most MLLMs are vulnerable to hallucinations across these dimensions. Furthermore, we propose DINO-HEAL, a training-free method that reduces hallucinations by incorporating spatial saliency information from DINOv2 to reweight visual features during inference. Our results demonstrate that DINO-HEAL consistently improves performance on VidHalluc, achieving an average improvement of 3.02% in mitigating hallucinations among all tasks. Both the VidHalluc benchmark and DINO-HEAL code can be accessed via $\href{https://vid-halluc.github.io/}{\text{this link}}$.
Harnessing Meta-Learning for Improving Full-Frame Video Stabilization
Mar 06, 2024



Video stabilization is a longstanding computer vision problem, particularly pixel-level synthesis solutions for video stabilization which synthesize full frames add to the complexity of this task. These techniques aim to stabilize videos by synthesizing full frames while enhancing the stability of the considered video. This intensifies the complexity of the task due to the distinct mix of unique motion profiles and visual content present in each video sequence, making robust generalization with fixed parameters difficult. In our study, we introduce a novel approach to enhance the performance of pixel-level synthesis solutions for video stabilization by adapting these models to individual input video sequences. The proposed adaptation exploits low-level visual cues accessible during test-time to improve both the stability and quality of resulting videos. We highlight the efficacy of our methodology of "test-time adaptation" through simple fine-tuning of one of these models, followed by significant stability gain via the integration of meta-learning techniques. Notably, significant improvement is achieved with only a single adaptation step. The versatility of the proposed algorithm is demonstrated by consistently improving the performance of various pixel-level synthesis models for video stabilization in real-world scenarios.