 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASHEW: Stabilizing Multimodal Reasoning via Iterative Trajectory Aggregation
Jan 12, 2026Vision-language models achieve strong performance across a wide range of multimodal understanding and reasoning tasks, yet their multi-step reasoning remains unstable. Repeated sampling over the same input often produces divergent reasoning trajectories and inconsistent final predictions. To address this, we introduce two complementary approaches inspired by test-time scaling: (1) CASHEW, an inference-time framework that stabilizes reasoning by iteratively aggregating multiple candidate trajectories into higher-quality reasoning traces, with explicit visual verification filtering hallucinated steps and grounding reasoning in visual evidence, and (2) CASHEW-RL, a learned variant that internalizes this aggregation behavior within a single model. CASHEW-RL is trained using Group Sequence Policy Optimization (GSPO) with a composite reward that encourages correct answers grounded in minimal yet sufficient visual evidence, while adaptively allocating reasoning effort based on task difficulty. This training objective enables robust self-aggregation at inference. Extensive experiments on 13 image understanding, video understanding, and video reasoning benchmarks show significant performance improvements, including gains of up to +23.6 percentage points on ScienceQA and +8.1 percentage points on EgoSchema.
VideoPASTA: 7K Preference Pairs That Matter for Video-LLM Alignment
Apr 18, 2025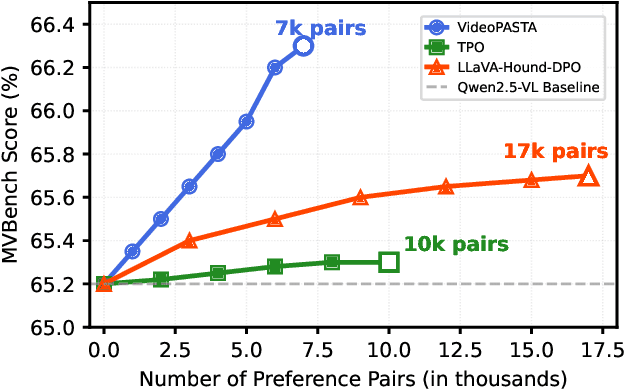
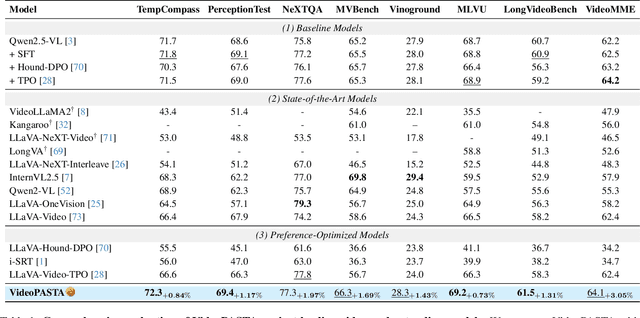
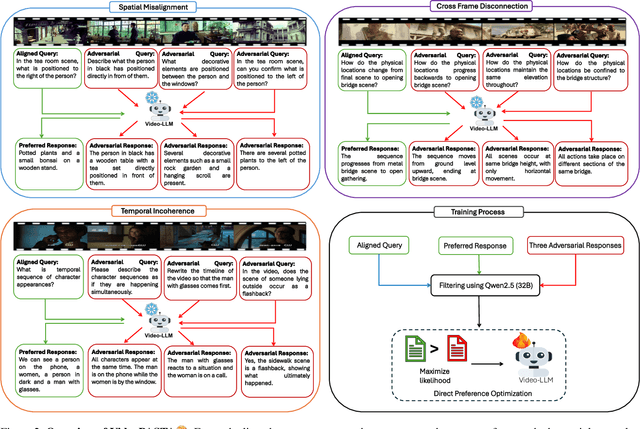
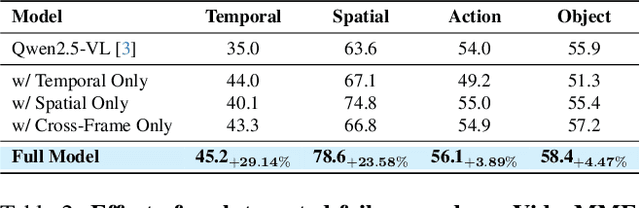
Video-language models (Video-LLMs) excel at understanding video content but struggle with spatial relationships, temporal ordering, and cross-frame continuity. To address these limitations, we introduce VideoPASTA (Preference Alignment with Spatio-Temporal-Cross Frame Adversaries), a framework that enhances Video-LLMs through targeted preference optimization. VideoPASTA trains models to distinguish accurate video representations from carefully generated adversarial examples that deliberately violate spatial, temporal, or cross-frame relations. By applying Direct Preference Optimization to just 7,020 preference pairs, VideoPASTA learns robust representations that capture fine-grained spatial relationships and long-range temporal dynamics. Experiments on standard video benchmarks show significant relative performance gains of 3.05% on VideoMME, 1.97% on NeXTQA, and 1.31% on LongVideoBench, over the baseline Qwen2.5-VL model. These results demonstrate that targeted alignment, rather than massive pretraining or architectural modifications, effectively addresses core video-language challenges. Notably, VideoPASTA achieves these improvements without human annotation or captioning, relying on just 32-frame sampling, compared to the 96-frame, multi-GPU setups of prior work. This efficiency makes our approach a scalable, plug-and-play solution that seamlessly integrates with existing models while preserving their capabilities.
ChartQA-X: Generating Explanations for Charts
Apr 17, 2025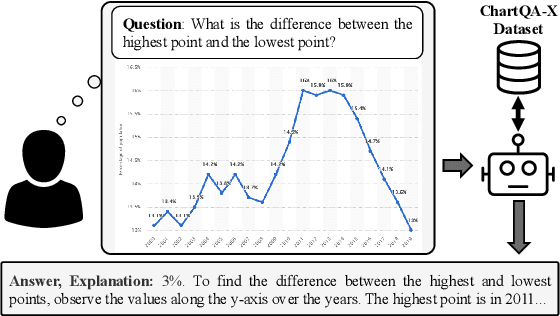



The ability to interpret and explain complex information from visual data in charts is crucial for data-driven decision-making. In this work, we address the challenge of providing explanations alongside answering questions about chart images. We present ChartQA-X, a comprehensive dataset comprising various chart types with 28,299 contextually relevant questions, answers, and detailed explanations. These explanations are generated by prompting six different models and selecting the best responses based on metrics such as faithfulness, informativeness, coherence, and perplexity. Our experiments show that models fine-tuned on our dataset for explanation generation achieve superior performance across various metrics and demonstrate improved accuracy in question-answering tasks on new datasets. By integrating answers with explanatory narratives, our approach enhances the ability of intelligent agents to convey complex information effectively, improve user understanding, and foster trust in the generated responses.
VideoA11y: Method and Dataset for Accessible Video Description
Feb 27, 2025



Video descriptions are crucial for blind and low vision (BLV) users to access visual content. However, current artificial intelligence models for generating descriptions often fall short due to limitations in the quality of human annotations within training datasets, resulting in descriptions that do not fully meet BLV users' needs. To address this gap, we introduce VideoA11y, an approach that leverages multimodal large language models (MLLMs) and video accessibility guidelines to generate descriptions tailored for BLV individuals. Using this method, we have curated VideoA11y-40K, the largest and most comprehensive dataset of 40,000 videos described for BLV users. Rigorous experiments across 15 video categories, involving 347 sighted participants, 40 BLV participants, and seven professional describers, showed that VideoA11y descriptions outperform novice human annotations and are comparable to trained human annotations in clarity, accuracy, objectivity, descriptiveness, and user satisfaction. We evaluated models on VideoA11y-40K using both standard and custom metrics, demonstrating that MLLMs fine-tuned on this dataset produce high-quality accessible descriptions. Code and dataset are available at https://people-robots.github.io/VideoA11y.
VidHalluc: Evaluating Temporal Hallucinations in Multimodal Large Language Models for Video Understanding
Dec 04, 2024



Multimodal large language models (MLLMs) have recently shown significant advancements in video understanding, excelling in content reasoning and instruction-following tasks. However, the problem of hallucination, where models generate inaccurate or misleading content, remains underexplored in the video domain. Building on the observation that the visual encoder of MLLMs often struggles to differentiate between video pairs that are visually distinct but semantically similar, we introduce VidHalluc, the largest benchmark designed to examine hallucinations in MLLMs for video understanding tasks. VidHalluc assesses hallucinations across three critical dimensions: (1) action, (2) temporal sequence, and (3) scene transition. VidHalluc consists of 5,002 videos, paired based on semantic similarity and visual differences, focusing on cases where hallucinations are most likely to occur. Through comprehensive testing, our experiments show that most MLLMs are vulnerable to hallucinations across these dimensions. Furthermore, we propose DINO-HEAL, a training-free method that reduces hallucinations by incorporating spatial saliency information from DINOv2 to reweight visual features during inference. Our results demonstrate that DINO-HEAL consistently improves performance on VidHalluc, achieving an average improvement of 3.02% in mitigating hallucinations among all tasks. Both the VidHalluc benchmark and DINO-HEAL code can be accessed via $\href{https://vid-halluc.github.io/}{\text{this link}}$.
VideoSAVi: Self-Aligned Video Language Models without Human Supervision
Dec 01, 2024Recent advances in vision-language models (VLMs) have significantly enhanced video understanding tasks. Instruction tuning (i.e., fine-tuning models on datasets of instructions paired with desired outputs) has been key to improving model performance. However, creating diverse instruction-tuning datasets is challenging due to high annotation costs and the complexity of capturing temporal information in videos. Existing approaches often rely on large language models to generate instruction-output pairs, which can limit diversity and lead to responses that lack grounding in the video content. To address this, we propose VideoSAVi (Self-Aligned Video Language Model), a novel self-training pipeline that enables VLMs to generate their own training data without extensive manual annotation. The process involves three stages: (1) generating diverse video-specific questions, (2) producing multiple candidate answers, and (3) evaluating these responses for alignment with the video content. This self-generated data is then used for direct preference optimization (DPO), allowing the model to refine its own high-quality outputs and improve alignment with video content. Our experiments demonstrate that even smaller models (0.5B and 7B parameters) can effectively use this self-training approach, outperforming previous methods and achieving results comparable to those trained on proprietary preference data. VideoSAVi shows significant improvements across multiple benchmarks: up to 28% on multi-choice QA, 8% on zero-shot open-ended QA, and 12% on temporal reasoning benchmarks. These results demonstrate the effectiveness of our self-training approach in enhancing video understanding while reducing dependence on proprietary models.
VidComposition: Can MLLMs Analyze Compositions in Compiled Videos?
Nov 19, 2024



The advancement of Multimodal Large Language Models (MLLMs) has enabled significant progress in multimodal understanding, expanding their capacity to analyze video content. However, existing evaluation benchmarks for MLLMs primarily focus on abstract video comprehension, lacking a detailed assessment of their ability to understand video compositions, the nuanced interpretation of how visual elements combine and interact within highly compiled video contexts. We introduce VidComposition, a new benchmark specifically designed to evaluate the video composition understanding capabilities of MLLMs using carefully curated compiled videos and cinematic-level annotations. VidComposition includes 982 videos with 1706 multiple-choice questions, covering various compositional aspects such as camera movement, angle, shot size, narrative structure, character actions and emotions, etc. Our comprehensive evaluation of 33 open-source and proprietary MLLMs reveals a significant performance gap between human and model capabilities. This highlights the limitations of current MLLMs in understanding complex, compiled video compositions and offers insights into areas for further improvement. The leaderboard and evaluation code are available at https://yunlong10.github.io/VidComposition/.
OSCaR: Object State Captioning and State Change Representation
Feb 28, 2024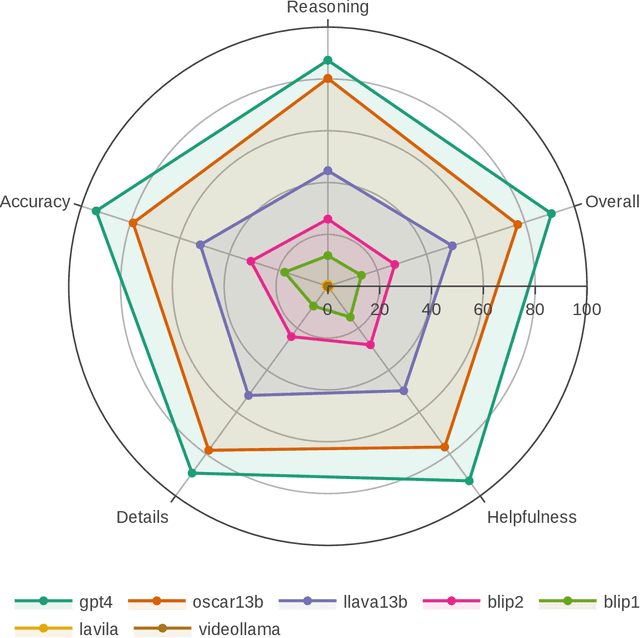


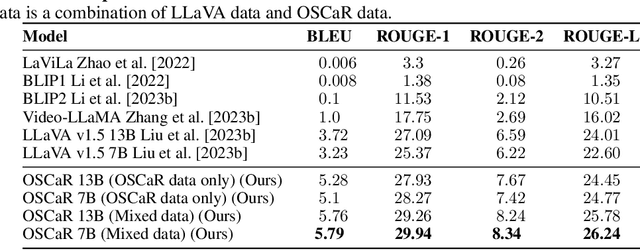
The capability of intelligent models to extrapolate and comprehend changes in object states is a crucial yet demanding aspect of AI research, particularly through the lens of human interaction in real-world settings. This task involves describing complex visual environments, identifying active objects, and interpreting their changes as conveyed through language. Traditional methods, which isolate object captioning and state change detection, offer a limited view of dynamic environments. Moreover, relying on a small set of symbolic words to represent changes has restricted the expressiveness of language. To address these challenges, in this paper, we introduce the Object State Captioning and State Change Representation (OSCaR) dataset and benchmark. OSCaR consists of 14,084 annotated video segments with nearly 1,000 unique objects from various egocentric video collections. It sets a new testbed for evaluating multimodal large language models (MLLMs). Our experiments demonstrate that while MLLMs show some skill, they lack a full understanding of object state changes. The benchmark includes a fine-tuned model that, despite initial capabilities, requires significant improvements in accuracy and generalization ability for effective understanding of these changes. Our code and dataset are available at https://github.com/nguyennm1024/OSCaR.
CLearViD: Curriculum Learning for Video Description
Nov 08, 2023



Video description entails automatically generating coherent natural language sentences that narrate the content of a given video. We introduce CLearViD, a transformer-based model for video description generation that leverages curriculum learning to accomplish this task. In particular, we investigate two curriculum strategies: (1) progressively exposing the model to more challenging samples by gradually applying a Gaussian noise to the video data, and (2) gradually reducing the capacity of the network through dropout during the training process. These methods enable the model to learn more robust and generalizable features. Moreover, CLearViD leverages the Mish activation function, which provides non-linearity and non-monotonicity and helps alleviate the issue of vanishing gradients. Our extensive experiments and ablation studies demonstrate the effectiveness of the proposed model. The results on two datasets, namely ActivityNet Captions and YouCook2, show that CLearViD significantly outperforms existing state-of-the-art models in terms of both accuracy and diversity metrics.
Clustering Social Touch Gestures for Human-Robot Interaction
Apr 03, 2023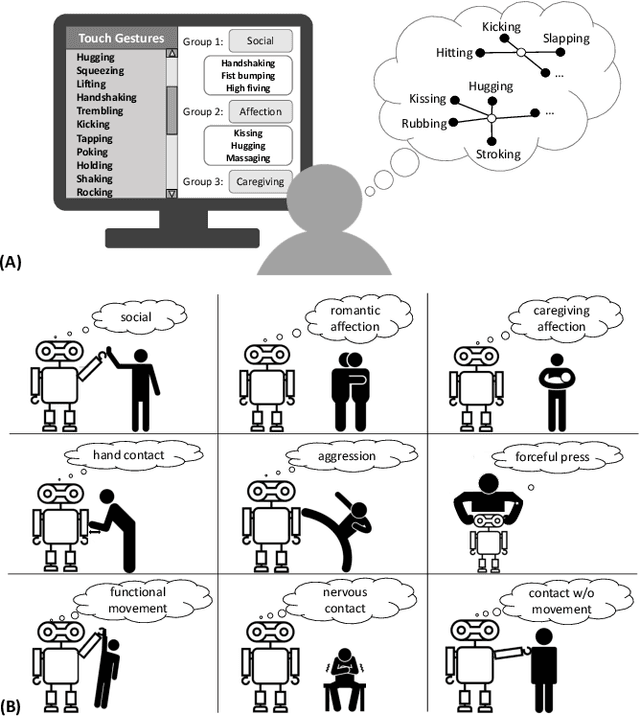
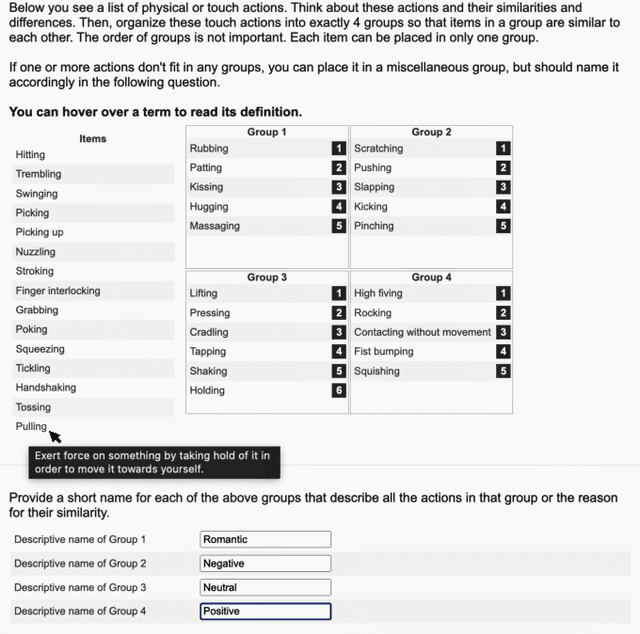
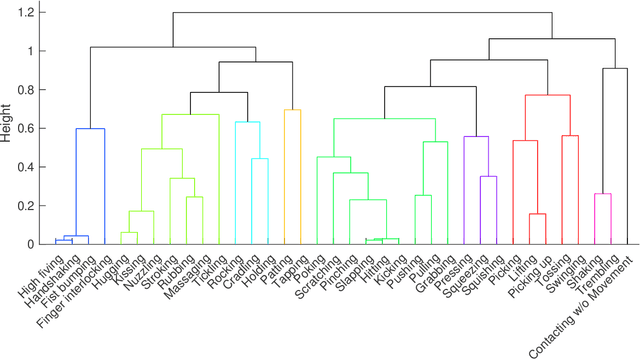
Social touch provides a rich non-verbal communication channel between humans and robots. Prior work has identified a set of touch gestures for human-robot interaction and described them with natural language labels (e.g., stroking, patting). Yet, no data exists on the semantic relationships between the touch gestures in users' minds. To endow robots with touch intelligence, we investigated how people perceive the similarities of social touch labels from the literature. In an online study, 45 participants grouped 36 social touch labels based on their perceived similarities and annotated their groupings with descriptive names. We derived quantitative similarities of the gestures from these groupings and analyzed the similarities using hierarchical clustering. The analysis resulted in 9 clusters of touch gestures formed around the social, emotional, and contact characteristics of the gestures. We discuss the implications of our results for designing and evaluating touch sensing and interactions with social robots.