 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAGLE: Egocentric AGgregated Language-video Engine
Sep 26, 2024



The rapid evolution of egocentric video analysis brings new insights into understanding human activities and intentions from a first-person perspective. Despite this progress, the fragmentation in tasks like action recognition, procedure learning, and moment retrieval, \etc, coupled with inconsistent annotations and isolated model development, hinders a holistic interpretation of video content. In response, we introduce the EAGLE (Egocentric AGgregated Language-video Engine) model and the EAGLE-400K dataset to provide a unified framework that integrates various egocentric video understanding tasks. EAGLE-400K, the \textit{first} large-scale instruction-tuning dataset tailored for egocentric video, features 400K diverse samples to enhance a broad spectrum of tasks from activity recognition to procedure knowledge learning. Moreover, EAGLE, a strong video multimodal large language model (MLLM), is designed to effectively capture both spatial and temporal information. In addition, we propose a set of evaluation metrics designed to facilitate a thorough assessment of MLLM for egocentric video understanding. Our extensive experiments demonstrate EAGLE's superior performance over existing models, highlighting its ability to balance task-specific understanding with holistic video interpretation. With EAGLE, we aim to pave the way for research opportunities and practical applications in real-world scenarios.
OSCaR: Object State Captioning and State Change Representation
Feb 28, 2024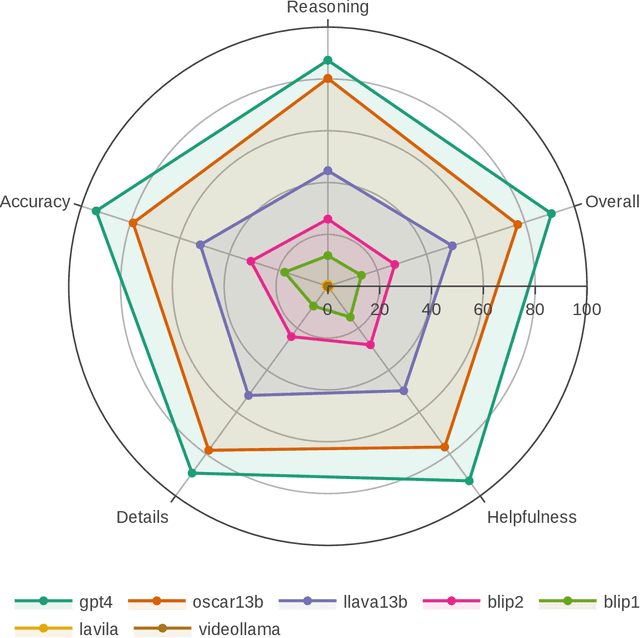


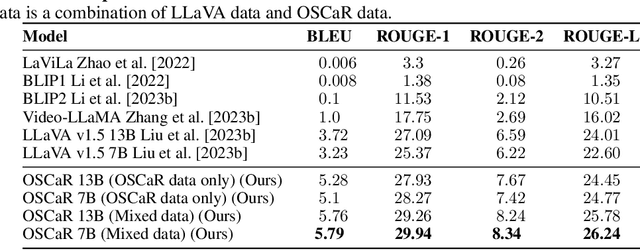
The capability of intelligent models to extrapolate and comprehend changes in object states is a crucial yet demanding aspect of AI research, particularly through the lens of human interaction in real-world settings. This task involves describing complex visual environments, identifying active objects, and interpreting their changes as conveyed through language. Traditional methods, which isolate object captioning and state change detection, offer a limited view of dynamic environments. Moreover, relying on a small set of symbolic words to represent changes has restricted the expressiveness of language. To address these challenges, in this paper, we introduce the Object State Captioning and State Change Representation (OSCaR) dataset and benchmark. OSCaR consists of 14,084 annotated video segments with nearly 1,000 unique objects from various egocentric video collections. It sets a new testbed for evaluating multimodal large language models (MLLMs). Our experiments demonstrate that while MLLMs show some skill, they lack a full understanding of object state changes. The benchmark includes a fine-tuned model that, despite initial capabilities, requires significant improvements in accuracy and generalization ability for effective understanding of these changes. Our code and dataset are available at https://github.com/nguyennm1024/OSCaR.
Efficiently Leveraging Linguistic Priors for Scene Text Spotting
Feb 27, 2024Incorporating linguistic knowledge can improve scene text recognition, but it is questionable whether the same holds for scene text spotting, which typically involves text detection and recognition. This paper proposes a method that leverages linguistic knowledge from a large text corpus to replace the traditional one-hot encoding used in auto-regressive scene text spotting and recognition models. This allows the model to capture the relationship between characters in the same word. Additionally, we introduce a technique to generate text distributions that align well with scene text datasets, removing the need for in-domain fine-tuning. As a result, the newly created text distributions are more informative than pure one-hot encoding, leading to improved spotting and recognition performance. Our method is simple and efficient, and it can easily be integrated into existing auto-regressive-based approaches. Experimental results show that our method not only improves recognition accuracy but also enables more accurate localization of words. It significantly improves both state-of-the-art scene text spotting and recognition pipelines, achieving state-of-the-art results on several benchmarks.