 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoPASTA: 7K Preference Pairs That Matter for Video-LLM Alignment
Apr 18, 2025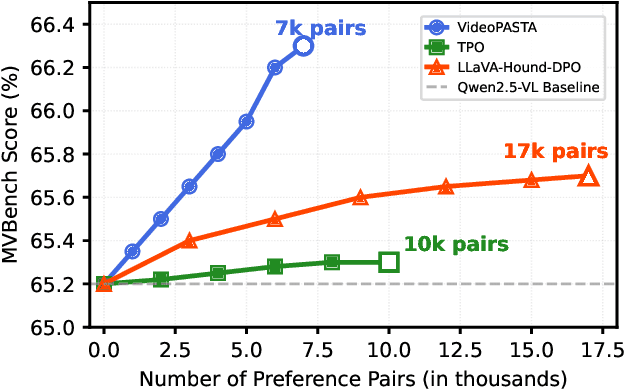
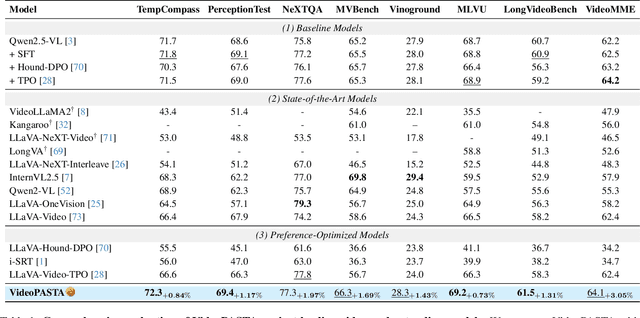
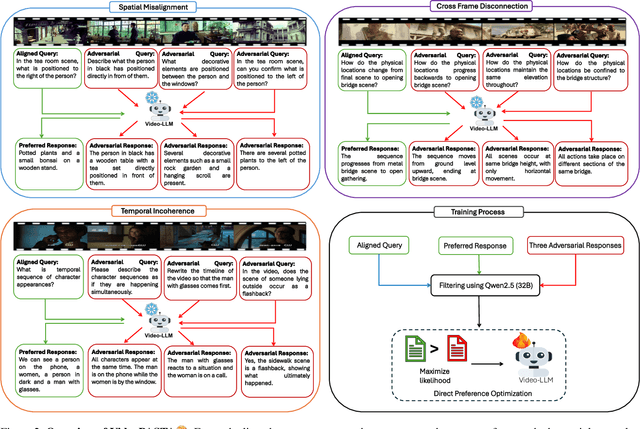
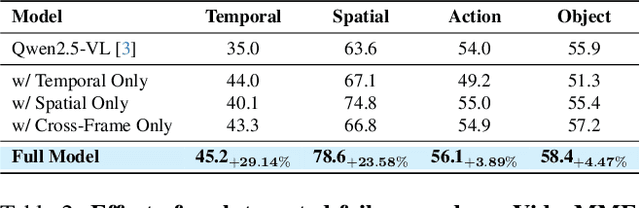
Video-language models (Video-LLMs) excel at understanding video content but struggle with spatial relationships, temporal ordering, and cross-frame continuity. To address these limitations, we introduce VideoPASTA (Preference Alignment with Spatio-Temporal-Cross Frame Adversaries), a framework that enhances Video-LLMs through targeted preference optimization. VideoPASTA trains models to distinguish accurate video representations from carefully generated adversarial examples that deliberately violate spatial, temporal, or cross-frame relations. By applying Direct Preference Optimization to just 7,020 preference pairs, VideoPASTA learns robust representations that capture fine-grained spatial relationships and long-range temporal dynamics. Experiments on standard video benchmarks show significant relative performance gains of 3.05% on VideoMME, 1.97% on NeXTQA, and 1.31% on LongVideoBench, over the baseline Qwen2.5-VL model. These results demonstrate that targeted alignment, rather than massive pretraining or architectural modifications, effectively addresses core video-language challenges. Notably, VideoPASTA achieves these improvements without human annotation or captioning, relying on just 32-frame sampling, compared to the 96-frame, multi-GPU setups of prior work. This efficiency makes our approach a scalable, plug-and-play solution that seamlessly integrates with existing models while preserving their capabilities.
VideoSAVi: Self-Aligned Video Language Models without Human Supervision
Dec 01, 2024Recent advances in vision-language models (VLMs) have significantly enhanced video understanding tasks. Instruction tuning (i.e., fine-tuning models on datasets of instructions paired with desired outputs) has been key to improving model performance. However, creating diverse instruction-tuning datasets is challenging due to high annotation costs and the complexity of capturing temporal information in videos. Existing approaches often rely on large language models to generate instruction-output pairs, which can limit diversity and lead to responses that lack grounding in the video content. To address this, we propose VideoSAVi (Self-Aligned Video Language Model), a novel self-training pipeline that enables VLMs to generate their own training data without extensive manual annotation. The process involves three stages: (1) generating diverse video-specific questions, (2) producing multiple candidate answers, and (3) evaluating these responses for alignment with the video content. This self-generated data is then used for direct preference optimization (DPO), allowing the model to refine its own high-quality outputs and improve alignment with video content. Our experiments demonstrate that even smaller models (0.5B and 7B parameters) can effectively use this self-training approach, outperforming previous methods and achieving results comparable to those trained on proprietary preference data. VideoSAVi shows significant improvements across multiple benchmarks: up to 28% on multi-choice QA, 8% on zero-shot open-ended QA, and 12% on temporal reasoning benchmarks. These results demonstrate the effectiveness of our self-training approach in enhancing video understanding while reducing dependence on proprietary models.
EnsembleNTLDetect: An Intelligent Framework for Electricity Theft Detection in Smart Grid
Oct 09, 2021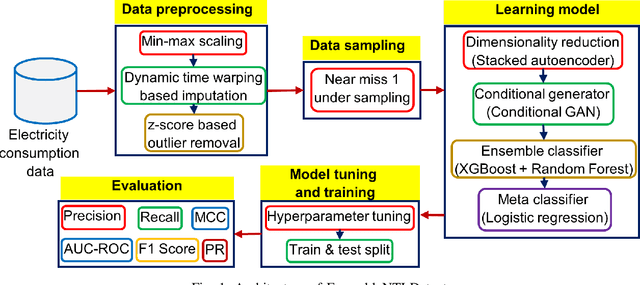
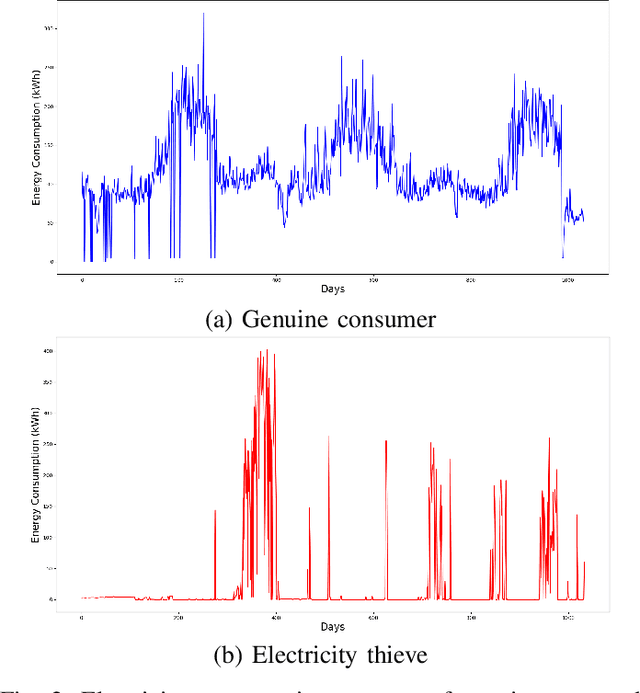
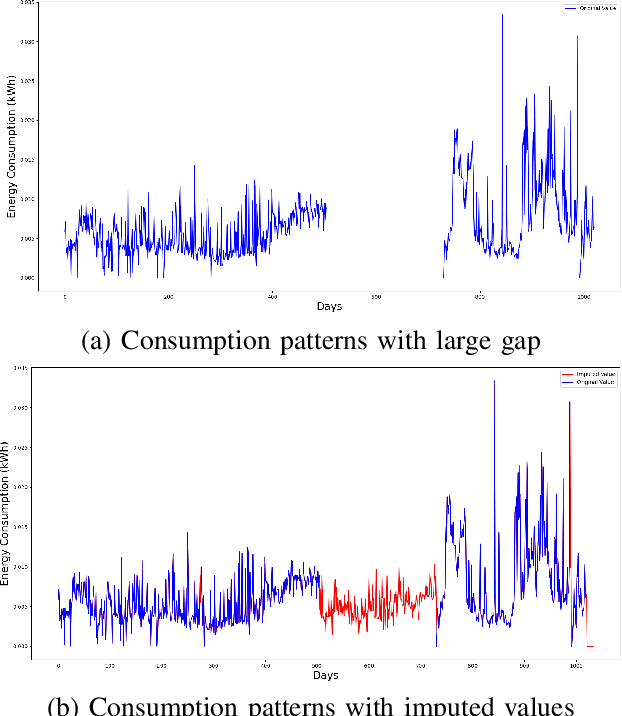
Artificial intelligence-based techniques applied to the electricity consumption data generated from the smart grid prove to be an effective solution in reducing Non Technical Loses (NTLs), thereby ensures safety, reliability, and security of the smart energy systems. However, imbalanced data, consecutive missing values, large training times, and complex architectures hinder the real time application of electricity theft detection models. In this paper, we present EnsembleNTLDetect, a robust and scalable electricity theft detection framework that employs a set of efficient data pre-processing techniques and machine learning models to accurately detect electricity theft by analysing consumers' electricity consumption patterns. This framework utilises an enhanced Dynamic Time Warping Based Imputation (eDTWBI) algorithm to impute missing values in the time series data and leverages the Near-miss undersampling technique to generate balanced data. Further, stacked autoencoder is introduced for dimensionality reduction and to improve training efficiency. A Conditional Generative Adversarial Network (CTGAN) is used to augment the dataset to ensure robust training and a soft voting ensemble classifier is designed to detect the consumers with aberrant consumption patterns. Furthermore, experiments were conducted on the real-time electricity consumption data provided by the State Grid Corporation of China (SGCC) to validate the reliability and efficiency of EnsembleNTLDetect over the state-of-the-art electricity theft detection models in terms of various quality metrics.