 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADIO: Reference-Agnostic Dubbing Video Synthesis
Sep 05, 2023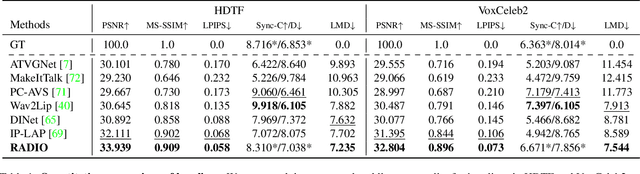
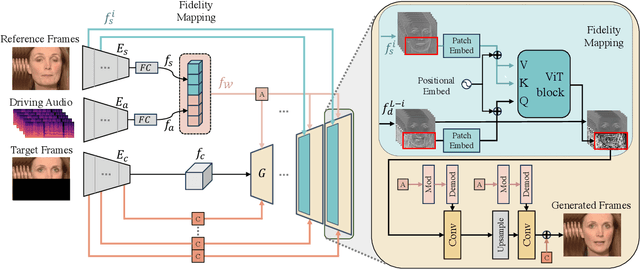
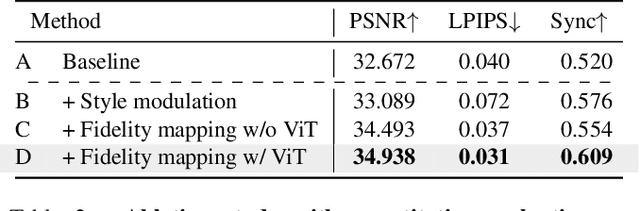
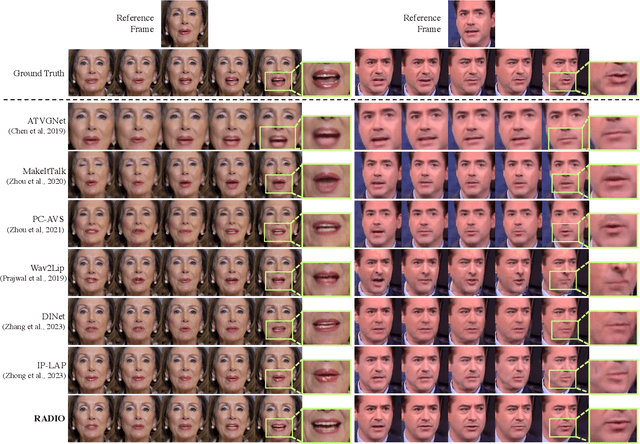
One of the most challenging problems in audio-driven talking head generation is achieving high-fidelity detail while ensuring precise synchronization. Given only a single reference image, extracting meaningful identity attributes becomes even more challenging, often causing the network to mirror the facial and lip structures too closely. To address these issues, we introduce RADIO, a framework engineered to yield high-quality dubbed videos regardless of the pose or expression in reference images. The key is to modulate the decoder layers using latent space composed of audio and reference features. Additionally, we incorporate ViT blocks into the decoder to emphasize high-fidelity details, especially in the lip region. Our experimental results demonstrate that RADIO displays high synchronization without the loss of fidelity. Especially in harsh scenarios where the reference frame deviates significantly from the ground truth, our method outperforms state-of-the-art methods, highlighting its robustness. Pre-trained model and codes will be made public after the review.
Learning Deep Video Stabilization without Optical Flow
Nov 19, 2020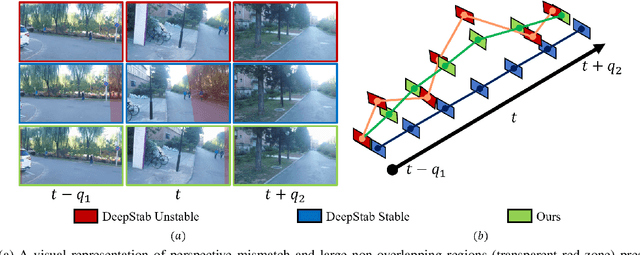

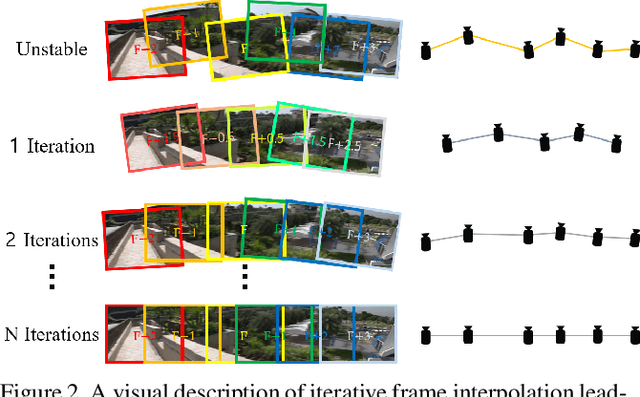

Learning the necessary high-level reasoning for video stabilization without the help of optical flow has proved to be one of the most challenging tasks in the field of computer vision. In this work, we present an iterative frame interpolation strategy to generate a novel dataset that is diverse enough to formulate video stabilization as a supervised learning problem unassisted by optical flow. A major benefit of treating video stabilization as a pure RGB based generative task over the conventional optical flow assisted approaches is the preservation of content and resolution, which is usually obstructed in the latter approaches. To do so, we provide a new video stabilization dataset and train an efficient network that can produce competitive stabilization results in a fraction of the time taken to do the same with the recent iterative frame interpolation schema. Our method provides qualitatively and quantitatively better results than those generated through state-of-the-art video stabilization methods. To the best of our knowledge, this is the only work that demonstrates the importance of perspective in formulating video stabilization as a deep learning problem instead of replacing it with an inter-frame motion measure