 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInlier-Centric Post-Training Quantization for Object Detection Models
Feb 03, 2026Object detection is pivotal in computer vision, yet its immense computational demands make deployment slow and power-hungry, motivating quantization. However, task-irrelevant morphologies such as background clutter and sensor noise induce redundant activations (or anomalies). These anomalies expand activation ranges and skew activation distributions toward task-irrelevant responses, complicating bit allocation and weakening the preservation of informative features. Without a clear criterion to distinguish anomalies, suppressing them can inadvertently discard useful information. To address this, we present InlierQ, an inlier-centric post-training quantization approach that separates anomalies from informative inliers. InlierQ computes gradient-aware volume saliency scores, classifies each volume as an inlier or anomaly, and fits a posterior distribution over these scores using the Expectation-Maximization (EM) algorithm. This design suppresses anomalies while preserving informative features. InlierQ is label-free, drop-in, and requires only 64 calibration samples. Experiments on the COCO and nuScenes benchmarks show consistent reductions in quantization error for camera-based (2D and 3D) and LiDAR-based (3D) object detection.
Comparison Reveals Commonality: Customized Image Generation through Contrastive Inversion
Aug 11, 2025The recent demand for customized image generation raises a need for techniques that effectively extract the common concept from small sets of images. Existing methods typically rely on additional guidance, such as text prompts or spatial masks, to capture the common target concept. Unfortunately, relying on manually provided guidance can lead to incomplete separation of auxiliary features, which degrades generation quality.In this paper, we propose Contrastive Inversion, a novel approach that identifies the common concept by comparing the input images without relying on additional information. We train the target token along with the image-wise auxiliary text tokens via contrastive learning, which extracts the well-disentangled true semantics of the target. Then we apply disentangled cross-attention fine-tuning to improve concept fidelity without overfitting. Experimental results and analysis demonstrate that our method achieves a balanced, high-level performance in both concept representation and editing, outperforming existing techniques.
RADIO: Reference-Agnostic Dubbing Video Synthesis
Sep 05, 2023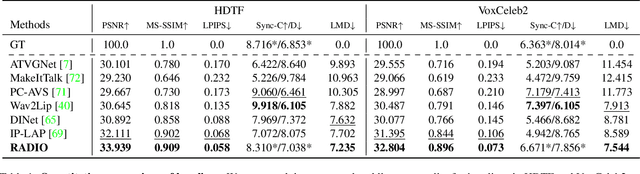
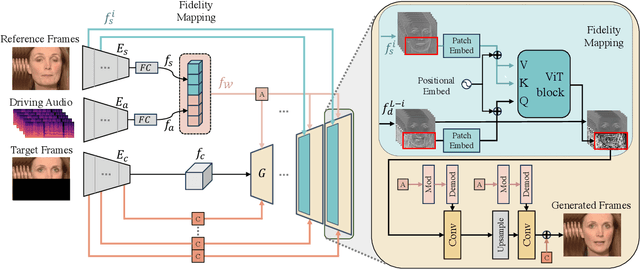
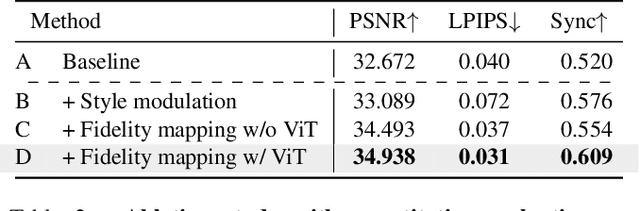
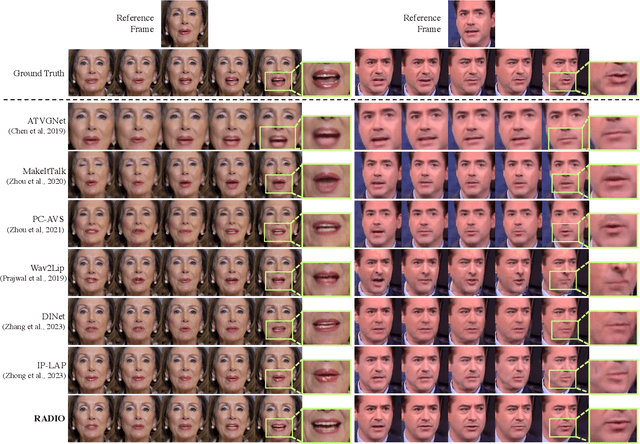
One of the most challenging problems in audio-driven talking head generation is achieving high-fidelity detail while ensuring precise synchronization. Given only a single reference image, extracting meaningful identity attributes becomes even more challenging, often causing the network to mirror the facial and lip structures too closely. To address these issues, we introduce RADIO, a framework engineered to yield high-quality dubbed videos regardless of the pose or expression in reference images. The key is to modulate the decoder layers using latent space composed of audio and reference features. Additionally, we incorporate ViT blocks into the decoder to emphasize high-fidelity details, especially in the lip region. Our experimental results demonstrate that RADIO displays high synchronization without the loss of fidelity. Especially in harsh scenarios where the reference frame deviates significantly from the ground truth, our method outperforms state-of-the-art methods, highlighting its robustness. Pre-trained model and codes will be made public after the review.
Fix the Noise: Disentangling Source Feature for Controllable Domain Translation
Mar 21, 2023Recent studies show strong generative performance in domain translation especially by using transfer learning techniques on the unconditional generator. However, the control between different domain features using a single model is still challenging. Existing methods often require additional models, which is computationally demanding and leads to unsatisfactory visual quality. In addition, they have restricted control steps, which prevents a smooth transition. In this paper, we propose a new approach for high-quality domain translation with better controllability. The key idea is to preserve source features within a disentangled subspace of a target feature space. This allows our method to smoothly control the degree to which it preserves source features while generating images from an entirely new domain using only a single model. Our extensive experiments show that the proposed method can produce more consistent and realistic images than previous works and maintain precise controllability over different levels of transformation. The code is available at https://github.com/LeeDongYeun/FixNoise.
Fix the Noise: Disentangling Source Feature for Transfer Learning of StyleGAN
May 02, 2022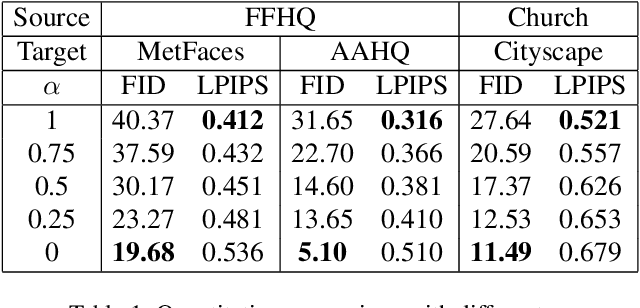
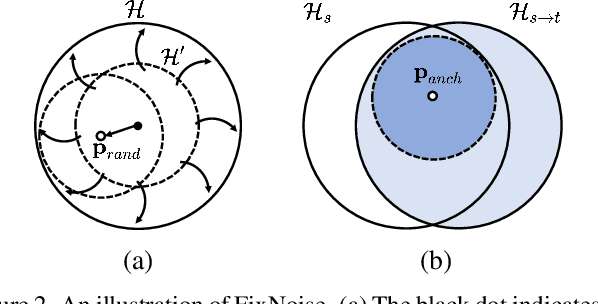
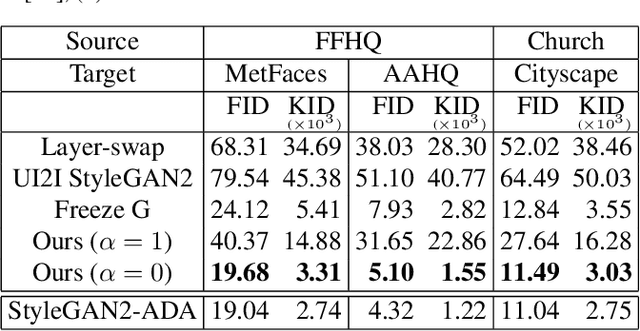

Transfer learning of StyleGAN has recently shown great potential to solve diverse tasks, especially in domain translation. Previous methods utilized a source model by swapping or freezing weights during transfer learning, however, they have limitations on visual quality and controlling source features. In other words, they require additional models that are computationally demanding and have restricted control steps that prevent a smooth transition. In this paper, we propose a new approach to overcome these limitations. Instead of swapping or freezing, we introduce a simple feature matching loss to improve generation quality. In addition, to control the degree of source features, we train a target model with the proposed strategy, FixNoise, to preserve the source features only in a disentangled subspace of a target feature space. Owing to the disentangled feature space, our method can smoothly control the degree of the source features in a single model. Extensive experiments demonstrate that the proposed method can generate more consistent and realistic images than previous works.