 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Visual Artifacts in Diffusion Models via Explainable AI-based Flaw Activation Maps
Dec 09, 2025Diffusion models have achieved remarkable success in image synthesis. However, addressing artifacts and unrealistic regions remains a critical challenge. We propose self-refining diffusion, a novel framework that enhances image generation quality by detecting these flaws. The framework employs an explainable artificial intelligence (XAI)-based flaw highlighter to produce flaw activation maps (FAMs) that identify artifacts and unrealistic regions. These FAMs improve reconstruction quality by amplifying noise in flawed regions during the forward process and by focusing on these regions during the reverse process. The proposed approach achieves up to a 27.3% improvement in Fréchet inception distance across various diffusion-based models, demonstrating consistently strong performance on diverse datasets. It also shows robust effectiveness across different tasks, including image generation, text-to-image generation, and inpainting. These results demonstrate that explainable AI techniques can extend beyond interpretability to actively contribute to image refinement. The proposed framework offers a versatile and effective approach applicable to various diffusion models and tasks, significantly advancing the field of image synthesis.
MatteViT: High-Frequency-Aware Document Shadow Removal with Shadow Matte Guidance
Dec 09, 2025Document shadow removal is essential for enhancing the clarity of digitized documents. Preserving high-frequency details (e.g., text edges and lines) is critical in this process because shadows often obscure or distort fine structures. This paper proposes a matte vision transformer (MatteViT), a novel shadow removal framework that applies spatial and frequency-domain information to eliminate shadows while preserving fine-grained structural details. To effectively retain these details, we employ two preservation strategies. First, our method introduces a lightweight high-frequency amplification module (HFAM) that decomposes and adaptively amplifies high-frequency components. Second, we present a continuous luminance-based shadow matte, generated using a custom-built matte dataset and shadow matte generator, which provides precise spatial guidance from the earliest processing stage. These strategies enable the model to accurately identify fine-grained regions and restore them with high fidelity. Extensive experiments on public benchmarks (RDD and Kligler) demonstrate that MatteViT achieves state-of-the-art performance, providing a robust and practical solution for real-world document shadow removal. Furthermore, the proposed method better preserves text-level details in downstream tasks, such as optical character recognition, improving recognition performance over prior methods.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
FED: Fast and Efficient Dataset Deduplication Framework with GPU Acceleration
Jan 02, 2025Dataset deduplication plays a crucial role in enhancing data quality, ultimately improving training performance and efficiency of LLMs. A commonly used method for data deduplication is the MinHash LSH algorithm. Recently, NVIDIA introduced a GPU-based MinHash LSH deduplication method, but it remains suboptimal, leaving room for further improvement in processing efficiency. This paper proposes a GPU-accelerated deduplication framework \sys that optimizes MinHash LSH for GPU clusters and leverages computationally efficient and partially reusable non-cryptographic hash functions. \sys significantly outperforms the CPU-based deduplication tool included in SlimPajama by up to 58.3 times and the GPU-based deduplication tool included in NVIDIA NeMo Curator by up to 8.6 times when processing 1 million documents with a node of four GPUs. Deduplication of 1.2 trillion tokens is completed in just 5.1 hours in a four-node, 16-GPU environment. The related code is publicly available on GitHub (https://github.com/mcrl/FED).
Incorporating General Contact Surfaces in the Kinematics of Tendon-Driven Rolling-Contact Joint Mechanisms
Sep 01, 2024This paper presents the first kinematic modeling of tendon-driven rolling-contact joint mechanisms with general contact surfaces subject to external loads. We derived the kinematics as a set of recursive equations and developed efficient iterative algorithms to solve for both tendon force actuation and tendon displacement actuation. The configuration predictions of the kinematics were experimentally validated using a prototype mechanism. Our MATLAB implementation of the proposed kinematic is available at https://github.com/hjhdog1/RollingJoint.
RADIO: Reference-Agnostic Dubbing Video Synthesis
Sep 05, 2023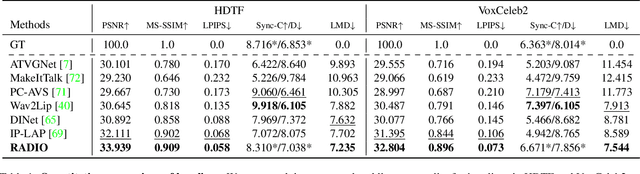
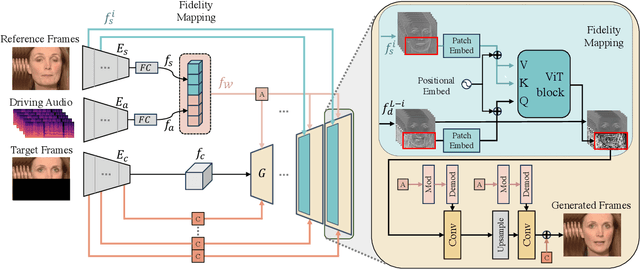
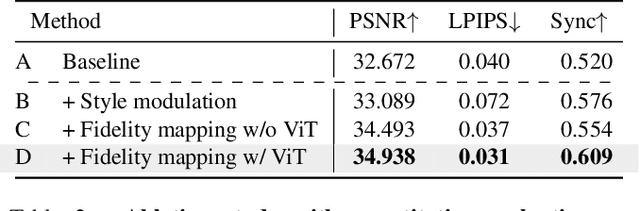
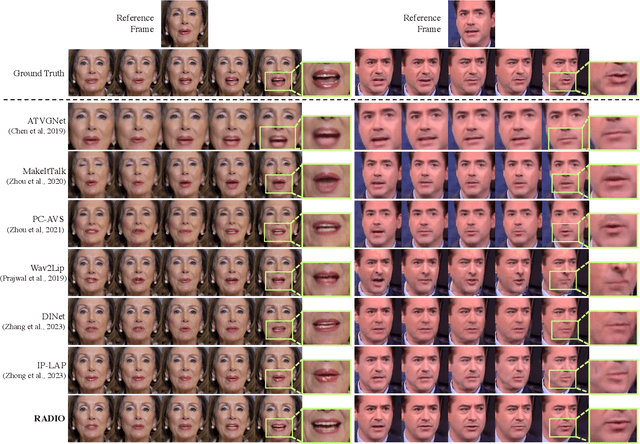
One of the most challenging problems in audio-driven talking head generation is achieving high-fidelity detail while ensuring precise synchronization. Given only a single reference image, extracting meaningful identity attributes becomes even more challenging, often causing the network to mirror the facial and lip structures too closely. To address these issues, we introduce RADIO, a framework engineered to yield high-quality dubbed videos regardless of the pose or expression in reference images. The key is to modulate the decoder layers using latent space composed of audio and reference features. Additionally, we incorporate ViT blocks into the decoder to emphasize high-fidelity details, especially in the lip region. Our experimental results demonstrate that RADIO displays high synchronization without the loss of fidelity. Especially in harsh scenarios where the reference frame deviates significantly from the ground truth, our method outperforms state-of-the-art methods, highlighting its robustness. Pre-trained model and codes will be made public after the review.
WaGI : Wavelet-based GAN Inversion for Preserving High-frequency Image Details
Oct 18, 2022
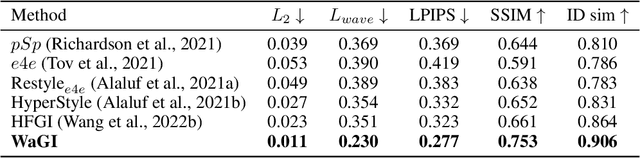
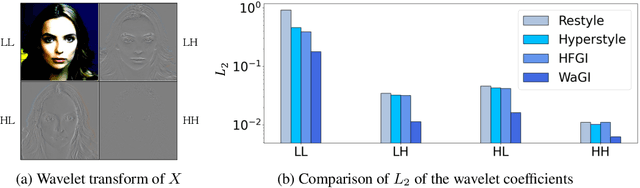

Recent GAN inversion models focus on preserving image-specific details through various methods, e.g., generator tuning or feature mixing. While those are helpful for preserving details compared to a naiive low-rate latent inversion, they still fail to maintain high-frequency features precisely. In this paper, we point out that the existing GAN inversion models have inherent limitations in both structural and training aspects, which preclude the delicate reconstruction of high-frequency features. Especially, we prove that the widely-used loss term in GAN inversion, i.e., L2, is biased to reconstruct low-frequency features mainly. To overcome this problem, we propose a novel GAN inversion model, coined WaGI, which enables to handle high-frequency features explicitly, by using a novel wavelet-based loss term and a newly proposed wavelet fusion scheme. To the best of our knowledge, WaGI is the first attempt to interpret GAN inversion in the frequency domain. We demonstrate that WaGI shows outstanding results on both inversion and editing, compared to the existing state-of-the-art GAN inversion models. Especially, WaGI robustly preserves high-frequency features of images even in the editing scenario. We will release our code with the pre-trained model after the review.
Zero-shot Blind Image Denoising via Implicit Neural Representations
Apr 05, 2022
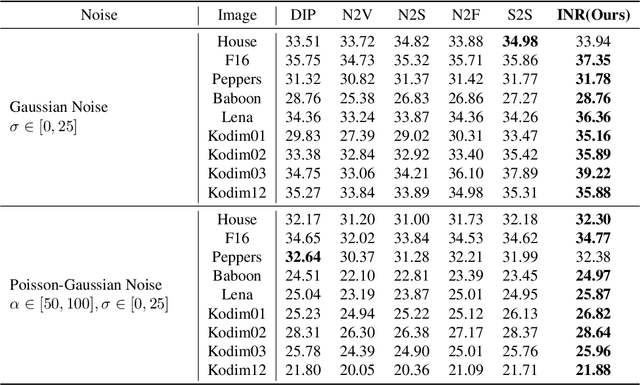
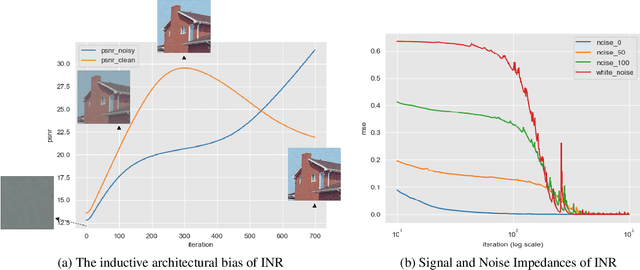
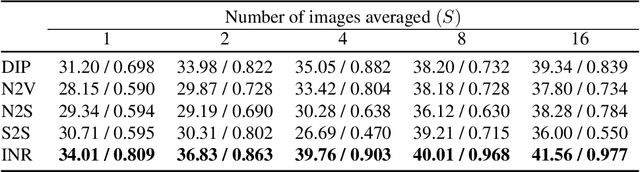
Recent denoising algorithms based on the "blind-spot" strategy show impressive blind image denoising performances, without utilizing any external dataset. While the methods excel in recovering highly contaminated images, we observe that such algorithms are often less effective under a low-noise or real noise regime. To address this gap, we propose an alternative denoising strategy that leverages the architectural inductive bias of implicit neural representations (INRs), based on our two findings: (1) INR tends to fit the low-frequency clean image signal faster than the high-frequency noise, and (2) INR layers that are closer to the output play more critical roles in fitting higher-frequency parts. Building on these observations, we propose a denoising algorithm that maximizes the innate denoising capability of INRs by penalizing the growth of deeper layer weights. We show that our method outperforms existing zero-shot denoising methods under an extensive set of low-noise or real-noise scenarios.
Scaling Neural Tangent Kernels via Sketching and Random Features
Jun 15, 2021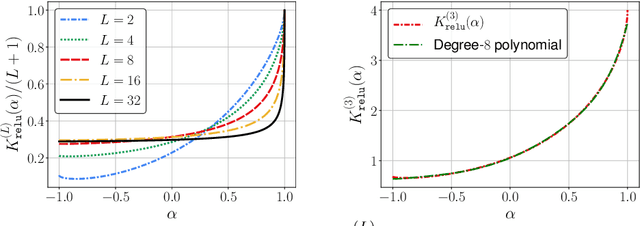

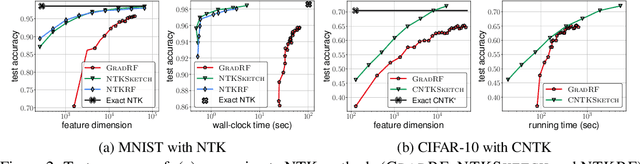
The Neural Tangent Kernel (NTK) characterizes the behavior of infinitely-wide neural networks trained under least squares loss by gradient descent. Recent works also report that NTK regression can outperform finitely-wide neural networks trained on small-scale datasets. However, the computational complexity of kernel methods has limited its use in large-scale learning tasks. To accelerate learning with NTK, we design a near input-sparsity time approximation algorithm for NTK, by sketching the polynomial expansions of arc-cosine kernels: our sketch for the convolutional counterpart of NTK (CNTK) can transform any image using a linear runtime in the number of pixels. Furthermore, we prove a spectral approximation guarantee for the NTK matrix, by combining random features (based on leverage score sampling) of the arc-cosine kernels with a sketching algorithm. We benchmark our methods on various large-scale regression and classification tasks and show that a linear regressor trained on our CNTK features matches the accuracy of exact CNTK on CIFAR-10 dataset while achieving 150x speedup.
Random Features for the Neural Tangent Kernel
Apr 03, 2021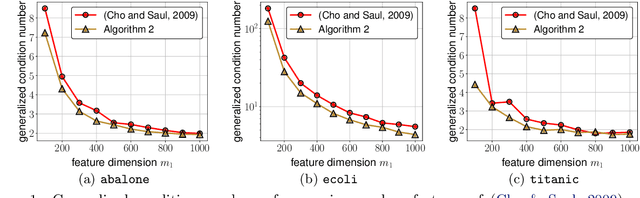
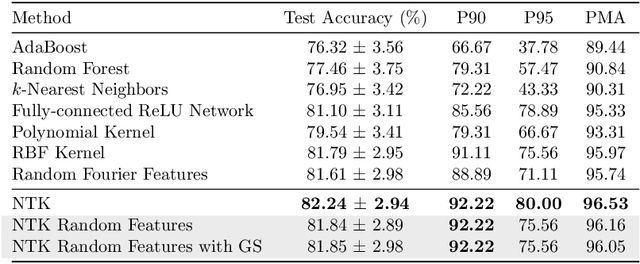
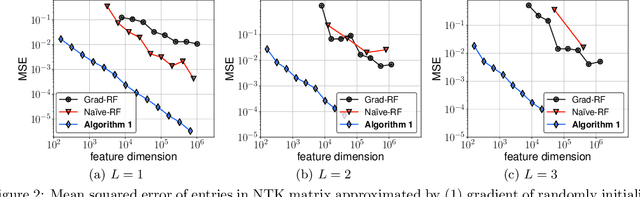
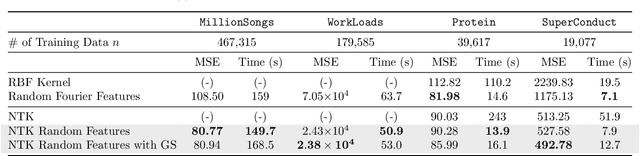
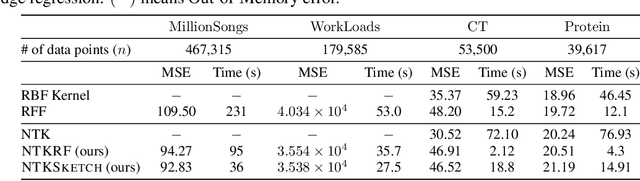
The Neural Tangent Kernel (NTK) has discovered connections between deep neural networks and kernel methods with insights of optimization and generalization. Motivated by this, recent works report that NTK can achieve better performances compared to training neural networks on small-scale datasets. However, results under large-scale settings are hardly studied due to the computational limitation of kernel methods. In this work, we propose an efficient feature map construction of the NTK of fully-connected ReLU network which enables us to apply it to large-scale datasets. We combine random features of the arc-cosine kernels with a sketching-based algorithm which can run in linear with respect to both the number of data points and input dimension. We show that dimension of the resulting features is much smaller than other baseline feature map constructions to achieve comparable error bounds both in theory and practice. We additionally utilize the leverage score based sampling for improved bounds of arc-cosine random features and prove a spectral approximation guarantee of the proposed feature map to the NTK matrix of two-layer neural network. We benchmark a variety of machine learning tasks to demonstrate the superiority of the proposed scheme. In particular, our algorithm can run tens of magnitude faster than the exact kernel methods for large-scale settings without performance loss.