 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Features for the Neural Tangent Kernel
Paper and Code
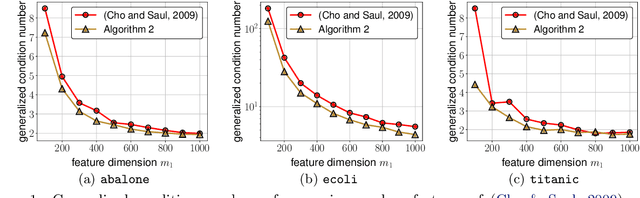
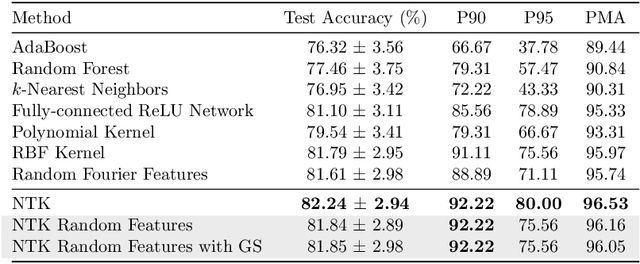
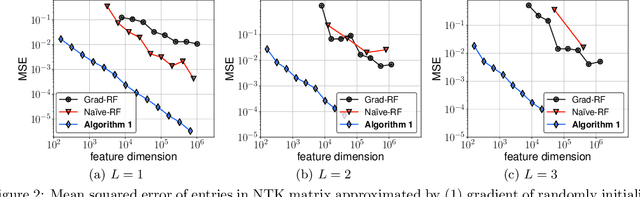
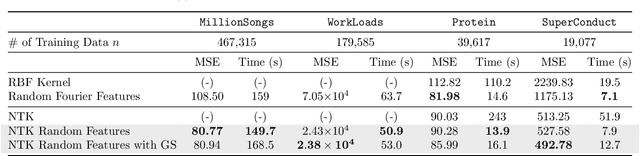
The Neural Tangent Kernel (NTK) has discovered connections between deep neural networks and kernel methods with insights of optimization and generalization. Motivated by this, recent works report that NTK can achieve better performances compared to training neural networks on small-scale datasets. However, results under large-scale settings are hardly studied due to the computational limitation of kernel methods. In this work, we propose an efficient feature map construction of the NTK of fully-connected ReLU network which enables us to apply it to large-scale datasets. We combine random features of the arc-cosine kernels with a sketching-based algorithm which can run in linear with respect to both the number of data points and input dimension. We show that dimension of the resulting features is much smaller than other baseline feature map constructions to achieve comparable error bounds both in theory and practice. We additionally utilize the leverage score based sampling for improved bounds of arc-cosine random features and prove a spectral approximation guarantee of the proposed feature map to the NTK matrix of two-layer neural network. We benchmark a variety of machine learning tasks to demonstrate the superiority of the proposed scheme. In particular, our algorithm can run tens of magnitude faster than the exact kernel methods for large-scale settings without performance loss.