 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen the City Teaches the Car: Label-Free 3D Perception from Infrastructure
Mar 17, 2026Building robust 3D perception for self-driving still relies heavily on large-scale data collection and manual annotation, yet this paradigm becomes impractical as deployment expands across diverse cities and regions. Meanwhile, modern cities are increasingly instrumented with roadside units (RSUs), static sensors deployed along roads and at intersections to monitor traffic. This raises a natural question: can the city itself help train the vehicle? We propose infrastructure-taught, label-free 3D perception, a paradigm in which RSUs act as stationary, unsupervised teachers for ego vehicles. Leveraging their fixed viewpoints and repeated observations, RSUs learn local 3D detectors from unlabeled data and broadcast predictions to passing vehicles, which are aggregated as pseudo-label supervision for training a standalone ego detector. The resulting model requires no infrastructure or communication at test time. We instantiate this idea as a fully label-free three-stage pipeline and conduct a concept-and-feasibility study in a CARLA-based multi-agent environment. With CenterPoint, our pipeline achieves 82.3% AP for detecting vehicles, compared to a fully supervised ego upper bound of 94.4%. We further systematically analyze each stage, evaluate its scalability, and demonstrate complementarity with existing ego-centric label-free methods. Together, these results suggest that city infrastructure itself can potentially provide a scalable supervisory signal for autonomous vehicles, positioning infrastructure-taught learning as a promising orthogonal paradigm for reducing annotation cost in 3D perception.
On the Feasibility and Opportunity of Autoregressive 3D Object Detection
Mar 09, 2026LiDAR-based 3D object detectors typically rely on proposal heads with hand-crafted components like anchor assignment and non-maximum suppression (NMS), complicating training and limiting extensibility. We present AutoReg3D, an autoregressive 3D detector that casts detection as sequence generation. Given point-cloud features, AutoReg3D emits objects in a range-causal (near-to-far) order and encodes each object as a short, discrete-token sequence consisting of its center, size, orientation, velocity, and class. This near-to-far ordering mirrors LiDAR geometry--near objects occlude far ones but not vice versa--enabling straightforward teacher forcing during training and autoregressive decoding at test time. AutoReg3D is compatible across diverse point-cloud or backbones and attains competitive nuScenes performance without anchors or NMS. Beyond parity, the sequential formulation unlocks language-model advances for 3D perception, including GRPO-style reinforcement learning for task-aligned objectives. These results position autoregressive decoding as a viable, flexible alternative for LiDAR-based detection and open a path to importing modern sequence-modeling tools into 3D perception.
Continual Unlearning for Text-to-Image Diffusion Models: A Regularization Perspective
Nov 11, 2025Machine unlearning--the ability to remove designated concepts from a pre-trained model--has advanced rapidly, particularly for text-to-image diffusion models. However, existing methods typically assume that unlearning requests arrive all at once, whereas in practice they often arrive sequentially. We present the first systematic study of continual unlearning in text-to-image diffusion models and show that popular unlearning methods suffer from rapid utility collapse: after only a few requests, models forget retained knowledge and generate degraded images. We trace this failure to cumulative parameter drift from the pre-training weights and argue that regularization is crucial to addressing it. To this end, we study a suite of add-on regularizers that (1) mitigate drift and (2) remain compatible with existing unlearning methods. Beyond generic regularizers, we show that semantic awareness is essential for preserving concepts close to the unlearning target, and propose a gradient-projection method that constrains parameter drift orthogonal to their subspace. This substantially improves continual unlearning performance and is complementary to other regularizers for further gains. Taken together, our study establishes continual unlearning as a fundamental challenge in text-to-image generation and provides insights, baselines, and open directions for advancing safe and accountable generative AI.
Transfer Your Perspective: Controllable 3D Generation from Any Viewpoint in a Driving Scene
Feb 10, 2025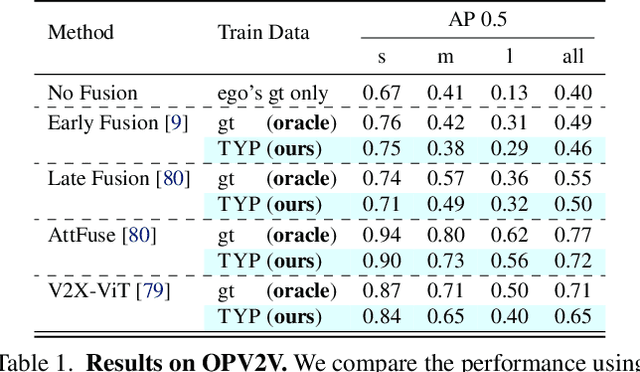
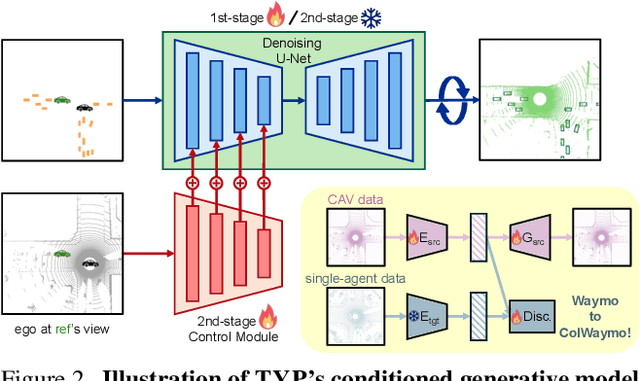
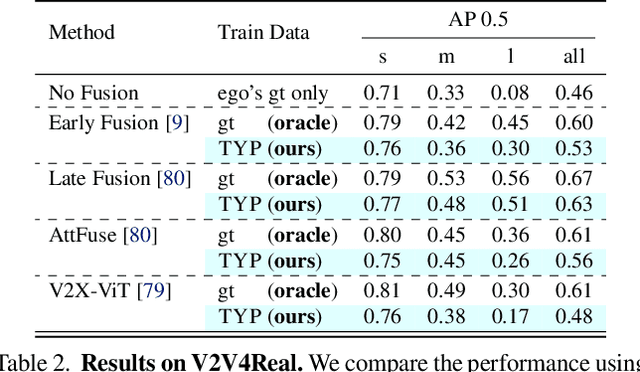

Self-driving cars relying solely on ego-centric perception face limitations in sensing, often failing to detect occluded, faraway objects. Collaborative autonomous driving (CAV) seems like a promising direction, but collecting data for development is non-trivial. It requires placing multiple sensor-equipped agents in a real-world driving scene, simultaneously! As such, existing datasets are limited in locations and agents. We introduce a novel surrogate to the rescue, which is to generate realistic perception from different viewpoints in a driving scene, conditioned on a real-world sample - the ego-car's sensory data. This surrogate has huge potential: it could potentially turn any ego-car dataset into a collaborative driving one to scale up the development of CAV. We present the very first solution, using a combination of simulated collaborative data and real ego-car data. Our method, Transfer Your Perspective (TYP), learns a conditioned diffusion model whose output samples are not only realistic but also consistent in both semantics and layouts with the given ego-car data. Empirical results demonstrate TYP's effectiveness in aiding in a CAV setting. In particular, TYP enables us to (pre-)train collaborative perception algorithms like early and late fusion with little or no real-world collaborative data, greatly facilitating downstream CAV applications.
Static Segmentation by Tracking: A Frustratingly Label-Efficient Approach to Fine-Grained Segmentation
Jan 12, 2025



We study image segmentation in the biological domain, particularly trait and part segmentation from specimen images (e.g., butterfly wing stripes or beetle body parts). This is a crucial, fine-grained task that aids in understanding the biology of organisms. The conventional approach involves hand-labeling masks, often for hundreds of images per species, and training a segmentation model to generalize these labels to other images, which can be exceedingly laborious. We present a label-efficient method named Static Segmentation by Tracking (SST). SST is built upon the insight: while specimens of the same species have inherent variations, the traits and parts we aim to segment show up consistently. This motivates us to concatenate specimen images into a ``pseudo-video'' and reframe trait and part segmentation as a tracking problem. Concretely, SST generates masks for unlabeled images by propagating annotated or predicted masks from the ``pseudo-preceding'' images. Powered by Segment Anything Model 2 (SAM~2) initially developed for video segmentation, we show that SST can achieve high-quality trait and part segmentation with merely one labeled image per species -- a breakthrough for analyzing specimen images. We further develop a cycle-consistent loss to fine-tune the model, again using one labeled image. Additionally, we highlight the broader potential of SST, including one-shot instance segmentation on images taken in the wild and trait-based image retrieval.
Learning 3D Perception from Others' Predictions
Oct 03, 2024



Accurate 3D object detection in real-world environments requires a huge amount of annotated data with high quality. Acquiring such data is tedious and expensive, and often needs repeated effort when a new sensor is adopted or when the detector is deployed in a new environment. We investigate a new scenario to construct 3D object detectors: learning from the predictions of a nearby unit that is equipped with an accurate detector. For example, when a self-driving car enters a new area, it may learn from other traffic participants whose detectors have been optimized for that area. This setting is label-efficient, sensor-agnostic, and communication-efficient: nearby units only need to share the predictions with the ego agent (e.g., car). Naively using the received predictions as ground-truths to train the detector for the ego car, however, leads to inferior performance. We systematically study the problem and identify viewpoint mismatches and mislocalization (due to synchronization and GPS errors) as the main causes, which unavoidably result in false positives, false negatives, and inaccurate pseudo labels. We propose a distance-based curriculum, first learning from closer units with similar viewpoints and subsequently improving the quality of other units' predictions via self-training. We further demonstrate that an effective pseudo label refinement module can be trained with a handful of annotated data, largely reducing the data quantity necessary to train an object detector. We validate our approach on the recently released real-world collaborative driving dataset, using reference cars' predictions as pseudo labels for the ego car. Extensive experiments including several scenarios (e.g., different sensors, detectors, and domains) demonstrate the effectiveness of our approach toward label-efficient learning of 3D perception from other units' predictions.
Rich CNN-Transformer Feature Aggregation Networks for Super-Resolution
Mar 16, 2022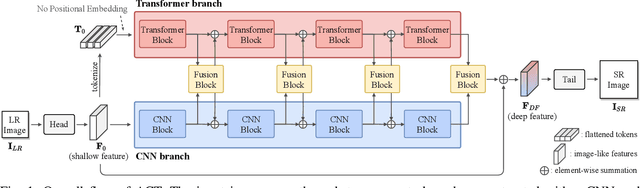


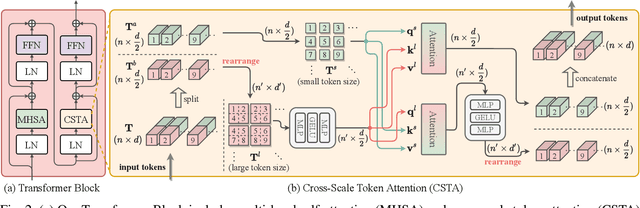
Recent vision transformers along with self-attention have achieved promising results on various computer vision tasks. In particular, a pure transformer-based image restoration architecture surpasses the existing CNN-based methods using multi-task pre-training with a large number of trainable parameters. In this paper, we introduce an effective hybrid architecture for super-resolution (SR) tasks, which leverages local features from CNNs and long-range dependencies captured by transformers to further improve the SR results. Specifically, our architecture comprises of transformer and convolution branches, and we substantially elevate the performance by mutually fusing two branches to complement each representation. Furthermore, we propose a cross-scale token attention module, which allows the transformer to efficiently exploit the informative relationships among tokens across different scales. Our proposed method achieves state-of-the-art SR results on numerous benchmark datasets.
Self-Supervised Adaptation for Video Super-Resolution
Mar 18, 2021
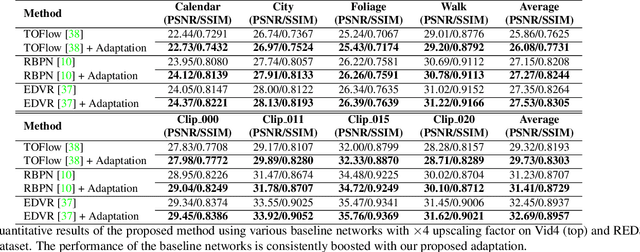
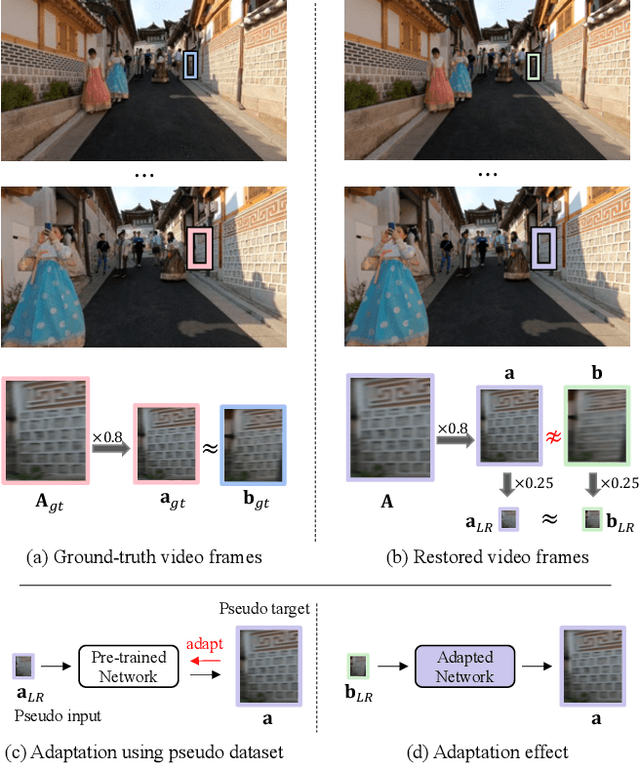
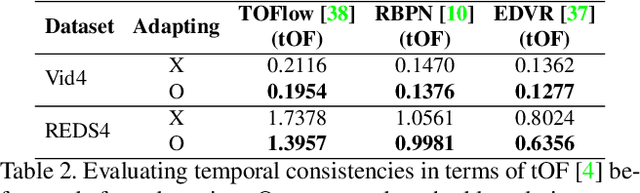
Recent single-image super-resolution (SISR) networks, which can adapt their network parameters to specific input images, have shown promising results by exploiting the information available within the input data as well as large external datasets. However, the extension of these self-supervised SISR approaches to video handling has yet to be studied. Thus, we present a new learning algorithm that allows conventional video super-resolution (VSR) networks to adapt their parameters to test video frames without using the ground-truth datasets. By utilizing many self-similar patches across space and time, we improve the performance of fully pre-trained VSR networks and produce temporally consistent video frames. Moreover, we present a test-time knowledge distillation technique that accelerates the adaptation speed with less hardware resources. In our experiments, we demonstrate that our novel learning algorithm can fine-tune state-of-the-art VSR networks and substantially elevate performance on numerous benchmark datasets.
Fast Adaptation to Super-Resolution Networks via Meta-Learning
Jan 14, 2020
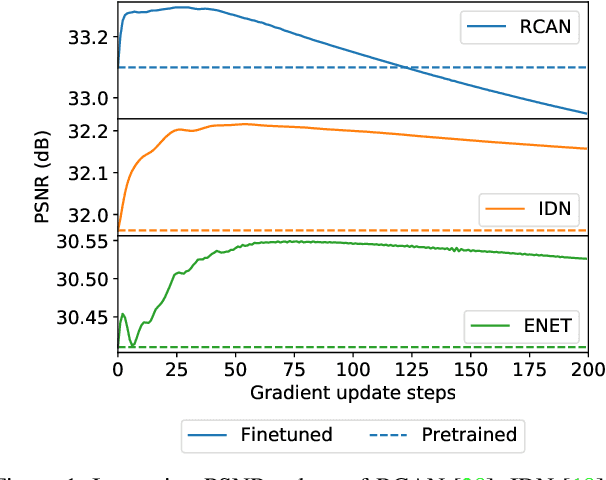
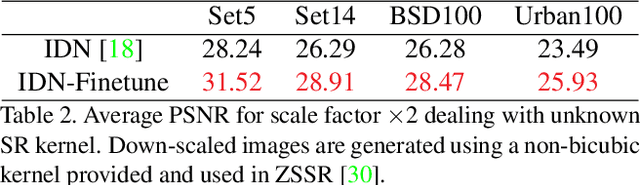
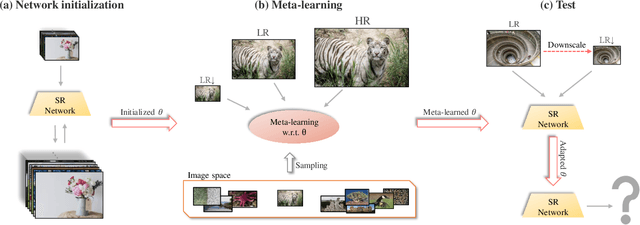
Conventional supervised super-resolution (SR) approaches are trained with massive external SR datasets but fail to exploit desirable properties of the given test image. On the other hand, self-supervised SR approaches utilize the internal information within a test image but suffer from computational complexity in run-time. In this work, we observe the opportunity for further improvement of the performance of SISR without changing the architecture of conventional SR networks by practically exploiting additional information given from the input image. In the training stage, we train the network via meta-learning; thus, the network can quickly adapt to any input image at test time. Then, in the test stage, parameters of this meta-learned network are rapidly fine-tuned with only a few iterations by only using the given low-resolution image. The adaptation at the test time takes full advantage of patch-recurrence property observed in natural images. Our method effectively handles unknown SR kernels and can be applied to any existing model. We demonstrate that the proposed model-agnostic approach consistently improves the performance of conventional SR networks on various benchmark SR datasets.