 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Adaptation for Video Super-Resolution
Paper and Code

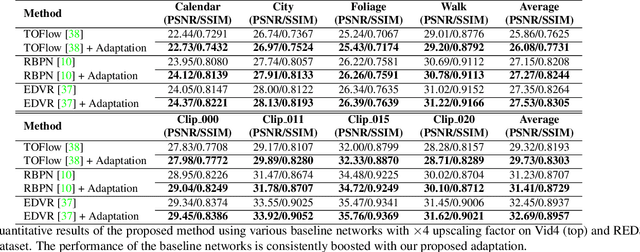
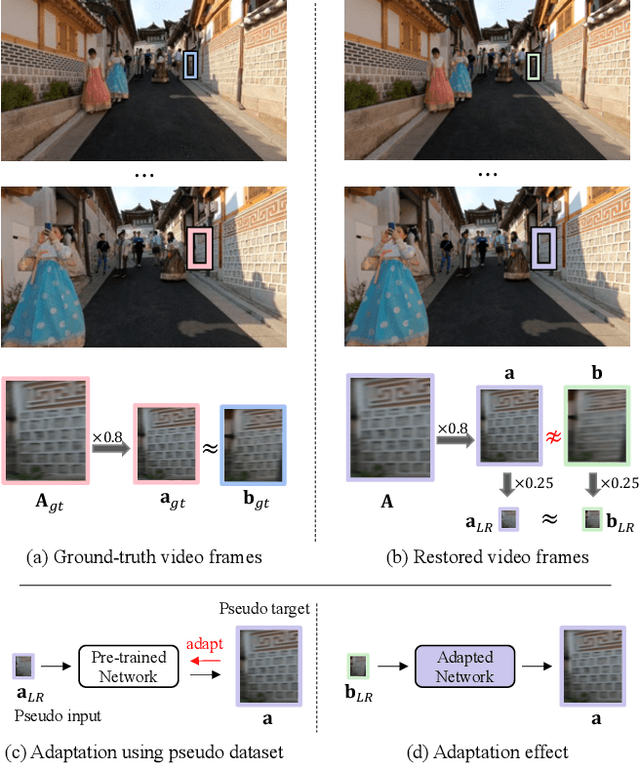
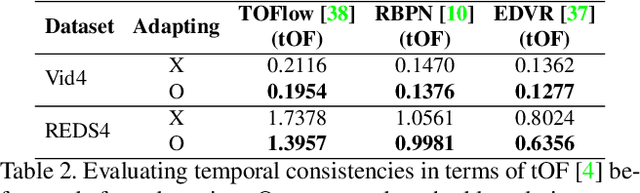
Recent single-image super-resolution (SISR) networks, which can adapt their network parameters to specific input images, have shown promising results by exploiting the information available within the input data as well as large external datasets. However, the extension of these self-supervised SISR approaches to video handling has yet to be studied. Thus, we present a new learning algorithm that allows conventional video super-resolution (VSR) networks to adapt their parameters to test video frames without using the ground-truth datasets. By utilizing many self-similar patches across space and time, we improve the performance of fully pre-trained VSR networks and produce temporally consistent video frames. Moreover, we present a test-time knowledge distillation technique that accelerates the adaptation speed with less hardware resources. In our experiments, we demonstrate that our novel learning algorithm can fine-tune state-of-the-art VSR networks and substantially elevate performance on numerous benchmark datasets.