 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Interactive Training for Video Segmentation
Mar 27, 2026Interactive video segmentation often requires many user interventions for robust performance in challenging scenarios (e.g., occlusions, object separations, camouflage, etc.). Yet, even state-of-the-art models like SAM2 use corrections only for immediate fixes without learning from this feedback, leading to inefficient, repetitive user effort. To address this, we introduce Live Interactive Training (LIT), a novel framework for prompt-based visual systems where models also learn online from human corrections at inference time. Our primary instantiation, LIT-LoRA, implements this by continually updating a lightweight LoRA module on-the-fly. When a user provides a correction, this module is rapidly trained on that feedback, allowing the vision system to improve performance on subsequent frames of the same video. Leveraging the core principles of LIT, our LIT-LoRA implementation achieves an average 18-34% reduction in total corrections on challenging video segmentation benchmarks, with a negligible training overhead of ~0.5s per correction. We further demonstrate its generality by successfully adapting it to other segmentation models and extending it to CLIP-based fine-grained image classification. Our work highlights the promise of live adaptation to transform interactive tools and significantly reduce redundant human effort in complex visual tasks. Project: https://youngxinyu1802.github.io/projects/LIT/.
Tracking and Understanding Object Transformations
Nov 06, 2025Real-world objects frequently undergo state transformations. From an apple being cut into pieces to a butterfly emerging from its cocoon, tracking through these changes is important for understanding real-world objects and dynamics. However, existing methods often lose track of the target object after transformation, due to significant changes in object appearance. To address this limitation, we introduce the task of Track Any State: tracking objects through transformations while detecting and describing state changes, accompanied by a new benchmark dataset, VOST-TAS. To tackle this problem, we present TubeletGraph, a zero-shot system that recovers missing objects after transformation and maps out how object states are evolving over time. TubeletGraph first identifies potentially overlooked tracks, and determines whether they should be integrated based on semantic and proximity priors. Then, it reasons about the added tracks and generates a state graph describing each observed transformation. TubeletGraph achieves state-of-the-art tracking performance under transformations, while demonstrating deeper understanding of object transformations and promising capabilities in temporal grounding and semantic reasoning for complex object transformations. Code, additional results, and the benchmark dataset are available at https://tubelet-graph.github.io.
Video Creation by Demonstration
Dec 12, 2024



We explore a novel video creation experience, namely Video Creation by Demonstration. Given a demonstration video and a context image from a different scene, we generate a physically plausible video that continues naturally from the context image and carries out the action concepts from the demonstration. To enable this capability, we present $\delta$-Diffusion, a self-supervised training approach that learns from unlabeled videos by conditional future frame prediction. Unlike most existing video generation controls that are based on explicit signals, we adopts the form of implicit latent control for maximal flexibility and expressiveness required by general videos. By leveraging a video foundation model with an appearance bottleneck design on top, we extract action latents from demonstration videos for conditioning the generation process with minimal appearance leakage. Empirically, $\delta$-Diffusion outperforms related baselines in terms of both human preference and large-scale machine evaluations, and demonstrates potentials towards interactive world simulation. Sampled video generation results are available at https://delta-diffusion.github.io/.
Learning 3D Perception from Others' Predictions
Oct 03, 2024



Accurate 3D object detection in real-world environments requires a huge amount of annotated data with high quality. Acquiring such data is tedious and expensive, and often needs repeated effort when a new sensor is adopted or when the detector is deployed in a new environment. We investigate a new scenario to construct 3D object detectors: learning from the predictions of a nearby unit that is equipped with an accurate detector. For example, when a self-driving car enters a new area, it may learn from other traffic participants whose detectors have been optimized for that area. This setting is label-efficient, sensor-agnostic, and communication-efficient: nearby units only need to share the predictions with the ego agent (e.g., car). Naively using the received predictions as ground-truths to train the detector for the ego car, however, leads to inferior performance. We systematically study the problem and identify viewpoint mismatches and mislocalization (due to synchronization and GPS errors) as the main causes, which unavoidably result in false positives, false negatives, and inaccurate pseudo labels. We propose a distance-based curriculum, first learning from closer units with similar viewpoints and subsequently improving the quality of other units' predictions via self-training. We further demonstrate that an effective pseudo label refinement module can be trained with a handful of annotated data, largely reducing the data quantity necessary to train an object detector. We validate our approach on the recently released real-world collaborative driving dataset, using reference cars' predictions as pseudo labels for the ego car. Extensive experiments including several scenarios (e.g., different sensors, detectors, and domains) demonstrate the effectiveness of our approach toward label-efficient learning of 3D perception from other units' predictions.
Learning to Detect and Segment Mobile Objects from Unlabeled Videos
May 23, 2024Embodied agents must detect and localize objects of interest, e.g. traffic participants for self-driving cars. Supervision in the form of bounding boxes for this task is extremely expensive. As such, prior work has looked at unsupervised object segmentation, but in the absence of annotated boxes, it is unclear how pixels must be grouped into objects and which objects are of interest. This results in over- / under-segmentation and irrelevant objects. Inspired both by the human visual system and by practical applications, we posit that the key missing cue is motion: objects of interest are typically mobile objects. We propose MOD-UV, a Mobile Object Detector learned from Unlabeled Videos only. We begin with pseudo-labels derived from motion segmentation, but introduce a novel training paradigm to progressively discover small objects and static-but-mobile objects that are missed by motion segmentation. As a result, though only learned from unlabeled videos, MOD-UV can detect and segment mobile objects from a single static image. Empirically, we achieve state-of-the-art performance in unsupervised mobile object detection on Waymo Open, nuScenes, and KITTI Dataset without using any external data or supervised models. Code is publicly available at https://github.com/YihongSun/MOD-UV.
Dynamo-Depth: Fixing Unsupervised Depth Estimation for Dynamical Scenes
Oct 29, 2023Unsupervised monocular depth estimation techniques have demonstrated encouraging results but typically assume that the scene is static. These techniques suffer when trained on dynamical scenes, where apparent object motion can equally be explained by hypothesizing the object's independent motion, or by altering its depth. This ambiguity causes depth estimators to predict erroneous depth for moving objects. To resolve this issue, we introduce Dynamo-Depth, an unifying approach that disambiguates dynamical motion by jointly learning monocular depth, 3D independent flow field, and motion segmentation from unlabeled monocular videos. Specifically, we offer our key insight that a good initial estimation of motion segmentation is sufficient for jointly learning depth and independent motion despite the fundamental underlying ambiguity. Our proposed method achieves state-of-the-art performance on monocular depth estimation on Waymo Open and nuScenes Dataset with significant improvement in the depth of moving objects. Code and additional results are available at https://dynamo-depth.github.io.
Robust Instance Segmentation through Reasoning about Multi-Object Occlusion
Dec 03, 2020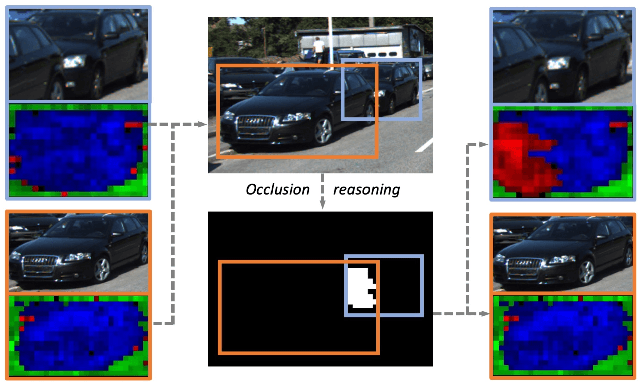
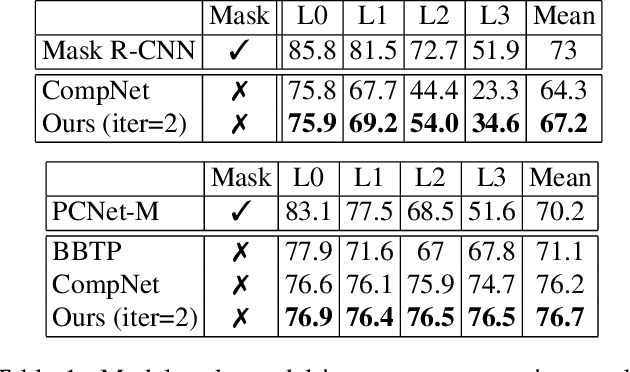
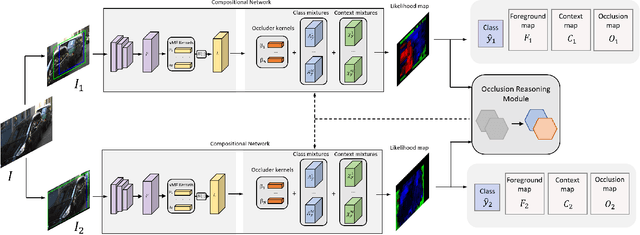
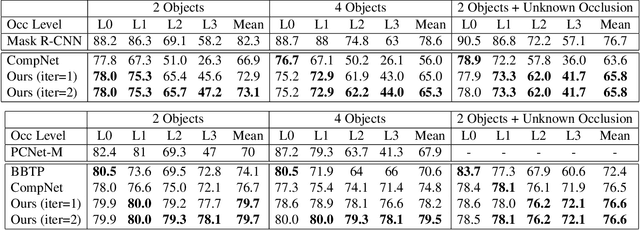
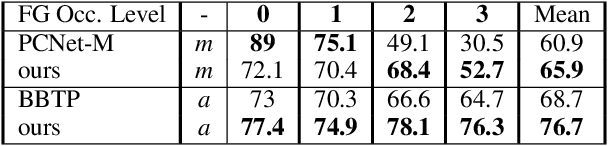
Analyzing complex scenes with Deep Neural Networks is a challenging task, particularly when images contain multiple objects that partially occlude each other. Existing approaches to image analysis mostly process objects independently and do not take into account the relative occlusion of nearby objects. In this paper, we propose a deep network for multi-object instance segmentation that is robust to occlusion and can be trained from bounding box supervision only. Our work builds on Compositional Networks, which learn a generative model of neural feature activations to locate occluders and to classify objects based on their non-occluded parts. We extend their generative model to include multiple objects and introduce a framework for the efficient inference in challenging occlusion scenarios. In particular, we obtain feed-forward predictions of the object classes and their instance and occluder segmentations. We introduce an Occlusion Reasoning Module (ORM) that locates erroneous segmentations and estimates the occlusion ordering to correct them. The improved segmentation masks are, in turn, integrated into the network in a top-down manner to improve the image classification. Our experiments on the KITTI INStance dataset (KINS) and a synthetic occlusion dataset demonstrate the effectiveness and robustness of our model at multi-object instance segmentation under occlusion.
Weakly-Supervised Amodal Instance Segmentation with Compositional Priors
Oct 25, 2020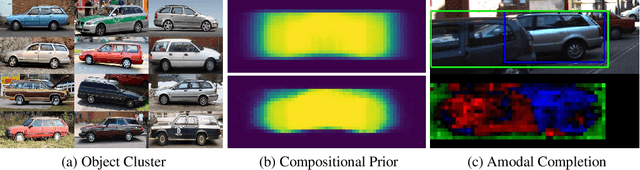


Amodal segmentation in biological vision refers to the perception of the entire object when only a fraction is visible. This ability of seeing through occluders and reasoning about occlusion is innate to biological vision but not adequately modeled in current machine vision approaches. A key challenge is that ground-truth supervisions of amodal object segmentation are inherently difficult to obtain. In this paper, we present a neural network architecture that is capable of amodal perception, when weakly supervised with standard (inmodal) bounding box annotations. Our model extends compositional convolutional neural networks (CompositionalNets), which have been shown to be robust to partial occlusion by explicitly representing objects as composition of parts. In particular, we extend CompositionalNets by: 1) Expanding the innate part-voting mechanism in the CompositionalNets to perform instance segmentation; 2) and by exploiting the internal representations of CompositionalNets to enable amodal completion for both bounding box and segmentation mask. Our extensive experiments show that our proposed model can segment amodal masks robustly, with much improved mask prediction qualities compared to state-of-the-art amodal segmentation approaches.
Compositional Convolutional Neural Networks: A Robust and Interpretable Model for Object Recognition under Occlusion
Jun 28, 2020Computer vision systems in real-world applications need to be robust to partial occlusion while also being explainable. In this work, we show that black-box deep convolutional neural networks (DCNNs) have only limited robustness to partial occlusion. We overcome these limitations by unifying DCNNs with part-based models into Compositional Convolutional Neural Networks (CompositionalNets) - an interpretable deep architecture with innate robustness to partial occlusion. Specifically, we propose to replace the fully connected classification head of DCNNs with a differentiable compositional model that can be trained end-to-end. The structure of the compositional model enables CompositionalNets to decompose images into objects and context, as well as to further decompose object representations in terms of individual parts and the objects' pose. The generative nature of our compositional model enables it to localize occluders and to recognize objects based on their non-occluded parts. We conduct extensive experiments in terms of image classification and object detection on images of artificially occluded objects from the PASCAL3D+ and ImageNet dataset, and real images of partially occluded vehicles from the MS-COCO dataset. Our experiments show that CompositionalNets made from several popular DCNN backbones (VGG-16, ResNet50, ResNext) improve by a large margin over their non-compositional counterparts at classifying and detecting partially occluded objects. Furthermore, they can localize occluders accurately despite being trained with class-level supervision only. Finally, we demonstrate that CompositionalNets provide human interpretable predictions as their individual components can be understood as detecting parts and estimating an objects' viewpoint.
Robust Object Detection under Occlusion with Context-Aware CompositionalNets
May 30, 2020
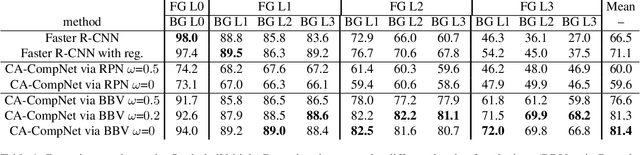

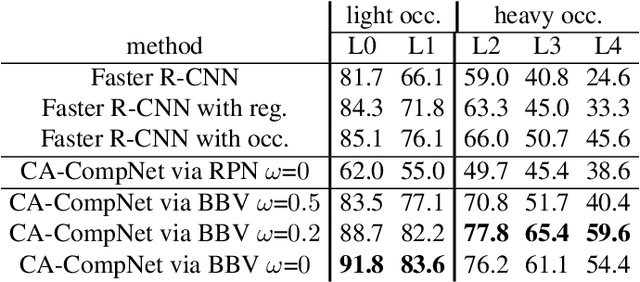
Detecting partially occluded objects is a difficult task. Our experimental results show that deep learning approaches, such as Faster R-CNN, are not robust at object detection under occlusion. Compositional convolutional neural networks (CompositionalNets) have been shown to be robust at classifying occluded objects by explicitly representing the object as a composition of parts. In this work, we propose to overcome two limitations of CompositionalNets which will enable them to detect partially occluded objects: 1) CompositionalNets, as well as other DCNN architectures, do not explicitly separate the representation of the context from the object itself. Under strong object occlusion, the influence of the context is amplified which can have severe negative effects for detection at test time. In order to overcome this, we propose to segment the context during training via bounding box annotations. We then use the segmentation to learn a context-aware CompositionalNet that disentangles the representation of the context and the object. 2) We extend the part-based voting scheme in CompositionalNets to vote for the corners of the object's bounding box, which enables the model to reliably estimate bounding boxes for partially occluded objects. Our extensive experiments show that our proposed model can detect objects robustly, increasing the detection performance of strongly occluded vehicles from PASCAL3D+ and MS-COCO by 41% and 35% respectively in absolute performance relative to Faster R-CNN.